


Nähe und Distanz
In einer Studie wurde untersucht, wie nah man sich in einem Videomeeting vor den Bildschirm setzen sollte und welche Distanz gut ankommt. Dazu sahen Menschen Begrüßungen und Einführungen zu verschiedenen Online-Workshops. Es scheint auch in Videomeetings, ähnlich wie in realen Face-to-Face-Situationen, proxemische Zonen zu geben, die unterschiedliche Empfindungen hervorrufen.
Wirkung des Bildschirmabstandes in Videomeetings
von Kerstin H. Kipp, Orlando Schenk, Jule Hölzgen & Ramon Schmid
Schlüsselwörter
Bildschirmdistanz, Kameraabstand, Videomeetings, computervermittelte Kommunikation, Proxemik
Zusammenfassung
Nimmt man an einem Videomeeting teil, stellt sich oft die Frage, wie nah man sich vor den Bildschirm setzen sollte und welcher Bildausschnitt gut ankommt. Genau diese Frage untersuchten wir im Rahmen von simulierten Online-Workshops.
An der Studie nahmen 50 Personen teil. Sie sahen Begrüßungen und thematische Einführungen zu verschiedenen Online-Workshops auf einem der Zoom-Benutzeroberfläche nachempfundenen Bildschirm. Die Workshopleitungen waren in vier verschiedenen Distanzen zum Bildschirm zu sehen (100 cm, 75 cm, 50 cm und 35 cm). Nach dem Anschauen einer Workshopeinführung gaben die Teilnehmenden auf einem Fragebogen an, wie gut für sie Form und Inhalt passten, wie angenehm die Begrüßung für sie war, wie gut sie dem Gesagten folgen konnten und wie vertraut, glaubwürdig, kompetent und sympathisch die Workshopleitung empfunden wurde.
Die Ergebnisse zeigten, dass alle Distanzen positiv wahrgenommen wurden. Es gab dennoch Unterschiede: Menschen mit wenig Erfahrung in Videomeetings bevorzugten die entferntere Distanz von 100 cm. Bei Menschen mit mittlerer Erfahrung kamen die mittleren Distanzen 50 cm und 75 cm am besten an. Für Menschen mit viel Erfahrung war die Distanz irrelevant.
Es scheint in der Videokommunikation, ähnlich wie in realen Face-to-Face-Situationen, proxemische Zonen zu geben, die unterschiedliche Empfindungen hervorrufen. Für die Frage, wie nah man sich in Videomeetings vor den Bildschirm setzen soll, lässt sich aus den Ergebnissen ableiten, dass man mit den mittleren Distanzen (50 cm und 75 cm) bei den meisten Menschen einen positiven Eindruck hinterlässt.
Keywords
screen distance, camera distance, video meetings, computer-mediated communication, proxemics
Abstract
When participating in video meetings, we often ask ourselves how close we should position ourselves to the screen in order to find a visual frame that is both appropriate for the situation and helps build rapport. To address this question, we conducted research on the use of video meetings in the context of simulated online workshops.
A total of 50 indivduals took part in our study. They watched welcome speeches and short thematic introductions to different online workshops on a screen resembling a „Zoom-style“ user interface. The workshop presenters were displayed at varying distances from the screen, at 100 cm, 75 cm, 50 cm, and 35 cm, respectively. After viewing one of the various workshop introductions the participants were required to complete a questionnaire, where they were asked how well the form suited the content, how pleasant the welcome speech was for them, how easily they could follow the content, and about the believability, competence and agreeableness of the workshop presenter.
The results demonstrate that all distances were perceived positively. There were nonetheless some variations: individuals with little experience of video meetings preferred the greater distance of 100 cm. Conversely, those with a moderate amount of video meeting experience found the middle distances (50 cm and 75 cm) to be most agreeable, while for individuals with a large amount of video meeting experience the distance was irrelevant.
It seems to be the case in video communication, as in face-to-face communication, that proxemic zones exist which have an influence on communication and provoke differing reactions. Therefore, when we ask ourselves how far away from the screen we should position ourselves in video meetings, the results of our study suggest that the middle distances used (50 cm and 75 cm) seem to make the most positive impression on the majority of people.
1. Einleitung
Videomeetings sind allgegenwärtig. Sie überbrücken räumliche Distanzen und ermöglichen computervermittelt Face-to-Face-Kommunikation. Fraglich ist jedoch, inwiefern auch die soziale Distanz überwunden werden kann (Bradner & Mark, 2002) und ein Gefühl von Nähe und persönlichem Kontakt entstehen kann. Eine Dimension, die bei dem Begriff „Nähe“ sofort in den Sinn kommt, ist die Proxemik, also die räumliche Konstellation der Kommunikationspartner. Hierzu gehört auch die räumliche Distanz. Die vorliegende Studie untersucht die Wirkung verschiedener Distanzen zum Bildschirm in Videomeetings.
1.1 Distanzen und proxemische Zonen
Proxemik ist ein fundamentaler Teil der nonverbalen Kommunikation. Selbst kleine Veränderungen in der zwischenmenschlichen Positionierung sind reich an Informationen, mit deren Hilfe Menschen ihr kommunikatives Verhalten regulieren. Beispielsweise kann eine größere Nähe zu verstärkt interaktivem Verhalten führen (Grayson, 2000). Auch der Eindruck, den man von einer Person in einem Gespräch gewinnt, hängt von der physikalischen Distanz zwischen den Personen ab. Schon 1970 wiesen Patterson und Sechrest einen negativen Zusammenhang zwischen der Distanz und der Wahrnehmung von Freundlichkeit, Aggressivität, Extraversion und Dominanz nach.
Der Begriff der Proxemik wurde in den 1960er-Jahren von Edward T. Hall eingeführt (siehe Ahmadpour et al., 2014; Gomboc-Turyan & Tourtellotte, 2010). Hall verwendete qualitative, nicht-experimentelle Interviews und entwickelte hieraus ein Konzept mit vier verschiedenen proxemischen Zonen, die zeigen, wie Menschen den Raum um sich herum nutzen und interpretieren (siehe z. B. 1966): (1) Die intime Zone umfasst den engsten physischen Kontakt mit Personen, wie enge Freunde oder Familienmitglieder (Hautkontakt bis 45 cm). (2) Die persönliche Zone ist für normale zwischenmenschliche Interaktionen wie Gespräche mit Freunden oder Arbeitskollegen reserviert (45 cm bis ca. 1,2 m). (3) Die soziale Zone erfordert eine größere Distanz (1,2 m bis 3,7 m) und ist typisch für formelle Situationen wie Gespräche in Behörden oder Unterrichtssituationen. (4) Die öffentliche Zone umfasst die größte Distanz und ist für öffentliche Veranstaltungen oder Präsentationen geeignet (3,7 m und mehr). Auch wenn hier konkrete Abstände angegeben sind, so sind die Distanzen keine endgültigen Maße. Bereits Hall berichtete, dass die Distanzen beispielsweise von der jeweiligen Kultur abhängen, was mittlerweile durch zahlreiche empirische Studien nachgewiesen ist (z. B. Broszinsky-Schwabe, 2011; Hall, 1968; Watson, 2014). Laut Heilmann (2011) implizieren Halls Darstellungen, dass es sich bei den von ihm angegebenen Distanzen eher um nord-mittel-europäische und nordamerikanische Normen handelt als um südlichere oder östlichere. Jedoch bestehen selbst zwischen europäischen Ländern Unterschiede, z. B. zwischen Niederländern, Franzosen und Engländern (Remland, Jones & Brinkmann, 1991). Auch wenn die Arbeiten von Hall älter sind, werden sie bis heute als Bezugsrahmen herangezogen, egal ob es um Face-to-face-Situationen oder um virtuelle Räume geht (z. B. Fauville et al., 2022; Kim & Sung, 2024; McDonald, 2020; Probst, Rothe & Hussmann, 2021).
In der realen Welt haben wir gelernt, Distanzen bewusst oder unbewusst wahrzunehmen und sensibel damit umzugehen. Im Folgenden werden Forschungsergebnisse vorgestellt, die verdeutlichen, dass Proxemik auch bei Bildausschnitten und in computervermittelten Kommunikationssituationen eine Rolle spielt.
1.2 Distanzwahrnehmung bei Bildern
Mehrere Studien haben nachgewiesen, dass der gewählte Bildausschnitt, der die Entfernung zur dargestellten Person simuliert, zu unterschiedlichen Wahrnehmungen führt. Sowohl beim Betrachten von Fotos (Detenber & Reeves, 1996; Gerhardson, Högman & Fischer, 2015) als auch von Videoaufnahmen (Bogdanova et al., 2022) wurden Emotionen, die durch Mimik ausgedrückt wurden, bei nahen Entfernungen stärker wahrgenommen als bei entfernten (gemessen durch Pupillenweitung, Muskeltonus und Selbsteinschätzung).
Auch das Gefühl der Menschen ändert sich in Abhängigkeit der wahrgenommenen Distanz. Das haben Wilcox et al. (2006) mit stereoskopischen Darstellungen von Personen nachgewiesen, also mit Bildern, die einen räumlichen Eindruck von Tiefe vermitteln. Sie verglichen Fotografien, die mit einem Abstand von 0,5 m, 1 m und 2 m aufgenommen wurden. Je näher die Personen auf den Fotografien erschienen, umso höher war das Unbehagen, das die Studienteilnehmenden angaben.
Ob man die Distanz zu einer Person als zu nah empfindet, hängt jedoch nicht allein von der scheinbaren Distanz ab. Die Distanz interagiert auch mit der Blickrichtung. Fauville et al. (2022) zeigten
u. a., dass insbesondere Personen, die direkt in die Kamera schauten, bei naher Distanz bedrohlicher wirkten als bei größerer Distanz. Anzumerken ist, dass die Teilnehmenden nur Screenshots von Personen sahen und sich vorstellen sollten, mit diesen in einer Videokonferenz zu sitzen.
Insgesamt verdeutlichen diese Studien, dass wir bei statischen Bildern Bildausschnitte als physikalische Nähe oder Distanz interpretieren (vgl. Grayson, 2000). Schon bei Bildern reagieren wir sensibel auf die Nähe zu anderen Menschen, und eine Verletzung der interpersonalen Distanz kann zu Unbehagen führen.
1.3 Distanzwahrnehmung in Virtual-Reality-Umgebungen
Effekte unterschiedlicher Distanzen wurden auch mehrfach in Virtual-Reality-Umgebungen getestet. Sheikh et al. (2016) realisierten in 360°-Videos drei unterschiedliche Distanzen (2 m, 3 m, 4 m). Gezeigt wurden Szenen aus einem Kampftraining. Die Teilnehmenden bevorzugten die Distanz von 3 m, welche in die soziale Zone fällt, 2 m hingegen empfanden einige Teilnehmende als zu nah, sie hatten das Gefühl, dass in ihre persönliche Zone eingedrungen wurde.
In einer weiteren Virtual-Reality-Studie untersuchten Probst et al. (2021) vier Distanzen in einer virtuellen Welt, in der eine Person in einem Museum über die Ausstellung sprach. Die vier Distanzen, mit denen die Teilnehmenden konfrontiert wurden, basierten auf Halls Einteilung: intim (45 cm), persönlich (1 m), sozial (2,5 m) und öffentlich (5 m). Die Ergebnisse zeigten, dass sich die Teilnehmenden in Szenen mit intimer Distanz unwohler und gestresster fühlten und die sprechende Person aufdringlicher wirkte. Die persönliche Distanz wurde als angenehmste und natürlichste wahrgenommen, und die Teilnehmenden fühlten sich am stärksten angesprochen. Entferntere Distanzen wirkten dagegen weniger spannend.
Auch die Blickrichtung des Gegenübers ist relevant für die Empfindung verschiedener Distanzen. In einer Studie mit virtuellen Agenten nahmen Probandinnen und Probanden eine größere Distanz zu einem virtuellen Agenten ein, wenn dieser sie direkt anschaute, als wenn er nicht direkt zu ihnen sah. Zudem wichen die Probandinnen und Probanden aus, wenn ihnen der virtuelle Agent zu nahe kam und in ihre private räumliche Zone eindrang (Bailenson et al., 2001; 2003).
Diese Studien verdeutlichen, dass Proxemik auch in virtuellen Räumen kontextabhängig ist: Bei Sheikh et al. (2016) wurden Szenen aus einem Kampftraining gezeigt, und die Teilnehmenden bevorzugten eine größere Distanz. Bei Probst et al. (2021) wurden ruhige Szenen dargestellt, nämlich Erläuterungen zu einer Ausstellung. Hier favorisierten die Teilnehmenden nähere Distanzen. Welche Distanz als passend empfunden wird, hängt also auch von der jeweiligen Interaktionssituation ab.
1.4 Distanzwahrnehmung in Videomeetings
Bisher wurde selten untersucht, wie sich Proxemik in Videomeetings auswirkt. Eine Studie untersuchte unterschiedliche Distanzen in Online-Kursen (Ellis, 1992). Hierzu wurden Studierende in zwei Gruppen eingeteilt, die den Dozenten in zwei unterschiedlichen Distanzen zum Bildschirm sahen. In der nahen Distanz nahm der Dozent 51,85 % der Bildhöhe ein, in der entfernten Distanz füllte der Dozent 14,81 % der Bildhöhe aus. Die Studierenden, die den Dozenten in der näheren Distanz sahen, schnitten im späteren Erinnerungstest erfolgreicher ab, empfanden die Veranstaltung positiver und fanden den Dozenten sympathischer. Die nahe Distanz hatte also mehrere Vorteile.
Eine weitere Studie, in der Kundengespräche als Rollenspiele in echten, interaktiven Videomeetings durchgeführt wurden, zeigt Vorteile naher Distanzen (Grayson, 2000). Verglichen wurden hier zwei Distanzen: In der nahen Distanz füllte der Kopf den gesamten Bildausschnitt aus, wohingegen in der fernen Distanz der Torso zu sehen war. Die Ergebnisse zeigen, dass die unterschiedlich wahrgenommenen Abstände die Art und Weise verändern können, wie Personen miteinander interagieren: Ein näher positionierter Remote-Partner führte dazu, dass der gegenübersitzende Mensch interaktiver agierte.
Nguyen und Canny (2009) verglichen zwei unterschiedliche Bedingungen in Videomeetings. In einer sah man auf einem Bildschirm den Gesprächspartner mit seinem gesamten Oberkörper etwa in Lebensgröße, in der zweiten sah man nur den Kopf, ebenfalls in Lebensgröße, der restliche Bildschirm war schwarz. Die Probanden empfanden den Gesprächspartner als empathischer, wenn sie den ganzen Oberkörper sehen konnten. Im Gegensatz zu heutigen Videomeetings wurde hier jedoch die Sichtbarkeit des Bildes verändert und nicht die Größe des Bildausschnittes.
Auch wenn es bislang kaum Studien zur Distanz in Videomeetings gibt und die vorhandenen nicht den heutigen Bedingungen von Videomeetings entsprechen, so deuten diese Untersuchungen dennoch darauf hin, dass die Distanz zur Kamera unterschiedliche Empfindungen beim Gegenüber auslösen kann.
2. Fragestellung und Hypothesen
Wie gezeigt wurde, spielt die Distanz beim Betrachten von Bildern, Videoaufnahmen, in virtuellen Räumen und in Videomeetings eine Rolle. Wie aber verschiedene Distanzen auf die Gesprächspartnerinnen und -partner im Kontext moderner Videomeetings wirken, wurde bisher noch nicht untersucht und ist Gegenstand der vorliegenden Studie. Hierfür ließen wir Probandinnen und Probanden an simulierten Online-Workshops teilnehmen. Sie sahen Begrüßungen und thematische Einführungen zu verschiedenen Workshops auf einem der Zoom-Benutzeroberfläche nachempfundenen Bildschirm. Die Workshopleitungen waren in vier verschiedenen Distanzen zur Kamera zu sehen. Im Anschluss befragten wir die Teilnehmenden, wie sie die Situation und die Workshopleitung empfunden haben.
Wenn in Videomeetings Distanzen ähnliche Bedeutungen haben wie in realen Face-to-Face-Situationen (siehe Hall, 1966), dann müsste es auch in einem Online-Workshop Distanzen geben, die als zu nah oder zu fern erlebt werden. Da Workshops weder eine intime Situation noch eine Situation mit großer Öffentlichkeit darstellen, sollten mittlere Distanzen als angemessen erlebt werden (vgl. Probst et al., 2021). Welche konkreten Entfernungen zum Bildschirm das sind, wird in dieser Studie untersucht.
Ein weiterer relevanter Aspekt: Braun hat in ihrer Studie nachgewiesen (2004), dass Menschen, die zum ersten Mal Videokonferenzgespräche erleben, anfänglich Performanzreduktionen zeigen, dass jedoch langfristig Anpassungsprozesse stattfinden und Kommunikationsstrategien entwickelt werden, die der Situation gerecht werden. Daher vermuten wir, dass Proband*innen, die bereits umfangreiche Erfahrungen mit Videomeetings haben, besser in der Lage sind, sich an die eingeschränkten Kommunikationsmöglichkeiten in der Online-Situation anzupassen, sodass unterschiedliche Distanzen der Kommunikationspartner*innen weniger Einfluss auf die Wahrnehmung haben dürften. Diese Hypothese wird in unserer Studie ebenfalls untersucht.
3. Methodik
3.1 Stichprobe
An der Studie nahmen 50 Personen teil (37 Frauen, 10 Männer, 3 ohne Angabe). Das Alter lag zwischen 14 und 79 Jahren und war über die Spanne gleichmäßig verteilt. Eine statistische Prüfung zeigte, dass das Alter keinen systematischen Zusammenhang mit den Antworten aufwies (Pearson-Korrelationsanalysen zwischen Alter und Ausprägung der abhängigen Variablen, alle p >.13). Deshalb wurde das Alter in der folgenden Ergebnisdarstellung nicht weiter berücksichtigt.
Die Teilnehmenden wurden gefragt, ob sie eine berufliche Qualifikation im Bereich Kommunikation, Sprecherziehung, Stimmbildung oder Ähnlichem haben, und konnten dies mit Ja oder Nein beantworten. Von den 50 Personen gaben 36 an, eine solche Expertise zu besitzen. Auch hier ergaben statistische Analysen, dass diese Expertise keinen Einfluss auf die Beurteilung der Videoaufnahmen hatte (ANOVA mit den Faktoren Distanz, Fragen, Expertise; kein Haupteffekt und keine signifikanten Interaktionen mit dem Faktor Expertise, alle p >.17). Daher wird auch dieser Faktor in den folgenden Ergebnissen nicht berichtet.
Unsere Hypothese legt nahe, dass die Erfahrung mit Videomeetings die Wahrnehmung der Distanzen beeinflussen könnte. Daher wurden die Proband*innen gefragt, wie häufig sie wöchentlich an Videomeetings teilnahmen. Für die statistischen Analysen wurden die Proband*innen entsprechend ihren Antworten in drei Erfahrungsgruppen eingeteilt: wenig (< 1-mal pro Woche, N = 14), mittel (1- bis 2-mal pro Woche, N = 15), viel (³ 3-mal pro Woche, N = 20). Eine Person machte keine Angabe.
3.2 Videomaterial
Für unsere Untersuchung wurden fünf Workshopthemen gewählt: Antirassismus, Erste Hilfe, Nachbarschaftshilfe, Zivilcourage und Konfliktmediation im Alltag. Die Begrüßungstexte finden sich im Anhang.
Die Sprecher*innen der Begrüßungstexte waren 2 Frauen und 3 Männer, alle waren ausgebildete Sprechkünstler*innen. Für jeden Workshop sprach eine andere Person die Begrüßung. Jede Person sprach die Begrüßung 4-mal mit jeweils einer anderen Distanz zur Kamera (100 cm, 75 cm, 50 cm, 35 cm), und es wurden Aufnahmen erstellt. Die Distanzen wurden so gewählt, dass die Unterschiede deutlich sichtbar waren (siehe Abbildung 1). Jede Begrüßung dauerte ca. 2 Minuten.
Obwohl alle Sprecher*innen ausgebildete Sprechkünstler*innen sind und damit in der Lage, die vier aufgenommenen Workshopbegrüßungen sehr ähnlich zu sprechen, sind nacheinander aufgenommene Begrüßungen hinsichtlich Sprechweise und Körpersprache nie komplett identisch. Um zu überprüfen, ob diese möglichen Abweichungen zu unterschiedlichen Wahrnehmungen geführt haben könnten, wurde folgende Kontrollbedingung eingeführt: Aus der Aufnahme mit der 100-cm-Distanz wurde durch Ausschneiden eines kleineren Bildausschnittes eine 35-cm-Distanz „simuliert“ (siehe Abbildung 1). Diese diente als Kontrolldistanz (100-auf-35-cm-Distanz) und stimmte bezüglich des Bildausschnittes mit der 35-cm-Distanz überein (Kopf und Schultern sichtbar). Ein statistischer Vergleich zwischen diesen beiden Aufnahmen sollte klären, ob beide Aufnahmen bei den Proband*innen unterschiedliche Eindrücke hinterließen. Falls sich keine Unterschiede finden sollten, können wir davon ausgehen, dass die beiden Aufnahmen sprecherisch sehr ähnlich sind.
Eine alternative Möglichkeit wäre gewesen, nur eine Aufnahme mit dem Abstand von 100 cm anzufertigen und durch vier unterschiedliche Bildausschnitte die näheren Distanzen zu simulieren. Dadurch wären alle Aufnahmen sprecherisch und körpersprachlich identisch gewesen und hätten sich nur im Bildausschnitt unterschieden. Jedoch wäre die Bildästhetik im Vergleich zu Aufnahmen aus näheren Distanzen eine andere gewesen. Je näher man vor einer Kamera steht, umso stärker ist die perspektivische Verzerrung durch die Kamera. Insbesondere Augen, Nase und Lippen erscheinen dann im Verhältnis zum Rest des Bildes vergrößert (siehe Abbildung 1). Da in Videomeetings jedoch genau diese Verzerrungen sichtbar sind, wurden für die Studie die vier Distanzen mit jeweils eigenen Videos aufgenommen.

Abb. 1: Bildausschnitte mit den verschiedenen Distanzen (100 cm, 75 cm, 50 cm, 35 cm, 100-zu-35 cm [Kontrollbedingung])
Wie in Abbildung 2 zu sehen ist, wurde jede Videoaufnahme auf einem Bildschirm gezeigt, der aussah wie ein Zoom-Meeting, also mit der entsprechenden Hintergrundfarbe, Kontrollbuttons und Fenstern anderer Workshopteilnehmender.

Abb. 2: Gesamtansicht des Bildschirms
Alle Proband*innen sahen nacheinander fünf unterschiedliche Workshopbegrüßungen, jede zu einem anderen Thema und in einer anderen Distanz (100 cm, 75 cm, 50 cm, 35 cm, 100-auf-35-cm). Die fünf Begrüßungen wurden in randomisierter Reihenfolge präsentiert. Die Kombination aus Thema und Distanz wurde über alle Proband*innen hinweg so ausbalanciert, dass jedes Workshopthema in jeder einzelnen Distanz gleich häufig gesehen wurde. Hierdurch sollten sich mögliche Effekte der Sprecher*innen oder Workshopthemen herausmitteln.
3.3 Fragebogen
Nachdem Proband*innen eine Workshopbegrüßung gesehen hatten, wurden sie zu ihrem Eindruck befragt. Hierzu sahen sie acht Fragen bzw. Aussagen auf dem Bildschirm und sollten auf einer 7-stufigen Likert-Skala angeben, inwieweit diese Aussagen zutrafen (1 = trifft gar nicht zu; 7 = trifft voll und ganz zu): (1) Ich fand, dass bei der Begrüßung Form und Inhalt gepasst haben, (2) Ich fand die Begrüßung angenehm, (3) Ich konnte dem Gesagten gut folgen, (4) Ich fühlte mich angesprochen, (5) Der/die Sprecher*in hat sich vertraut angefühlt, (6) Der/die Sprecher*in wirkte glaubwürdig, (7) Ich fand den/die Sprecher*in kompetent, (8) Der/die Sprecher*in war mir sympathisch.
Am Ende der Studie wurden persönliche Angaben abgefragt, und zwar Geschlecht, Alter, die Häufigkeit, mit der man wöchentlich an Videomeetings teilnimmt (< 1-mal, 1- bis 2-mal, 3- bis 5-mal, 5- bis 10-mal, > 10-mal), und ob die Teilnehmenden eine berufliche Qualifikation im Bereich Kommunikation, Sprecherziehung, Stimmbildung oder Ähnliches haben. Zur Kontrolle wurde außerdem gefragt, ob die Teilnehmenden eine Vermutung hätten, worum es in dieser Studie ging. Vier Proband*innen formulierten die korrekte Hypothese. Eine Auswertung der Daten ohne diese vier Proband*innen zeigte keine anderen Effekte als mit der Gesamtstichprobe. Somit werden im Folgenden die Ergebnisse aller 50 Proband*innen dargestellt.
3.4 Durchführung
Die Studie wurde als Online-Studie auf der Plattform soscisurvey.de durchgeführt. Die Proband*innen wurden im Vorfeld darum gebeten, nur mit Tablet oder Rechner und nicht mit einem Handy an der Studie teilzunehmen. Über einen bereitgestellten Link konnten die Proband*innen die Studie in einem Browser starten.
Nach einer allgemeinen Erklärung zur Studie sahen die Teilnehmenden die erste Workshopbegrüßung. Anschließend füllten sie den oben beschriebenen Fragebogen aus, um ihren Eindruck dieser Workshopbegrüßung zu bewerten. Diesen Vorgang wiederholten sie für vier weitere Workshopbegrüßungen, jeweils gefolgt von dem entsprechenden Fragebogen. Am Ende der Studie wurden die persönlichen Angaben abgefragt (siehe „Fragebogen“) und den Proband*innen für ihre Teilnahme gedankt. Die Teilnahme dauerte insgesamt ca. 15 Minuten.
4. Ergebnisse
Eine Übersicht über die Ergebnisse (Mittelwerte und Standardabweichungen der Antworten pro Frage und Distanz) findet sich in Tabelle 1.

Tab. 1
4.1 Kontrolldistanz
Wie beschrieben wurde, ist bei den beiden Distanzen 35 cm und 100-auf-35-cm derselbe Bildausschnitt zu sehen. Da es aber zwei unterschiedliche Aufnahmen sind, die sich in Sprechweise und Körpersprache leicht voneinander unterscheiden könnten, wurde statistisch geprüft, ob Proband*innen diese beiden Aufnahmen unterschiedlich empfanden.
Eine ANOVA mit dem 2-stufigen Faktor Distanz (100-auf-35-cm und 35 cm) und dem 8-stufigen Faktor Frage zeigte keinen Haupteffekt für den Faktor Distanz (F(1, 49) = 1.74; p =.19). Die Antworten auf die Fragen unterschieden sich signifikant (F(7, 343) = 11.69; p <.001). Diese Unterschiede waren jedoch unabhängig von der Distanz, was sich in einer fehlenden Interaktion zwischen Frage und Distanz widerspiegelt (F(7,343) =.85; p =.55).
Da die beiden Videoaufnahmen 35 cm und 100-auf-35-cm somit nicht unterschiedlich wahrgenommen wurden, kann davon ausgegangen werden, dass sich die mit unterschiedlichen Distanzen aufgenommenen Workshopbegrüßungen so stark ähneln, dass minimale Unterschiede in Sprechweise und nonverbalen Signalen vernachlässigt werden können. In der weiteren statistischen Analyse wird die Kontrolldistanz (100-auf-35-cm) daher nicht weiter berücksichtigt.
4.2 Vergleich zwischen den vier Distanzen (35 cm, 50 cm, 75 cm, 100 cm)
Die Antworten auf jede der acht Fragen (jeweils gemittelt) lagen bei allen vier Distanzen zwischen 4.70 und 5.96. Somit lagen alle Antworten signifikant über der neutralen Mitte der Likert-Skala von 3.50 (alle p <.05). Das bedeutet, dass alle Distanzen in Bezug auf alle Fragedimensionen positiv wahrgenommen wurden.
Eine ANOVA mit dem 4-stufigen Faktor Distanz (35, 50, 75, 100) und dem 8-stufigen Faktor Frage ergab keinen signifikanten Effekt für den Faktor Distanz (F(3, 147) =.84; p =.48). Der Faktor Frage zeigte einen hochsignifikanten Haupteffekt (F(7, 343) = 13.39; p <.001). Es gab keine Interaktion zwischen Distanz und Frage (F(21,1029) =.82; p =.70). Somit führten die vier Distanzen über alle Proband*innen hinweg nicht zu unterschiedlichen Wahrnehmungen.
4.3 Erfahrung in Videomeetings
Um den Einfluss der Erfahrung mit Videomeetings zu prüfen, wurden die Proband*innen in drei Erfahrungsgruppen eingeteilt (siehe 3.1): wenig (< 1-mal pro Woche), mittel (1- bis 2-mal pro Woche), viel (³ 3-mal pro Woche). Die Erfahrung wurde als Between-Faktor (wenig, mittel, viel) in die ANOVA mit aufgenommen.
Die 3-faktorielle ANOVA mit den Faktoren Erfahrung, Distanz und Frage ergab keinen Haupteffekt für die Erfahrung (F(2,46) =.01; p =.99). Auch die Interaktion zwischen den Faktoren Erfahrung und Frage ergab keinen signifikanten Effekt (F(14,46) = 1.23; p =.21). Signifikant wurde aber die 2-fach-Interaktion zwischen Erfahrung und Distanz (F(6,46) = 3.94; p <.001). Die 3-fach-Interaktion zwischen Erfahrung, Distanz und Frage zeigte einen Trend (F(24.15, 46) = 1.51; p =.06).
Um zu erfassen, wie die Interaktion zwischen Erfahrung und Distanz zustande kam, wird im Folgenden jede der drei Erfahrungsgruppen (wenig, mittel, viel) getrennt betrachtet. Die Mittelwerte der Antworten für die drei Gruppen in Abhängigkeit der Distanz sind in Abbildung 3 grafisch dargestellt.
4.3.1 Erfahrung: wenig (< 1-mal pro Woche)
Eine 2-faktorielle ANOVA ergab signifikante Haupteffekte für Distanz (F(3,39) = 3.94; p <.05) und Frage (F(7,91) = 3.05; p <.01). Die Interaktion zwischen beiden Faktoren wurde nicht signifikant (F(6.3,82.0) = 1.43; p =.10).
Um zu erkennen, welche der vier Distanzen sich von welchen unterscheiden, wurden 2-faktorielle ANOVAs berechnet, in die jeweils nur zwei Distanzen aufgenommen wurden. Die drei näheren Distanzen unterschieden sich signifikant von der 100-cm-Distanz (100 zu 35: F(1,13) = 6.46; p <.05; 100 zu 50: F(1,13) = 12.62; p <.01; 100 zu 75: F(1,13) = 7.33; p <.05). Die drei näheren Distanzen unterschieden sich nicht voneinander (alle p >.41).
Insgesamt zeigt sich, dass die 100-cm-Distanz über alle Fragen hinweg höhere Werte erhielt als die anderen drei Distanzen. Proband*innen mit wenig Erfahrung in Videomeetings empfanden somit über alle Fragen hinweg die entfernteste Distanz am positivsten.
4.3.2 Erfahrung: mittel (1- bis 2-mal pro Woche)
Bei den Proband*innen mit mittlerer Erfahrung ergab die ANOVA signifikante Haupteffekte für Distanz (F(3,42) = 3.86; p <.05) und für Fragen (F(7,98) = 7.10; p <.001). Die Interaktion zwischen beiden Faktoren wurde nicht signifikant (F(21,294) =.70; p =.83).
Einzelanalysen zeigten, dass die 100-cm-Distanz über alle Fragen hinweg niedrigere Werte aufwies als die 50-cm-Distanz (F(1,14) = 5.04; p <.05) und die 75-cm-Distanz (F(1,15) = 13.79; p <.01). Der Unterschied zur 35-cm-Distanz wurde nicht signifikant (F(1,14) = 2.54; p =.13). Alle anderen Distanzen unterschieden sich nicht voneinander (alle p >.11)
Proband*innen mit mittlerer Videomeeting-Erfahrung empfanden somit die 100-cm-Distanz über alle Fragen hinweg am wenigsten positiv. Am positivsten wurden die mittleren Distanzen 50 cm und 75 cm empfunden.
4.3.3 Erfahrung: viel (³ 3-mal pro Woche)
Bei den erfahrenen Proband*innen ergab die ANOVA lediglich einen signifikanten Effekt für den Faktor Frage (F(3.8,72.7) = 6.37; p <.001). Weder der Faktor Distanz (F(3,57) = 1.09; p =.36) noch die Interaktion zwischen Distanz und Frage (F(8.3,147.1) = 1.67; p =.11) zeigten signifikante Effekte.
Die Proband*innen mit viel Erfahrung in Videomeetings empfanden somit alle Distanzen gleich.

Abb. 3: Mittelwerte der Antworten (Skala 1–7) in Abhängigkeit der Distanz (35 cm, 50 cm, 75 cm, 100 cm), getrennt dargestellt für die drei Erfahrungsgruppen (wenig, mittel, viel Erfahrung mit Videomeetings). Fragen: (1) Ich fand, dass bei der Begrüßung Form und Inhalt gepasst haben, (2) Ich fand die Begrüßung angenehm, (3) Ich konnte dem Gesagten gut folgen, (4) Ich fühlte mich angesprochen, (5) Der/die Sprecher*in hat sich vertraut angefühlt, (6) Der/die Sprecher*in wirkte glaubwürdig, (7) Ich fand den/die Sprecher*in kompetent, (8) Der/die Sprecher*in war mir sympathisch.
5. Diskussion
Betrachtet man alle Proband*innen als Gesamtgruppe, so fanden wir keine Unterschiede zwischen den vier verschiedenen Distanzen zum Bildschirm. Ein genauerer Blick zeigt jedoch, dass unsere Erfahrung mit Videomeetings darüber entscheidet, wie wir Distanzen zum Bildschirm wahrnehmen.
Menschen mit wenig Erfahrung in Videomeetings bevorzugen die entferntere Distanz (100 cm). Hier sieht man die Person mit vollständigem Oberkörper. Dieser Bildausschnitt entspricht dem, was wir aus dem traditionellen Medium Fernsehen kennen. So sehen wir z. B. auch in der Tagesschau die Sprecher*innen mit dem gesamten Oberkörper. Nähere Distanzen sind für wenig Erfahrene möglicherweise weniger gewohnt und werden deshalb als weniger positiv empfunden.
Menschen mit mittlerer Erfahrung bevorzugen die mittleren Distanzen 50 cm und 75 cm. Es ist anzunehmen, dass diese Distanzen in Videomeetings am häufigsten vorkommen und wir sie am meisten gewohnt sind. Die entfernte Distanz (100 cm) kommt in Videomeetings selten vor und wird vermutlich deshalb weniger positiv empfunden. Die sehr nahe Distanz mit 35 cm wird womöglich als zu nah erlebt, wenngleich sie numerisch dennoch besser abschneidet als die 100-cm-Distanz.
Für Menschen mit viel Erfahrung scheint die Distanz irrelevant zu sein. Möglicherweise sind diese Menschen durch zahlreiche Videomeetings so viele verschiedene Bildausschnitte gewohnt, dass die Distanz nicht mehr ins Gewicht fällt. Diese Interpretation passt zu dem Befund, dass sich Menschen an die spezielle Kommunikationssituation in Videokonferenzen gewöhnen und ihre Kommunikation anpassen (Braun, 2004).
Unsere Befunde sprechen dafür, dass die Wahrnehmung von Distanzen durch individuelle Erfahrungen mit spezifischen Kommunikationssituationen beeinflusst ist.
Zwei weitere Ergebnisse sind bemerkenswert. Erstens lagen alle Antworten im Mittel signifikant über dem neutralen Mittelwert. Das bedeutet, dass alle von uns gemessenen Distanzen insgesamt positiv erlebt werden. Es gibt keine Distanz, die als unangenehm empfunden wird. Man kann in Videomeetings mit der Distanz zum Bildschirm also im Grunde nichts falsch machen. Dennoch kann man den Abstand optimieren.
Zweitens zeigte sich in unserer Studie an keiner Stelle eine Interaktion zwischen Distanzen und Fragen. Die Distanz hat also einen generellen Effekt auf die Wahrnehmung und führt grundsätzlich zu mehr oder weniger positiven Antworten, sie wirkt aber nicht selektiv auf die einzelnen abgefragten Wahrnehmungsdimensionen wie Vertrautheit, Glaubwürdigkeit, Kompetenz, Sympathie usw. Möchte man in einem Videomeeting also den passenden Bildschirmabstand wählen, so braucht man nicht darüber nachzudenken, welche Wahrnehmungsdimension einem in einem spezifischen Setting besonders wichtig erscheint. Alle Wahrnehmungsdimensionen hängen in gleicher Weise mit der Distanz zusammen.
Unsere Befunde legen nahe, dass es auch in Videomeetings verschiedene proxemische Zonen gibt, die von Menschen unterschiedlich wahrgenommen werden (vgl. Hall, 1966). Menschen, die in Videomeetings unerfahren sind, bevorzugen eine größere Distanz (bei uns 100 cm). Diese ist vermutlich ein Online-Äquivalent für die öffentliche Zone und wird von den unerfahreneren Menschen als angemessen für ein Workshop-Setting empfunden. Die 35-cm-Distanz liegt in der intimen Zone und wird von Menschen mit wenig bis mittlerer Erfahrung als weniger angenehm empfunden als die entfernteren Distanzen. Für Menschen mit mittlerer Erfahrung ist jedoch auch die 100-cm-Distanz weniger positiv. Sie stellt für sie möglicherweise eine zu große Distanz für ein Online-Workshop-Setting dar, weil sie in Videomeetings nähere Distanzen gewohnt sind. Menschen, die sehr viel Erfahrung mit Videomeetings haben, sind möglicherweise verschiedenste Distanzen gewohnt und nehmen Unterschiede gar nicht mehr wahr oder bewerten Unterschiede zumindest als irrelevant für das Meeting.
Wenn die in dieser Studie realisierten Distanzen tatsächlich Online-Äquivalente für die proxemischen Zonen von Hall sind, dann bedeutet das, dass die proxemischen Zonen in Online-Settings näher herangerückt sind als in realen Face-to-Face-Situationen. Ein solches Heranrücken ist plausibel, wenn man bedenkt, dass hinter der Bildschirmübertragung eine große räumliche Distanz vorhanden ist. Eine nähere Bildschirmdistanz könnte daher immer noch als entfernter wahrgenommen werden, als wenn einem der Kommunikationspartner tatsächlich gegenübersäße.
Es stellt sich die Frage, inwieweit die Ergebnisse allgemeine Gültigkeit haben. Die Teilnehmenden wurden über verschiedene Kanäle auf unsere Studie aufmerksam gemacht (Mailinglisten, Facebook). Tatsächlich ist es gelungen, Menschen aus verschiedenen Altersgruppen zu finden. Jedoch wurden über unsere Mailinglisten überdurchschnittlich viele Teilnehmende gewonnen, die eine fachliche Expertise im Bereich Kommunikation aufwiesen. Die Analysen zeigten, dass diese Expertise keinen Einfluss auf die Wahrnehmung der Distanzen hatte und die Ergebnisse somit auch für Menschen ohne diese Expertise gelten.
Zudem wählten wir für unsere Studie das Setting von Online-Workshops. Da die Teilnehmenden von diesen Workshops nur die Begrüßungssequenzen sahen, in denen sie sich als Zuschauende in einer passiven Rolle befanden, bleibt die Frage offen, wie Distanzen von aktiv Teilnehmenden wahrgenommen werden. Unsere Daten haben gezeigt, dass die Erfahrung, die Menschen mit Videomeetings haben, eine entscheidende Rolle spielt. Bei weiteren Untersuchungen sollte dieser Faktor also immer mit untersucht werden.
6. Fazit
Aus den Ergebnissen lässt sich ableiten, dass in Videomeetings eine Distanz von 50 bis 75 cm zum Bildschirm von Vorteil ist. Menschen, die selten mit Videomeetings zu tun haben, scheinen zwar eine weiter entfernte Distanz zu bevorzugen, aber es ist davon auszugehen, dass die Gruppe der Unerfahrenen zunehmend kleiner wird, da immer mehr Menschen mit Videomeetings konfrontiert werden. Außerdem sind die mittleren Distanzen auch für Unerfahrene nicht unangenehm und die Menschen scheinen sich schnell an spezielle Kommunikationssituationen gewöhnen zu können. Für Menschen mit viel Erfahrung spielt die Distanz keine Rolle. Menschen jedoch, die nur mit einer mittleren Häufigkeit mit Videomeetings zu tun haben, sind mit mittleren Distanzen durchaus besser zu erreichen. Das Setting scheint hier am passendsten und am angenehmsten: dem Gesagten kann am besten gefolgt werden, die Zuhörenden fühlen sich am stärksten angesprochen, und der Sprecherin/dem Sprecher wird mehr Vertrautheit, Glaubwürdigkeit, Kompetenz und Sympathie zugesprochen.
Literatur
Ahmadpour, N., Lindgaard, G., Robert, J. M., and Pownall, B. (2014). The thematic structure of passenger comfort experience and its relationship to the context features in the aircraft cabin. Ergonomics, 57(6), 801–815.
Bailenson, J. N., Blascovich, J., Beall, A. C., Loomis, J. M. (2001) Equilibrium theory revisited: Mutual gaze and personal space in virtual environments. Presence: Teleoperators and Virtual Environments, 10(6), 583–598. https://doi.org/10.1162/105474601753272844
Bailenson, J. N., Blascovich, J., Beall, A. C., Loomis, J. M. (2003). Interpersonal distance in immersive virtual environments. Personality and Social Psychology Bulletin, 29(7). 819–833. https://doi.org/10.1177/0146167203029007002
Bogdanova, O. V., Bogdanov, V. B., Miller, L. E., & Hadj-Bouziane, F. (2022). Simulated proximity enhances perceptual and physiological responses to emotional facial expressions. Scientific Reports, 12(109). https://doi.org/10.1038/s41598-021-03587-z
Bradner, E., & Mark, G. (2002). Why distance matters: Effects on cooperation, persuasion and deception. Proceedings of the 2002 ACM, Conference on computer supported cooperative work (CSCW), 226–235.
Braun, S. (2004). Kommunikation unter widrigen Umständen? Fallstudien zu einsprachigen und gedolmetschten Videokonferenzen. Tübingen: Narr Francke Attempto.
Broszinsky-Schwabe, E. (2011). Interkulturelle Kommunikation. Wiesbaden: VS Verlag für Sozialwissenschaften. https://doi.org/10.1007/978-3-531-92764-0_7
Detenber, B. H., & Reeves, B. (1996). A bio-informational theory of emotion: Motion and image size effects on viewers. Journal of Communication, 46(3), 66–84.
https://doi.org/10.1111/j.1460-2466.1996.tb01489.x
Ellis, M. E. (1992). Perceived proxemic distance and instructional videoconferencing: Impact on student performance and attitude. In Annual Meeting of the International Communication Association, 1–25.
Fauville, G., Queiroz, A. C. M., Luo, M., Hancock, J., & Bailenson, J. N. (2022). Impression formation from video conference screenshots: The role of gaze, camera distance, and angle. Technology, Mind and Behavior, 3(1). https://doi.org/10.1037/tmb0000055
Gerhardsson, A., Högman, L., & Fischer, H. (2015). Viewing distance matter to perceived intensity of facial expressions. Frontiers in Psychology, 6, Article 944. https://doi.org/10.3389/fpsyg.2015.00944
Gomboc-Turyan, J. & Tourtellotte, S. (2010). Edward T. Hall and proxemics. The Proceedings of the Laurel Highlands Communications Conference, annual 2010, 130+. Gale Academic OneFile, link.gale.com/apps/doc/A247338951/AONE?u=anon~cc2e941a&sid=googleScholar&xid=68c7d24f. [letzter Abruf: 20.04.2024]
Grayson, D. M. (2000). The role of perceived proximity in video-mediated communication. PhD thesis, University of Glasgow. https://theses.gla.ac.uk/2770/1/2000graysonphd.pdf
[letzter Abruf: 15.04.2024]
Hall, E. T. (1966). The hidden dimension. New York: Doubleday.
Hall, E. T. (1968). Proxemics. Current Anthropology, 9(2/3), 83–108.
Heilmann, C. M. (2011). Körpersprache richtig verstehen und einsetzen. 2., durchgesehene Auflage. München.
Kim, I., & Sung, J. (2024). New proxemics in new space: proxemics in VR. Virtual Reality 28, 85. https://doi.org/10.1007/s10055-024-00982-5
McDonald, C. (2020). Pandemic-Informed Proxemics: Working Environment Shifts Resulting from COVID-19. Available at SSRN 3847684.
Nguyen, D. T., & Canny, J. (2009). More than face-to-face: empathy effects of video framing. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. 423–432.
Patterson, M. L., & Sechrest, L. B. (1970). Interpersonal distance and impression formation. Journal of Personality, 38(2), 161–166. https://doi.org/10.1111/j.1467-6494.1970.tb00001.x
Probst, P., Rothe, S., & Hussmann, H. (2021). Camera distances and shot sizes in cinematic virtual reality. Association for Computing Machinery, 178–186.
Remland, M. S., Jones, T. S. & Brinkman, H. Proxemic and haptic behavior in three European countries. J Nonverbal Behav 15, 215–232 (1991). https://doi.org/10.1007/BF00986923
Sheikh, A., Brown, A., Watson, Z., & Evans, M. (2016). Directing attention in 360-degree video. IBC 2016 Conference, Institution of Engineering and Technology.
Wilcox, L., M., Elfassy, S., Grelik, C., & Allison, R. S., (2006). Personal space in virtual reality. ACM Transactions on Applied Perception 3(4), 412–428.
Anhang
Begrüßungstexte der fünf Workshops
Workshop Antirassismus
Hallo, alle zusammen. Ich heiße Michael Moser und begrüße Sie ganz herzlich zu diesem Online-Workshop mit dem Thema „Antirassismus – Wie gehe ich konstruktiv, aber bestimmt, mit alltagsrassistischen Situationen um?“. Immer wieder werden wir Zeuge von rassistischen Situationen im Alltag. Es sind die abwertenden Blicke im Bus, die rassistischen Rufe im Stadion oder die Zurückweisung an der Discotür. Die mit zweierlei Maß messenden Ausbilder, die Rassismus-unsensiblen Kolleginnen und Kollegen oder die rassistischen Darstellungen in Büchern, Zeitungen und Filmen. Vermeintliche Komplimente wie „Du sprichst aber gut Deutsch“ oder lobend gemeinte Verallgemeinerungen wie „asiatische Schüler sind immer so fleißig“ sind omnipräsent. Diese reproduzieren, wenn auch nicht in böser Absicht, rassistische Klischees. Viele von Ihnen fragen sich, wenn sie solche Szenen beobachten oder gar in Situationen, in denen sie selbst betroffen sind: „Soll ich das ansprechen, und wenn ja, wie?“. Wir werden in den nächsten drei Stunden Techniken beleuchten und ausprobieren, um im ersten Schritt Alltagsrassismus zu identifizieren und im zweiten Schritt höflich, aber bestimmt, zu intervenieren und sich respektvoll abzugrenzen. Der dritte Lernschritt wird die gewaltfreie und deeskalierende Kommunikation beleuchten, die bei Meinungsverschiedenheiten grundsätzlich hilfreich sein kann. Gerade bei diesem wahnsinnig polarisierenden Thema können wir diese Techniken zur Grundausstattung unseres kommunikativen Strategiepools zählen. Und nun wollen wir auch direkt anfangen und schauen uns einmal gemeinsam ein paar Alltagsbeispiele an.
Workshop Erste Hilfe
Hallo. Herzlich willkommen. Mein Name ist Lisa Fischer. Schön, dass ihr dabei seid und euch zu diesem Online-Seminar angemeldet habt: „Ersthelfer sein, aber wie?“. Keine Frage, würden wir in die Situation kommen, dass vor unseren Augen ein Mensch erstickt, einen Infarkt erleidet, stürzt oder einen Unfall baut – wir würden helfen wollen. WÜRDEN, denn: „Äh, ich glaub’, ich kann das gar nicht.“ „Mund-zu-Mund-Beatmung mach ich aber nicht.“ Oder: „Was, wenn ich es verschlimmere?“ Ein Gefühl der Hilflosigkeit oder Überforderung ist sehr wahrscheinlich. Den letzten Erste-Hilfe-Kurs haben die meisten wahrscheinlich kurz vorm Führerschein machen müssen. Und die Übung, wie ich jemanden aus einem Auto, hinter einem aufgeplatzten Airbag, greife, hat bestimmt hauptsächlich den Wunsch ausgelöst, bitte niemals in so eine Situation zu kommen. Zur Ersten Hilfe gehört aber so viel mehr. Der Vater schneidet sich beim Zwiebeln schneiden tief in die Hand, die Schwester verschluckt sich am Brötchen und droht zu ersticken, oder die Oma greift sich ans Herz und sinkt zu Boden. In diesen Situationen wollen wir nicht hilflos sein, sondern handeln können. Hier ist sehr schnelles Handeln gefragt, und kein komplexes. Das, was in Serien und Filmen immer wie Heldenarbeit aussieht, besteht praktisch aus konkreten Abläufen, Positionen und Griffen. Welche? In diesem Seminar lernt ihr, Notfallsituationen zu erkennen, die Gefahr einzuschätzen und die richtigen Maßnahmen zu ergreifen. Themen sind unter anderem Bewusstseins-, Atem- und Kreislaufstörungen, Herz-Lungen-Wiederbelebung, Wunden, Knochenbrüche, Verbrennungen und Verletzungen. Legen wir los, damit ihr, wenn Ersthilfe gefragt ist, euch nicht hilflos fühlen müsst, sondern sagen könnt: „Okay, ich weiß, was jetzt zu tun ist.“
Workshop Nachbarschaftshilfe
Hallo, alle zusammen. Ich heiße Thomas Schmidt und darf Sie herzlich begrüßen zu dieser Online-Veranstaltung mit dem Titel „Gelungene Nachbarschaftshilfe – wie kann die Bildung einer solidarischen Kleingemeinschaft gut gelingen?“. Immer wieder kommen wir in die „kleinen Nöte des Lebens“: Wir backen einen Kuchen und brauchen noch ein Ei. Wir hätten gerne Gesellschaft, wollen aber nicht mehr groß ausgehen. Wir wollen ein Regal aufbauen und brauchen dringend noch das richtige Werkzeug. In diesen kleinen Nöten des Lebens merken wir immer wieder, wie schön und hilfreich unser nahes Umfeld ist. Der kurze Weg über den Flur zu einem Nachbarn, der einem zu dem fehlenden Ei noch ein nettes Lächeln und eine Plauderei liefert, gibt einem das Gefühl von Heimat über unsere vier Wände hinaus. Oft genug kommen wir auch in die „großen Nöte des Lebens“: Wir werden älter und brauchen Hilfe, etwa beim Hinauftragen schwerer Einkäufe. Wir brauchen dringend eine vertrauensvolle Obhut für unsere Kinder oder die Haustiere, weil wir unbedingt noch einmal auf die Arbeit müssen. Oder wir wünschen uns innig, ein leidenschaftliches Hobby mit anderen verbundenen Menschen zu teilen. Gerade das Thema des Alterns ist eines, das jeder von Ihnen am eigenen Leibe erfahren hat oder zumindest im nahen Umfeld der Eltern/Großeltern kennt. „Was mache ich bloß mit meinen Eltern?“, fragen sich vielleicht sogar einige von Ihnen. „Ich kann nicht jeden Tag nach Ihnen sehen, und ein gutes Heim, wo Sie wirklich umsorgt sind, das ist einfach zu teuer.“ Für viele Menschen sind diese Sorgen alltägliche Realität. Und auch wenn das nicht Ihre Lebensrealität widerspiegelt, so merkt man mit den Jahren doch zumindest, dass man nach einem feuchtfröhlichen Abend froh um einen Tag auf der Couch und die unbegrenzte Welt der Suppenlieferdienste ist. Heute will ich Ihnen zeigen, in welchen Schritten man eine Community aufbaut, die aktive Nachbarschaftshilfe leistet und in den kleinen und großen Nöten des Lebens unabhängiger macht, durch ein Miteinander, durch gemeinsame Teilhabe, und in einer Art und Weise, in der jeder – ob jung oder alt – davon profitieren kann.
Workshop Zivilcourage
Hallo und herzlich willkommen zum Online-Seminar „Zivilcourage im 21. Jahrhundert“. Ich heiße Anton Schneider und ich freue mich auf einen interessanten Tag mit Ihnen. Ich möchte, dass Sie sich eine Szene vorstellen: Sie sind in der Großstadt, in der U-Bahn. Es ist spät, nur vier andere Personen im gleichen Waggon. Der Zug hält an der nächsten Haltestelle, und eine Gruppe betrunkener Männer steigt ein. Die Männer setzen sich direkt neben ein einzelnes Mädchen und beginnen, es anzumachen. Einer der Männer berührt das Mädchen, ein anderer beginnt es zu schubsen. Das Mädchen bittet die Männer, aufzuhören, aber sie machen weiter. Die anderen Passagiere wenden sich ab, zu feige, sich der Situation zu stellen. Sie werden in zwei weiteren Haltestellen aussteigen und stehen vor einem Dilemma: Wenden Sie sich ab und tun so, als ob nichts passiert? Oder stellen Sie sich den Männern und riskieren, selbst verletzt zu werden? Fragen Sie sich jetzt: Wie würde ich in dieser Situation reagieren? Wäre ich mutig genug? Würde ich einen kühlen Kopf bewahren? Wüsste ich überhaupt, was ich sagen soll? Vielleicht würde die kleine Stimme in Ihrem Kopf sagen: „Sie kann sicherlich auf sich selbst aufpassen.“ „Ich muss sowieso in zwei Stopps aussteigen.“ „Es wird es nur noch schlimmer machen, wenn ich mich einmische.“ Mut bedeutet, etwas zu tun, obwohl man Angst hat. Zivilcourage bedeutet, zu sagen: „Ich bin Teil der Gesellschaft.“ Obwohl Szenen wie diese fiktiv scheinen, passieren sie jeden Tag in vielen Städten der Welt. Die meisten von uns sind irgendwann mit ähnlichen Situationen konfrontiert worden, und wenn wir ehrlich sind, haben sich die meisten von uns mindestens einmal abgewendet. Die Welt wird immer anonymer. Die Welt wird immer egoistischer. Deshalb ist es umso wichtiger, dass Leute wie Sie und ich aufstehen und gezählt werden. Und jetzt hoffe ich, dass Sie eine Tasse Tee oder Kaffee in der Hand haben, dass Sie bequem sitzen. Wir legen los.
Workshop Konfliktmediation im Alltag
Hallo, alle zusammen. Ich heiße Maya Schuster und begrüße Sie sehr herzlich und freue mich, dass Sie sich zu diesem Online-Workshop „Konfliktmediation im Alltag und Umgang mit Menschen in Krisen“ angemeldet haben. Jeder von uns war schon in einer Situation, in der er selbst in großer Not war. Ob es die Trennung ist, die wir nicht haben kommen sehen, der Tod eines nahen Familienangehörigen oder die Absage eines Traumjobs, die unseren Lebensplan in Schutt und Asche legt. In solchen Situationen sind wir dankbar um Menschen, die uns zurück auf den Boden holen und die uns die schönen Dinge des Lebens aufzeigen, die wir im Angesicht großer Not so häufig vergessen. Oft genug überkommt uns aber eine Notlage, ohne dass unsere Nächsten zugegen sind. In diesen Situationen kann ein Lächeln, die richtige Frage, etwas Zuwendung unfassbar heilsam sein. Stellen Sie sich vor, in der Bahn bekommen Sie das Telefonat eines Fremden mit. Er ist am Boden zerstört, erlebt einen Breakdown und fasst vielleicht sogar in Worte, dass er keine Perspektive mehr sieht und er das Lebenswerte am Leben nicht mehr erkennen kann. In diesem Augenblick wissen Sie vielleicht nicht, wie Sie handeln sollen. Sie wenden sich vielleicht ab, überfordert davon, nicht zu wissen, wie man adäquat reagiert. Was passiert, wenn dieser Mensch die Bahn verlässt, tut er sich vielleicht etwas an? Hat er jetzt Menschen, die ihn auffangen können? Diese und andere Fragen schießen Ihnen durch den Kopf, und die Situation lässt Sie eine Weile lang nicht mehr los. In diesem Workshop lernen wir, wie man in Situationen wie dieser adäquat eingreift, wie man Hilfestellung gibt und wie man über positives Framing in für andere aussichtslosen Situationen lebenswerte Perspektive aufzeigt.
Autor/-innen

© Kerstin H. Kipp
Kerstin H. Kipp
Kerstin H. Kipp ist Professorin für Angewandte Rhetorik und Sprechwissenschaft an der Staatlichen Hochschule für Musik und Darstellende Kunst Stuttgart. Seit 2021 leitet sie das Institut für Sprechkunst und Kommunikationspädagogik. Zuvor war sie Wissenschaftliche Leiterin des ZNL TransferZentrum für Neurowissenschaften und Lernen in Ulm. Sie studierte Sprechwissenschaft und Sprecherziehung sowie Psychologie an der Universität des Saarlandes und an der University of Aberdeen. In der Psychologie promovierte sie 2003 mit summa cum laude und erlangte 2011 ihre Habilitation.
Arbeitsort: Stuttgart
E-Mail: kerstin.kipp@hmdk-stuttgart.de
Postanschrift: Staatliche Hochschule für Musik und Darstellende Kunst Stuttgart
Urbanstraße 25
70182 Stuttgart
Tel: +49 711 212 4635

Orlando Schenk © Hannes Keller
Orlando Schenk
Orlando Schenk M.A. Sprecherzieher (DGSS) erhielt zunächst an der Universität von Durham (U.K.) seinen Bachelor in Geschichte und Musik, bevor er an der Guildhall School of Music & Drama in London Gesang studierte. Sein Masterstudium in Sprechwissenschaft und Sprecherziehung absolvierte er an der Universität Regensburg. Er ist zudem qualifizierter Sprecherzieher und Heilpraktiker für Psychotherapie, und künstlerischer/pädagogischer Sprecher bei der Akademie für gesprochenes Wort in Stuttgart. Als Opernsänger hat er unter anderem mit Peter Brook, Claudio Abbado, Daniel Harding und Mark Elder gearbeitet, in Aix-en-Provence, Tokyo, New York, San Diego, Chicago, London, Milan. Als Darsteller war er zu sehen auf BBC, Sky Arts, und auch in Werbespots in Deutschland für z.B. Obi, Volvo und Bayer.
Arbeitsort: Stuttgart
Postanschrift: Akademie für gesprochenes Wort – Uta Kutter Stiftung, Haußmannstraße 22, 70188 Stuttgart

Ramon Schmid © Hannes Keller
Ramon Schmid
Ramon Schmid ist Kommunikationstrainer, Sprecher, Autor und Musiker. Seit 2012 gibt er Trainings im Bereich kreatives Schreiben, Poetry Slam und „Human Beatbox“. Ramon Schmid hält Schulungen im Bereich der Kommunikation und Rhetorik und begleitet Veränderungsprozesse in Betrieben, Vereinen und Organisationen. Mit abendfüllenden Programmen bespielt Ramon Schmid die Bühnen der Republik, stets mit dem Anspruch verschiedene Künste zu vereinen und die Grenzen der Sparten zu sprengen. Dabei verbindet er Text und Ton, fremde und selbst geschriebene Texte, Theater und Sprechkunst. Ramon Schmid studierte an der Hochschule für Musik und Darstellende Kunst in Stuttgart Sprechkunst und Sprecherziehung (B.A.) sowie Angewandte Rhetorik (M.A.).
Arbeitsort: Stuttgart
Postanschrift: Akademie für gesprochenes Wort – Uta Kutter Stiftung, Haußmannstraße 22, 70188 Stuttgart

Jule Hölzgen © Hannes Keller
Jule Hölzgen
Jule Hölzgen ist Sprechkünstlerin, Kommunikationstrainerin und Dozentin für Sprechen. Sie ist in Sprechperfomances und szenischen Lesungen auf der Bühne zu erleben, moderiert Veranstaltungen, gibt sowohl in der freien Wirtschaft als auch im sozialen Sektor Seminare und Einzeltrainings rund um die Themen Rhetorik und Kommunikation und unterrichtet das Fach Sprechen an der Staatlichen Hochschule für Musik und Darstellende Kunst Stuttgart. An dieser absolvierte sie ihren Bachelor im Fach Sprechkunst und Kommunikationspädagogik und ihren Master im Fach Sprechkunst.
Arbeitsort: Stuttgart
Postanschrift: Akademie für gesprochenes Wort – Uta Kutter Stiftung, Haußmannstraße 22, 70188 Stuttgart
Kontakt
„Sprechen & Kommunikation – Zeitschrift für Sprechwissenschaft“ wird herausgegeben von der Deutschen Gesellschaft für Sprechwissenschaft und Sprecherziehung e. V.
Erschienen am: 26.10.2023

Körper, Stimme, Haltung online trainieren
Körper·Stimme·Haltung ist eine kostenlose multimediale Lernplattform. Seit 2020 wird das Material in der Lehrkräftebildung im Bereich Stimme und Kommunikation an mehreren Universitäten erfolgreich verwendet, um Studierende bei der Erarbeitung verbaler und nonverbaler Kommunikationsstrategien zu unterstützen. In der Praxisanwendung kann das Material auf vielfältige Weise zum Einsatz kommen. Nutzungsdaten und Bewertungsstudien zeigen, dass die Arbeit mit der Lernplattform sowohl aus Sicht der Studierenden als auch aus Sicht der Lehrenden gewinnbringend ist.
– Konzept und Praxisanwendungen einer digitalen Selbstlernplattform
von Maria Luise Gebauer, Maxi Mercedes Grehl, Friderike Lange
Schlüsselwörter
Stimme, Kommunikation, Sprechbildung, Selbstlernplattform, Onlinekurs
Zusammenfassung
Körper·Stimme·Haltung ist eine kostenlose multimediale Lernplattform. Seit 2020 wird das Material in der Lehrkräftebildung im Bereich Stimme und Kommunikation an mehreren Universitäten erfolgreich verwendet, um Studierende bei der Erarbeitung verbaler und nonverbaler Kommunikationsstrategien zu unterstützen. In der Praxisanwendung kann das Material auf vielfältige Weise zum Einsatz kommen. Nutzungsdaten und Bewertungsstudien zeigen, dass die Arbeit mit der Lernplattform sowohl aus Sicht der Studierenden als auch aus Sicht der Lehrenden gewinnbringend ist.
Keywords
voice, communication, speech training, self-study platform, online course
Abstract
Körper·Stimme·Haltung is a free multimedia learning platform. Since 2020, the material has been used successfully in teacher training at several universities. The aim of the learning platform is to support students in developing verbal and non-verbal communication strategies. In practice, the material can be used in a wide variety of ways. User data and evaluations show that the material are beneficial for both students as well as educating staff in the field of voice and communication in teacher training.
1 Hintergrund, Ziele und Aufbau der Selbstlernplattform Körper·Stimme·Haltung
1.1 Hintergrund und Ziele
Um den Anforderungen des Berufsalltags einer Lehrkraft gerecht zu werden, bedarf es nicht nur der Ausbildung einer profunden fachlichen Kompetenz und der Entwicklung methodischer und didaktischer Vielfalt – auch stimmliche Leistungsfähigkeit und nonverbale Kommunikationskompetenz spielen eine entscheidende Rolle. Wer die Wirkung der Stimme und des Körperausdrucks gekonnt und zielsicher einsetzt, wird gehört, gesehen und verstanden. Eine Stimme, die die inneren und äußeren Impulse der Lehrkraft im Schulalltag flexibel abbildet, wirkt sich unmittelbar auf das Selbstbewusstsein und die Sicherheit der Lehrkraft im Unterricht aus und trägt damit auch positiv zur Lernatmosphäre bei (Voigt-Zimmermann, 2011, S. 274 f.).
Lehrkräfte verbringen ihren gesamten Arbeitstag sprechend. Sie gehören zur Gruppe der Berufssprecherinnen und Berufssprecher. Die stimmliche Belastung und damit einhergehend das Risiko, stimmkrank zu werden, sind demnach sehr hoch (u. a. Mattiske et al., 1998; Sick, 2019; Heeg, 2022). Dies hat nicht nur negative Auswirkungen auf die Lehrperson selbst, sondern auch auf das Lernverhalten der Klasse. Zahlreiche Studien belegen, dass heisere, überbelastete Stimmen Aufmerksamkeitsverlust, geringere Erinnerungsfähigkeit sowie Disziplinprobleme bei den Lernenden verursachen (u. a. Voigt-Zimmermann, 2011, S. 273). Untersuchungen der Universität Leipzig zeigten, dass bereits über 37 % der untersuchten Lehramtsstudierenden verschiedener Hochschulen bundesweit ihre Stimme nicht optimal nutzen oder eine Stimmstörung haben (Lemke, 2006, S. 26). Laut Fuchs (2016, S. 113) steigt das Risiko einer Stimmerkrankung bei Lehrkräften um das 1,6-Fache, wenn eine Stimmausbildung während des Studiums fehlt. Nusseck et al. (2021, S. 445) konnten belegen, dass stimmlich geschulte Lehrkräfte im Vergleich zu stimmlich nicht geschulten Lehrkräften auch langfristig signifikant höhere Werte erzielen hinsichtlich Stimmqualität, Bewusstsein für den Stimmgebrauch und mentaler Gesundheit. Es ist also dringend notwendig, die Zielgruppe bereits während des Studiums für ihre Stimme und Sprechweise und damit einhergehend auch hinsichtlich ihrer nonverbalen Körperausdrucksmittel zu sensibilisieren.
Aus diesem Grund ist das Lehramtsspezifische Schlüsselqualifikationsmodul (LSQ) mit dem Modulteil Kommunikation und Stimme an der Martin-Luther-Universität Halle-Wittenberg (MLU) für die Studierenden aller Schulformen und Lehramtsfächer obligatorisch. Das Ziel des Modulteils ist die Entwicklung stimmlicher und kommunikativer Kompetenzen und Handlungsstrategien für den zukünftigen Berufsalltag. Um die Lehre in diesem Bereich mit einem multimedial angelegten Lernangebot zu unterstützen, wurde 2018 am Zentrum für Lehrer:innenbildung der MLU ein auf zwei Jahre angelegtes Projekt ins Leben gerufen. Bei der Konzeption gab es unterstützende Kooperationen mit der Abteilung Sprechwissenschaft und Phonetik der MLU sowie der Arbeitsgemeinschaft Sprechen im Lehrberuf, einer Initiative des mitteldeutschen Berufsverbands für Sprechwissenschaft und Sprecherziehung (MDVS e. V.). Das Projekt wurde aus Hochschulpakt-Mitteln des BMBF gefördert.
Entstanden ist dabei die Selbstlernplattform Körper·Stimme·Haltung (im Folgenden: KSH), die im März 2020 fertiggestellt wurde und online ging (KSH, 2020).
Die Selbstlernplattform richtet sich an Studieninteressierte, Studierende, Lehrkräfte im Vorbereitungsjahr sowie im Schuldienst. Sie hat das Ziel, angehenden und erfahrenen Lehrkräften die Wirkung von Körperausdruck, (innerer) Haltung, Stimme und Aussprache bewusst und erlebbar zu machen. Das angebotene Material aktiviert und befähigt dazu, die eigenen körperlichen und stimmlichen Ausdrucksmittel zu beobachten, zu reflektieren und zu trainieren (Grehl & Lange, 2020, S. 48). Ziel ist es, dabei eine Wahrnehmungsförderung von körpereigenen Prozessen und deren Auswirkungen auf die Kommunikation hinsichtlich der Funktionsabläufe Atmung, Körperhaltung, Körperausdruck, Stimmgebung und Artikulation zu erreichen. KSH fokussiert darüber hinaus die Entwicklung verbaler und nonverbaler Kommunikationsstrategien und die Selbstregulation der Lehrkräfte im Hinblick auf Stressbewältigung und stimmliche Gesunderhaltung. Die praxisnah aufbereiteten Inhalte sollen die Nutzenden motivieren, sich selbstständig auszuprobieren und die Strategien in den späteren Berufsalltag zu übertragen. Im Idealfall ergibt sich daraus eine Steigerung der Professionalität, des Selbstwirksamkeitserlebens und der Resilienz.
1.2 Aufbau und Material
KSH bietet verschiedene Wissens- und Übungsressourcen. Die einzelnen Elemente können unabhängig voneinander rezipiert und didaktisch eingesetzt werden. Gleichzeitig können, folgt man der vorgeschlagenen Abfolge der Übungsbausteine, die Ressourcen auch als aufeinander aufbauender Onlinekurs absolviert werden. Die kostenlose Selbstlernplattform ist als Open Educational Ressource unter einer CC-Lizenz veröffentlicht und über die Internetseite https://koerperstimmehaltung.zlb.uni-halle.de/ und den YouTube-Kanal Körper Stimme Haltung frei zugänglich.
KSH teilt sich in die Bereiche Basis und Thema. Unter Basis sind mögliche Verwendungsszenarien der Lernplattform, Videos mit Ideen für Wirkungsstrategien zu den Themen Lampenfieber, Wahrnehmung und Interaktion sowie weiterführende Adressen und ein Literaturverzeichnis zu finden.
Im Bereich Thema befindet sich jeweils ein Kapitel zu den Funktionskreisen des Sprechens: Körper, Atmung, Stimme und Aussprache. Jedes dieser vier Kapitel enthält ein Erklärvideo, ein Wissensquiz zur Hörschulung und Festigung des Gelernten, zahlreiche Übungsvideos mit Schritt-für-Schritt-Anleitung zum Nachmachen sowie Lifehacks mit Beispielen für den Transfer in den Alltag und Literaturhinweise. Die Kapitel sind so angelegt, dass sie aufeinander aufbauen und nacheinander durchgeführt werden können.
Ziel war es, leicht rezipierbares, abwechslungsreiches Material zu schaffen, das die Themen verständlich transportiert, zum Üben motiviert und gleichzeitig den Mediennutzungsgewohnheiten der Zielgruppe (Guo, Kim & Rubin 2014, S. 2) entspricht. Aus diesem Grund wurde der Einsatz von Videos forciert. Die KSH-Videos haben eine Länge von maximal sechs Minuten und sind von hoher Bild- und Tonqualität. Um die Verständlichkeit zu sichern, wurde mit Animationen und Einblendungen gearbeitet und auf eine einfache und zugängliche Sprache geachtet (Schmelzle, 2014). Die Übungen und Erklärungen wurden stets in Situationen des Schulalltags eingebettet.
Übungen zu Stimme und Körperausdruck können mitunter als sehr ungewohnt empfunden werden. Um die Rezipierenden zu motivieren und zu aktivieren, sind die ausgewählten Übungen einfach durchzuführen, in ihrem Aufbau eindeutig nachvollziehbar und dadurch weniger fehleranfällig. Um die Nahbarkeit zu erhöhen, wurde auf eine lockere, persönliche und humorvolle Ansprache gesetzt. Darüber hinaus spielt die sprecherische Vorbildfunktion der Darstellenden eine Rolle: Alle Personen, die in den Videos zu sehen und/oder zu hören sind, verfügen über eine sprechwissenschaftliche Hochschulausbildung. Eine Darstellerin hat außerdem eine abgeschlossene Berufsausbildung als Logopädin, ein Darsteller verfügt über ein abgeschlossenes Schauspielstudium.
Im Folgenden werden die verschiedenen KSH-Videoformate (Wirkungsstrategien, Erklär-, Übungs-, Hackvideos) sowie weitere Zusatzmaterialien der Lernplattform im Einzelnen vorgestellt.
1.2.1 Wirkungsstrategien
Die Wirkungsstrategien dienen dazu, die Nutzenden durch die Darstellung typischer Problemsituationen (Lampenfieber, Konfrontationen vor der Klasse oder Konflikte in der Lerngruppe) einzuladen, über ihre Emotionen, ihre Interaktionsweise und ihre Wahrnehmung zu reflektieren. Außerdem soll dabei eine Sensibilisierung über die Rolle der verschiedenen Funktionskreise des Sprechens (Haltung, Atmung, Stimme, Aussprache) in diesen Situationen erfolgen.
Im Video zur Wirkungsstrategie Lampenfieber beispielsweise begleiten wir eine junge Lehrerin durch ihren Schulalltag, die von Selbstzweifeln und Lampenfieber geplagt wird. Das Lampenfieber wird in Gestalt eines grünen Männchens visualisiert. Es bringt u. a. die Hände und die Stimme zum Zittern und steht ihr buchstäblich im Weg. Wir sehen in der zweiten Hälfte des Videos, wie sich die Protagonistin mithilfe von verschiedenen Selbstregulierungstechniken (aus den Kapiteln Körper, Atmung, Stimme und Aussprache) beruhigt.

Abb. 1: Szenenbeispiele zum Wirkungsstrategievideo Lampenfieber
1.2.2 Erklärvideos
Die Erklärvideos haben zum Ziel, den Nutzenden essenzielles Basiswissen zu den Komplexthemen Stimme und Wirkung im Lehrberuf zu vermitteln und sie für deren Einflussfaktoren und Zusammenhänge zu sensibilisieren. Eine theoretische Grundlage ist für die im Anschluss folgenden praktischen Angebote in Form der Übungsvideos wichtig, damit diese leichter nachvollzogen werden können.
Die Erklärvideos beschränken sich pro Kapitel auf ein Video und beinhalten die grundlegenden und wichtigsten Funktionsweisen des Sprechens. Das Setting und die Struktur sind immer gleich: Zwei Protagonistinnen erklären in einem Klassenzimmer humorvoll und im dynamischen Dialog die wichtigsten Fakten und Zusammenhänge. Veranschaulicht werden diese Erklärungen durch Beispiele, Einblendungen und Animationen. Die Aufbereitung der Inhalte orientiert sich an den Qualitätskriterien nach Kulgemeyer (2018), z. B. Adaptation an den Wissensstand, Verwendung von Beispielen, klare Struktur, Verdeutlichung der Relevanz, angemessene Sprachebene und direkte Ansprache (ebd., S. 10).
Das Erklärvideo für die Atmung beginnt beispielsweise mit einer Animation verschiedener Lehrpersonen, die durch den Schulalltag außer Atem gekommen sind, und zeigt, wie sich dies auf deren Stimmen auswirkt. Die Atembewegungen des Zwerchfells und der Lunge werden durch eine Animation veranschaulicht. Darüber hinaus werden Funktionsweisen und Phänomene erklärt, z. B. der Zusammenhang zwischen Atmung, Emotionen und Selbstregulation. Am Ende eines jeden Erklärvideos folgt eine Überleitung zu passenden Übungsvideos.

Abb. 2: Animationsbeispiele aus dem Erklärvideo Atmung
1.2.3 Übungsvideos
Die Übungsvideos bilden den Hauptteil der Lernplattform. Ein Kapitel beinhaltet mindestens drei Übungsvideos, insgesamt gibt es 15 Übungsvideos. Sie dienen dem selbstständigen Trainieren der verschiedenen Funktionskreise des Sprechens. Die Nutzenden können sich in den stimmrelevanten Bereichen praktisch ausprobieren, um sie für sich erlebbar zu machen. Dabei nehmen die einzelnen Videos Bezug aufeinander und das Übungsniveau wird fortwährend gesteigert. So wird zunächst mit Übungen zur Wahrnehmung und Sensibilisierung begonnen, um dann mit komplexeren Sequenzen zur aktiven Nachahmung und bewussten Verstärkung fortzufahren.
Eine Besonderheit aller Übungsvideos stellt die Gestaltung des Drehortes dar. Das Aufnahmeset sorgt für eine vertraute und sichere Stimmung, sodass Übungen mit einem höheren Maß an Intimität ungehemmt durchgeführt werden können. Zudem wird durch die Wohnzimmeratmosphäre die Einfachheit der Übungsumsetzung transportiert, die keiner aufwendigen Vorbereitung der Räumlichkeit bedarf. Alle Übungen werden von dem gleichen Team – Freja, Maxi und Stephan – durchgeführt.

Abb. 3: Szenenbeispiele aus den Übungsvideos Kiefer lockern, Präsent sein und Atem trainieren
Beim Übungsvideo Stimme finden zeigen die beiden Darstellenden Stephan und Freja abwechselnd unterschiedliche Methoden, um den Sitz der eigenen Stimme zu entdecken. Wichtig hierbei ist, dass durch die Beiden auch unterschiedliche Stimmlagen repräsentiert werden, um möglichst alle Stimmen anzusprechen. Bei der Auswahl der Übungen wurde darauf geachtet, dass sie visuell und auditiv einfach zu erklären sind und kein Zusatzmaterial benötigt wird. Verwendete Lautreihen oder Wörter werden stets als Text eingeblendet. Durch Pausensequenzen können die Nutzenden ihrem individuellen Tempo nachgehen. Die Übungsvideos bauen aufeinander auf. Das Kapitel Stimme beginnt mit den Videos Stimme lockern I, Stimme lockern II, Stimme finden, Stimme füllen, Stimme kräftigen und mündet ins Workout Stimme. In diesem werden zahlreiche Übungen in einen Ablauf für das regelmäßige Üben gebracht. Das Workout Stimme ist eines der wenigen Videos mit einer Spieldauer von über sechs Minuten.
1.2.4 Hackvideos
Für Nutzende kann es unter Umständen sehr herausfordernd sein, sich auf teilweise ungewohnte Übungen einzulassen und diese durchzuführen. Die daran anschließende, meist viel größere Herausforderung ist der Transfer in den Alltag. Um diesen Prozess anzuregen, wurden die Hackvideos entwickelt. Die Bezeichnung basiert auf dem englischen Wort (Life-)Hack, welches simple oder unkonventionelle Wege zur Lösung oder Vereinfachung alltäglicher Anforderungen beschreibt (Mauritz, 2022). Ziel dieses Videotyps ist es, die Nutzenden zur Integration der zuvor gemachten Erfahrungen in ihren Alltag zu motivieren. Die lockere Ansprechhaltung soll die Lust am Ausprobieren steigern. Zudem erhöht die humorvolle Aufbereitung der Hackvideo-Inhalte den Unterhaltungswert der gesamten Lernplattform und verstärkt somit die Identifikation mit derselben.
Bezogen auf den Komplexbereich Sprechen werden in den Hackvideos unkomplizierte Möglichkeiten für die Übertragung des Wissens aus den Erklärvideos und der praktischen Fähigkeiten aus den Übungsvideos in den privaten und beruflichen Alltag werdender und erfahrener Lehrkräfte dargestellt. Um die hohe Bandbreite der Anwendungsmöglichkeiten der Hacks hervorzuheben, wurden für die Filmaufnahmen verschiedene Drehorte genutzt. Szenische Umsetzungen in privaten Wohnräumen, in öffentlichen Verkehrsmitteln oder Klassenzimmern sollen authentisch wirken und für Abwechslung sorgen. In dem Hackvideo Stimme im Alltag beispielsweise sehen wir verschiedene Personen an der Haltestelle, auf dem Schulhof, vor dem Computer oder beim Korrigieren von Klassenarbeiten, die gähnend seufzen, ihre Stimme ausklopfen, beim Kauen genüsslich ihre Stimme erklingen lassen, gurgeln und beim Autofahren mit den Lippen flattern.

Abb. 4: Szenenbeispiele aus den Hackvideos Aussprache im Alltag und Stimme am Morgen
1.2.5 Zusatzmaterial
Zusätzlich zu den Videos gibt es weiteres Material zum Vertiefen einzelner Schwerpunkte. Um regelmäßig an der eigenen Entspannungsfähigkeit zu arbeiten, bietet die Lernplattform zwei Audioaufnahmen: eine Traumreise und eine Anleitung zur Progressiven Muskelrelaxation (PMR) nach Jacobson (Hofmann, 2020). Dabei wurde auf eine hohe Ton- und Sprechqualität geachtet. Die Dauer beträgt jeweils 15 Minuten.
Ein weiteres Angebot zielt auf die Aussprache: Hier bietet KSH Übungsblätter mit passenden Ausspracheübungen für wiederkehrende Auffälligkeiten zur individuellen Förderung an. Das Handout zum Thema Stimmhygiene gibt Tipps zur Stimmpflege im Alltag und zur Verwendung stimmschonender Strategien im Unterricht. Ein wiederkehrender Baustein der Kapitel sind Quizze, durch die nicht nur Wissen abgefragt wird, sondern die vor allem der Hörschulung bezogen auf mögliche Stimm- und Sprechauffälligkeiten dienen. Diese Hörschulung ist eine wichtige Voraussetzung für die eigene stimmliche und sprecherische Sensibilisierung. Jedes Aufbaukapitel schließt mit einer ausführlichen Literaturliste zu Standardwerken der Sprecherziehung, Übungsbüchern und weiterer Fachliteratur zu den jeweiligen Schwerpunkten.
Folgt man der vorgeschlagenen Abfolge der Übungsbausteine, kann KSH als aufeinander aufbauender Onlinekurs absolviert werden. Die einzelnen Elemente sind jedoch auch unabhängig voneinander in verschiedenen didaktischen Szenarien praktisch anwendbar. Der folgende Abschnitt bietet einen Überblick über drei bereits praktisch erprobte Anwendungsszenarien.
1.3 Anleitung zum Kurs
Auf der Selbstlernplattform finden sich unter Basis | Anleitung zum Kurs drei kurze Anleitungsvideos – jeweils eins für Anfänger, Fortgeschrittene und Profis. In diesen Videos wird mittels Screencast in wenigen Minuten erklärt, wie der Kurs aufgebaut ist und wie man sich, je nach Fortschritt, ein individuelles Übungsprogramm zusammenstellen kann. In diesem Zusammenhang wird unter Basis | Hintergrund auch darauf hingewiesen, dass zusätzlich zum Onlinekurs relativ zeitig in der Berufslaufbahn ein Präsenz-Stimmtraining absolviert werden sollte: „Dort bekommst du ein direktes Feedback zu deiner Stimme bzw. deiner Wirkung. Diese wichtige und individuelle Rückmeldung können wir dir in diesem multimedialen Format nicht bieten.“ (KSH 2020). In der sich anschließenden Linkliste wird auf diverse Kontakte und Trainer:innenverzeichnisse u. a. der DGSS verwiesen.
2. Mögliche Szenarien und Settings zur Praxisanwendung
2.1 Asynchroner Kurs – Lerntagebuch
An der MLU wird für die Studierenden des Lehramts aller Schulformen und aller Fächer verpflichtend das Lehramtsspezifische Schlüsselqualifikationsmodul Kommunikation und Inklusion angeboten. Die Lehrveranstaltungen haben das Ziel, angehende Lehrkräfte auf künftige kommunikative, rhetorische sowie stimmliche Herausforderungen in Ausbildung und Beruf vorzubereiten. Dazu erhalten die Studierenden praktisch anwendbares Wissen über Kommunikation, Feedbackkultur, Gesprächsführung sowie ihre eigene kommunikative Wirkung. Sie lernen, ihre Wahrnehmung für kommunikative Ereignisse zu schärfen, und erweitern ihre Analyse- und Feedbackkompetenzen. In Einzel- und Gruppenübungen werden zudem zahlreiche nachhaltige Strategien für eine physiologische, belastbare und variable Sprechstimme entwickelt. Dabei ist hervorzuheben, dass die Seminare Übungscharakter haben und stark von der Gruppendynamik, der direkten Begegnung im Raum und dem Austausch miteinander geprägt sind.
Um der Aussetzung der Präsenzlehre mit Beginn der Pandemie bestmöglich zu begegnen, wurde ein asynchroner Kurs zur selbstständigen Bearbeitung konzipiert: LSQ Kommunikation und Stimme digital (Gebauer, Grehl & Lange, 2022, S. 23). Der Kurs besteht aus einem 15-seitigen ausfüllbaren Reflexions- und Arbeitsheft mit sieben Kapiteln. Alle Kapitel sind folgendermaßen aufgebaut: 1. Einführungstext, 2. Aufgaben, 3. vertiefende Fragen zu den Inhalten sowie 4. eine abschließende Reflexionsfrage zu einem ausgewählten Übungsvideo von KSH. Die wiederkehrende Reflexionsfrage zu diesem Baustein lautet: „Ich habe gerade das Übungsvideo [verlinkte KSH-Ressource] gemacht. Das ist bei mir passiert:“ (Asynchroner Kurs, 2021, S. 5). Die verlinkten Videos von KSH bilden damit eine zentrale Säule im asynchronen Kurs. Durch den Fokus auf die körperliche Wahrnehmung und das bewusste Erleben der eigenen funktionellen Abläufe zu Haltung, Atmung, Stimme und Aussprache bekommt das Arbeitsheft Lerntagebuchcharakter.
An der MLU erhielt der asynchrone Kurs LSQ Kommunikation und Stimme digital aufgrund seiner Methodenvielfalt, seiner Struktur und der Videos von KSH im Jahr 2021 den @ward-Preis für herausragende multimediale Lehrkonzepte und -methoden (Lange, 2021). Ergebnisse aus der offiziellen Lehrveranstaltungsevaluation, die sich auf die KSH-Elemente des Kurses beziehen, werden in Abschnitt 3.4 vorgestellt.
2.2 Selbstreflektiertes Stimmtraining – Portfolioarbeit
Nach drei Semestern asynchron-digitaler Lehre sind die Seminare zu Kommunikation und Stimme an der MLU selbstverständlich wieder vollständig zur Präsenzlehre zurückgekehrt. Die positiven Erfahrungen mit der Anwendung der KSH-Videos als Basis für ein lerntagebuchbegleitetes Stimmtraining führten zur Konzeption der E-Portfolios als Prüfungsleistung im Modulteil Kommunikation und Stimme. Die E-Portfolios werden seit dem Wintersemester 2022/23 seminarbegleitend eingesetzt mit dem Ziel, das erworbene Wissen durch eine intensive Reflexion nachhaltiger zu verankern. Neben der Erwartungsabfrage zu den Seminarinhalten, der Selbsteinschätzung vor und nach dem Seminar, mehreren Wissensbausteinen zu Stimmphysiologie und -pathologie sowie Stimmhygiene und der Reflexion von Aha-Momenten im Seminar bilden die KSH-Videos ein zentrales Element des E-Portfolios in Form eines selbstreflektierten Stimmtrainings. In der Aufgabenstellung werden die Studierenden dazu eingeladen, drei verschiedene Workflows, bestehend aus einer jeweils festgelegten Abfolge von bis zu drei verschiedenen KSH-Übungsvideos, auszuprobieren. Sie sollen dabei ganz ehrlich aufschreiben, wie es ihnen mit den Übungen ging: „Wenn dich etwas nicht abgeholt hat oder du Schwierigkeiten beim Üben hattest, dann schreib das gerne genauso in die Textfelder! Hier gibt es kein Richtig und kein Falsch.“ (Portfolio, 2022, S. 10). Diese sehr freie Einladung zur Reflexion ist wichtig, um sich von der Vorstellung einer gewünschten Zielantwort zu lösen. Somit wird das subjektive Erleben ins Zentrum der Reflexion gestellt.
Idealerweise sollen alle Videos eines Workflows direkt hintereinander geübt werden. Dabei wird empfohlen, nicht mehr als einen Workflow pro Tag zu üben. Dieses Anwendungsszenario zeigt, dass die verschiedenen KSH-Ressourcen nicht nur isoliert oder im Gesamtzusammenhang als kompletter Onlinekurs geübt werden können, sondern dass es darüber hinaus auch möglich ist, einzelne Elemente zu einer beispielsweise 20-minütigen, ganzheitlichen Übungsabfolge zu kombinieren. Workflow 1 im Portfolio besteht z. B. aus den Bausteinen Haltung zeigen, Atem spüren, Stimme lockern I (ebd.). Dabei spiegelt sich das aufeinander aufbauende Prinzip der Funktionskreise Haltung – Atmung – Stimme wider.
2.3 Live-Einsatz im Seminar
Natürlich eignen sich die KSH-Ressourcen auf vielfältige Weise auch im Präsenzseminar. Neben dem gemeinsamen Anschauen der Wirkungsstrategie-Videos als Einstiegsimpuls in eine neue Thematik (z. B. Lampenfieber oder Kommunikation in schwierigen Situationen) können beispielsweise die Erklärvideos oder auch die Wissensquizze als eigenständige oder zusammenhängende Bausteine für Einzel- oder Gruppenarbeitssequenzen verwendet werden.
Zudem können alle Ressourcen auch als Hausaufgabe zur Vor- und Nachbereitung einzelner Seminarsitzungen eingesetzt werden. Somit werden bereits behandelte Seminarinhalte gefestigt oder zu behandelnde Inhalte so vorbereitet, dass die Studierenden sensibilisiert oder durch einen bestimmten Arbeitsauftrag mit bereits erworbenem Wissen in die kommende Sitzung starten können. Dafür eignen sich beispielsweise die Zusatzmaterialien wie die Anleitung zur Progressiven Muskelrelaxation (Vorbereitung des Sitzungsschwerpunkts Körperwahrnehmung) oder das Handout zur Stimmhygiene (Nachbereitung des Sitzungsschwerpunkts Stimmphysiologie und -pathologie). Gleichzeitig können aber auch die Übungsvideos zur Vor- oder Nachbereitung des entsprechenden Funktionskreises mitgegeben werden.
Der Einsatz der KSH-Übungsvideos live im Seminar liegt auf der Hand: Alle Übungsvideos eignen sich prinzipiell zum gemeinsamen Anschauen und Mitmachen. Dass die Anleitung der Studierenden dabei nicht durch die im Raum anwesende Lehrperson (diese sollte das Übungsvideo natürlich ebenso mitmachen wie die Studierenden), sondern durch die im Video zu sehenden Darstellenden erfolgt, bringt methodische Abwechslung und kann Hemmungen beim Üben abbauen.
Ein weiteres Einsatzszenario besteht darin, dass sich die Studierenden zu Hause mit einem speziell ihnen zugewiesenen Übungsvideo auseinandersetzen. Aus dem Video wählen sie eine einzelne Übung aus: möglicherweise die, die ihnen am besten gefallen hat oder bei der sie eine besonders interessante Beobachtung machen oder eine bestimmte Veränderung bei sich selbst feststellen konnten. Diese Übung sollen sie in der nächsten Seminarsitzung für ihre Kommilitoninnen und Kommilitonen nach dem Prinzip Lernen durch Lehren (Martin, 2018) anleiten, was einen weiteren Gewinn von KSH offenbart: Die Zielgruppe wird neben dem Training der stimmlichen und körperlichen Schwerpunkte darüber hinaus auch befähigt, ihr eigenes didaktisches Können zu erproben und ihr Repertoire dahingehend zu erweitern.
Aus unserer Sicht ist der Live-Einsatz der KSH-Übungsvideos im Seminar das ideale Anwendungsszenario: Durch die Anbindung an ein Präsenzformat besteht die Möglichkeit eines direkten und individuellen Expert:innen-Feedbacks beim Üben, das für die Ausbildung einer physiologischen Sprechstimme unerlässlich ist.
KSH ging im März 2020 online und kommt seither in unterschiedlichsten Settings und Lehr-Lernformaten, nicht nur an der MLU, sondern auch an anderen Hochschulen, in der Lehrkräftebildung zur Anwendung. Nachfolgend werden Einblicke in die Nutzungsstatistik via YouTube Analytics sowie in bereits durchgeführte Bewertungsstudien von KSH aus Studierenden- und Lehrendenperspektive gegeben. In Abschnitt 3.4 werden weitere Evaluationsdesiderate formuliert.
3. Nutzung und Evaluation
3.1 YouTube Analytics
Ein Großteil der fertiggestellten Videos von KSH ging gerade rechtzeitig zu Beginn der Pandemie online. Da vielerorts die universitäre Lehre ad hoc auf digitale Formate umgestellt werden musste, griffen viele Kolleginnen und Kollegen im Bereich Sprechbildung dankbar auf das KSH-Material zurück. So wurde und wird mit KSH u. a. auch an den Universitäten Potsdam, Erfurt und Leipzig gearbeitet (Grehl & Lange, 2020, S. 48).
Die Zugriffszahlen des YouTube-Kanals (Stand 10/2023) zeigen, dass es seit März 2020 über 100.000 Aufrufe gab. Der Kanal wurde mittlerweile von über 734 Personen abonniert. Die erfolgreichsten Videos sind die Übungsvideos Haltung zeigen (8450 Klicks), Stimme lockern I (8100), Atem spüren (8000), Workout Lippen und Zunge (7800). Die Zielgruppe ist laut Angaben von YouTube Analytics zwischen 18 und 34 Jahren (84,6 %) alt, zu 66,9 % weiblich und zu 33,1 % männlich.
Die Daten zeigen, dass das Material intensiv genutzt wurde und wird. Dennoch bleibt die Frage offen, welcher Lerneffekt sich aufgrund der Arbeit mit den Videos tatsächlich einstellt. Stimme ist ein komplexes Themengebiet. Praktische Stimmübungen haben immer einen ganzheitlichen Charakter und werden von Lernenden beim ersten Versuch oftmals nicht korrekt umgesetzt. Eine Rückmeldung seitens Expert:innen ist hier in vielen Fällen hilfreich oder sogar unerlässlich, um potenzielle Fehler korrigieren zu können. Im Folgenden werden zwei Studien vorgestellt, die sich mit der Bewertung der Lernplattform aus Studierenden- bzw. Lehrendenperspektive auseinandersetzen.
3.2 Studie zur Gestaltung und Praktikabilität von KSH
Schon während der Projektlaufzeit konnten im Rahmen einer Abschlussarbeit erste Bewertungen von KSH durch Lehramtsstudierende und berufstätige Lehrkräfte erfasst und untersucht werden (Kullmann, 2019). Dabei bezog sich die Forschungsfrage zum einen auf die Bewertung der Gestaltung der Übungsvideos, zum anderen auf die Bewertung der Praktikabilität.
Kullmann (ebd., S. 50) entschied sich für eine quantitative Erhebung mittels standardisiertem Fragebogen, der schriftlich oder online durch die Proband:innen beantwortet wurde. Die Antworten zur gestalterischen Aufbereitung wurden in einer 4-stufigen Likert-Skala von trifft gar nicht zu bis trifft voll zu erfasst. Zum Aktivierungsgrad und zum möglichen Transfer in den Alltag wurden Entscheidungsfragen gestellt, wovon die Negierungen durch Begründungen als Mehrfachantwortmöglichkeiten aufgefächert wurden. Für die Untersuchung wurden die zwei Übungsvideos Stimme lockern I und Kiefer lockern ausgewählt. Befragt wurden 42 Lehramtsstudierende der MLU sowie 4 Lehrkräfte im Schuldienst in Halle und Leipzig.
Die Gestaltung beider Übungsvideos (Länge, Tempo der Inhaltsvermittlung, strukturierter Aufbau, Professionalität allgemein, technische Umsetzung, Sympathie für die anleitende Person und Aufmachung) wurde von den Befragten überwiegend als sehr gelungen bis gelungen bewertet (ebd., S. 55 ff.). Über 90 % der Proband:innen gaben an, während der Videos aufmerksam gewesen zu sein, und fast 80 % konnten die Übungen mitmachen. Knapp 20 % gaben an, sich während der Übungen aufgrund der fehlenden Rückmeldung durch Expert:innen unsicher gefühlt zu haben. 65 % der Befragten schätzten das Videomaterial als Ergänzung zur universitären Lehre als hilfreich ein, fast 59 % sahen die Nutzbarkeit für den späteren Beruf als gegeben (ebd., S. 61 f.).
3.3 Studie zum didaktischen Einsatz von KSH
In einer weiteren Abschlussarbeit wurden Lehrende der Universitäten Erfurt, Potsdam, Leipzig und Halle, die mit KSH im Kontext der Lehramtsausbildung gearbeitet hatten, um eine Einschätzung gebeten (Hardt, 2021). Die Befragung wurde mithilfe eines teilstandardisierten Fragebogens mit offenen und geschlossenen Fragen durchgeführt. Auf einer numerischen Intervallskala von 1 (negativ) bis 10 (positiv) gaben die Expert:innen Auskunft darüber, wie sie die Lernplattform in der Praxis eingesetzt haben und inwiefern die Studierenden aus ihrer Sicht ihre Lernziele mit KSH erreichen konnten (ebd., S. 16 f.).
Alle befragten Expert:innen empfanden den Einsatz des KSH-Materials in ihrer Onlinelehre als sehr unterstützend. Vor allem die Professionalität und die inhaltlich-fachliche Passgenauigkeit waren hierbei ausschlaggebend (ebd.). Die kompakte Spieldauer der Videos wurde positiv erwähnt, ebenso die Vielseitigkeit des Materials. Die positive Evaluation bezog sich ausnahmslos auf alle Übungsvideos der Lernplattform. Hardt konnte weiterhin zeigen, dass alle befragten Sprechbildner:innen das Material auch für ihre Präsenzlehre einsetzen würden: obligatorisch und ergänzend zur Lehre, als Wiederholung bzw. vor- und nachbereitend für zu Hause. Das Feedback der Studierenden zum KSH-Material schätzten die Expert:innen als positiv ein. Eine Probandin schrieb, dass die Studierenden in der Unterrichtsevaluation angaben, mit dem Material „mehr als zufrieden“ zu sein (ebd., S. 30).
3.4 Zusammenfassung und Ausblick
Auf Grundlage der oben beschriebenen Studien lässt sich zusammenfassen, dass KSH sowohl aus Studierenden- als auch aus Lehrendensicht gewinnbringend angewendet wurde und wird. Dies bestätigen auch zahlreiche Rückmeldungen aus LSQ-Seminarevaluationen, in denen die Materialien der Lernplattform häufig als „hilfreich“, „gut aufgearbeitet“ und „anschaulich“ beschrieben werden (Evaluationsbericht, 2021, S. 6 ff.). Allerdings liegen noch keine aussagekräftigen Daten zur Wirksamkeit der Videos vor. Aus diesem Grund ist derzeit eine Studie in Arbeit, die die Wirksamkeit der einzelnen Übungsvideos in den Blick nimmt. Dazu werden Lerntagebucheinträge aus 100 Reflexions- und Arbeitsheften des asynchronen Kurses LSQ Kommunikation und Stimme digital (siehe Abschnitt 2.1) mittels qualitativer Inhaltsanalyse (Kuckartz, 2018) analysiert und evaluiert.
4. Fazit
Insgesamt zeigen die Nutzungsdaten, Rückmeldungen und Untersuchungen zu KSH, dass das Material sehr gut dazu geeignet ist, Grundlagen zu vermitteln. Durch die Vielfältigkeit, die ansprechende Aufbereitung sowie die Nähe zu den Mediennutzungsgewohnheiten der Studierenden ist die Lernplattform niedrigschwellig und vielseitig einsetzbar und findet viele Anknüpfungspunkte in der Lehrkräftebildung. Für vertiefende und komplexere Anwendungen reicht die Rezeption der Videos jedoch nicht vollumfänglich aus: Erstrebenswert ist immer die Anbindung an ein Präsenzformat, bei dem die Möglichkeit eines direkten und individuellen Feedbacks durch Expert:innen besteht. Dennoch können sowohl Studierende als auch Lehrkräfte im Vorbereitungsdienst oder im Beruf durch KSH für ihre Stimmgesundheit und ihren Körperausdruck sensibilisiert werden. Somit kann die Selbstlernplattform ein Türöffner sein und als erste Anlaufstelle verstanden werden, die motivierend auf die Lernenden wirkt, sich weiterhin eingehend mit der eigenen Stimme und der kommunikativen Wirkung zu beschäftigen. Einsetzbar ist die Lernplattform auch als unterstützende Ressource für Beratungsgespräche zwischen Mentor:innen und deren Mentee in Praktika und im Vorbereitungsdienst. Darüber hinaus zeigen Rückmeldungen, dass die Motivation der Lehrenden steigt, Stimm- und Entspannungsübungen direkt in die Klassen zu tragen und zur Unterrichtsgestaltung zu nutzen. Es ist angedacht, weitere Evaluationen von KSH auch mit Lehrkräften aus der zweiten und dritten Phase durchzuführen und dabei vor allem die Langzeitwirkung des Trainingsprogramms in den Blick zu nehmen.
Literatur
Fuchs, M. (2016). Klinische Aspekte von Stimmerkrankungen bei Pädagogen – Fallvorstellung und Diskussion. In M. Fuchs (Hrsg.), Die Stimme im pädagogischen Alltag. Kinder- und Jugendstimme 11 (S. 99–114). Logos.
Gebauer, M. L., Grehl, M. M. & Lange, F. (2022). LSQ Kommunikation und Stimme – asynchron digital. Evaluationsergebnisse und Desiderate eines neuen Kursformats. In M. Ballod & K. Heider (Hrsg.), Lehren für eine Bildung in der Digitalen Welt. Hallesche Beiträge zur Lehrerinnenbildung 5. (S. 23–24). http://dx.doi.org/10.25673/96518
Grehl, M. M. & Lange, F. (2020). Körper, Stimme, Haltung online trainieren. Sprecherziehung und Kommunikation in der digitalen Lehrer*innenbildung. Zentrum für Lehrer*innenbildung Martin-Luther-Universität Halle-Wittenberg (Hrsg.), Digitale Medien in der Lehrer*innenbildung. Eine Sammlung von Good-Practice Beispielen der Martin-Luther- Universität Halle-Wittenberg. Hallesche Beiträge zur Lehrer*innenbildung 3 (S. 48-49). https://wcms.itz.uni-halle.de/download.php?down=57460&elem=3335610
Guo, P. J., Kim, J. & Rubin, R. (2014). How video production affects student engagement: An empirical study of MOOC videos. Proceedings of the first ACM conference on Learning @ scale conference March 2014 (S. 41–50). https://doi.org/10.1145/2556325.2566239
Hardt, G. (2021). Online-Sprechbildung in der Lehramtsausbildung. Eine empirisch-theoretische Untersuchung zu ersten Rückmeldungen zur Arbeit mit dem Material der Online-Plattform Körper·Stimme·Haltung – Wirkungsstrategien für Lehrer*innen. BA-Arbeit Halle (Saale). (Mskr.)
Heeg, K. (2022). Stimmprävention bei Lehramtsstudierenden – Evaluation der Maßnahmen im Projekt STARKE-STIMME-macht-SCHULE am Lehrstuhl für Sprachheilpädagogik der Universität Würzburg. Inauguraldissertation zur Erlangung der Doktorwürde der Fakultät für Humanwissenschaften der Julius-Maximilians-Universität Würzburg. https://opus.bibliothek.uni-wuerzburg.de/opus4-wuerzburg/frontdoor/deliver/index/docId/30576/file/Heeg_Kathrin_Stimmpraevention-bei-Lehramtsstudierenden.pdf
Hofmann, E. (2020). Progressive Muskelentspannung: ein Trainingsprogramm. Hogrefe.
Kuckartz, U. (2018). Qualitative Inhaltsanalyse: Methoden, Praxis, Computerunterstützung. Beltz Juventa.
Kulgemeyer, C. (2018). Wie gut erklären Erklärvideos? Ein Bewertungs-Leitfaden Artikel. Computer + Unterricht 109, 8–11.
Kullmann, F. (2019). Evaluation eines Onlinekurses zur videovermittelten Sprechbildung am Beispiel „Körper – Stimme – Haltung | Wirkungsstrategien für Lehrer*innen“. MA-Arbeit Halle (Saale). (Mskr.)
Lange, F. (2021): Wir haben gewonnen! stimmstark. https://blogs.urz.uni-halle.de/stimmstark/wir-haben-gewonnen/ (02.10.2023)
Lemke, S. (2006). Die Funktionskreise Respiration, Phonation, Artikulation – Auffälligkeiten bei Lehramtsstudierenden. Sprache Stimme Gehör 30, 24–28. https://doi.org/10.1055/s-2006-931529
Martin, J. (2018). Lernen durch Lehren: Konzeptualisierung als Glücksquelle. In O. Burow & S. Bornemann (Hrsg.), Das große Handbuch Unterricht & Erziehung in der Schule. (S. 345–360). Carl Link.
Mattiske, J., Oates, J. & Greenwood, K. (1998). Vocal problems among teachers: a review of prevalence, causes, prevention, and treatment. Journal of Voice 12(4), 489–499. https://doi.org/10.1016/S0892-1997(98)80058-1
Mauritz, S. (2022). Was ist Life-Hacking? Resilienz Akademie. https://www.resilienz-akademie.com/life-hacking/ (02.10.2023)
Nusseck, M., Immerz, A., Spahn, C., Echternach, M. & Richter, B. (2021). Long-Term Effects of a Voice Training Program for Teachers on Vocal and Mental Health. Journal of Voice 35 (3), 438–446. https://doi.org/10.1016/j.jvoice.2019.11.016
Schmelzle, J. (2014). 5 Rules for explaining things simply. https://simpleshow.com/wp-content/uploads/2017/02/Whitepaper_UK.pdf (02.10.2023)
Sick, S. (2019). Stimmstörungen bei Lehrkräften und Lehramtsstudierenden. Sprechen. Zeitschrift für Sprechwissenschaft 67, 67–94. http://www.bvs-bw.de/SPRECHEN/sprechen_67_2019_1.pdf (02.10.2023).
Voigt-Zimmermann, S. (2011). Zum Einfluss gestörter Lehrerstimmen auf den Verstehensprozess bei Schülern. In I. Bose & B. Neuber (Hrsg.), Interpersonelle Kommunikation: Analyse und Optimierung. Hallesche Schriften zur Sprechwissenschaft und Phonetik 39. (S. 269–275). Peter Lang.
Weitere Quellen
Asynchroner Kurs 2021 = Arbeitsbereich Kommunikation und Stimme (2021). LSQ Kommunikation und Stimme – asynchron digital. Asynchroner Kurs im Modulteil Kommunikation und Stimme des Lehramtsspezifischen Schlüsselqualifikationsmoduls Kommunikation, Heterogenität und Inklusion (LSQ-Modul). Arbeitsbereich Kommunikation und Stimme am Zentrum für Lehrer*innenbildung der Martin-Luther-Universität Halle-Wittenberg. https://cloud.uni-halle.de/s/pw4ujVtdiEoB8su (02.10.2023)
Evaluationsbericht 2021 = Bereich Evaluation (2021). Bericht zur Lehrveranstaltungsevaluation LSQ (A) asynchroner Kurs im Sommersemester 2021. Bereich Evaluation am Prorektorat für Studium und Lehre der Martin-Luther-Universität Halle-Wittenberg, Halle. https://cloud.uni-halle.de/s/XpKoDAsTxvo3BJF (02.10.2023)
KSH 2020 = Körper·Stimme·Haltung. https://koerperstimmehaltung.zlb.uni-halle.de/ (02.10.2023)
Portfolio 2022 = Arbeitsbereich Kommunikation und Stimme (2022). LSQ Kommunikation und Stimme – asynchron digital. Portfolio im Modulteil Kommunikation und Stimme des Lehramtsspezifischen Schlüsselqualifikationsmoduls Kommunikation, Heterogenität und Inklusion (LSQ-Modul). Arbeitsbereich Kommunikation und Stimme am Zentrum für Lehrer*innenbildung der Martin-Luther-Universität Halle-Wittenberg. https://cloud.uni-halle.de/s/MyOxJuRmaWnCdZk (02.10.2023)
Autorinnen

© Uni Halle / Maike Glöckner
Maria Luise Gebauer
Maria Luise Gebauer ist Sprechwissenschaftlerin und arbeitet als Lehrkraft für besondere Aufgaben am Zentrum für Lehrer*innenbildung der Martin-Luther-Universität Halle-Wittenberg im Bereich Kommunikation und Stimme. Sie ist autorisierte Linklater-Stimmtrainerin (Designated Linklater Teacher). Ihre Arbeitsschwerpunkte und Forschungsinteressen sind: Stimmfeldmessung, Körper- und Stimmarbeit, wertschätzende Gesprächsführung sowie Feedback in Lehr-Lernsituationen.
Arbeitsort: Halle
E-Mail: luise.gebauer@zlb.uni-halle.de
Postanschrift: Martin-Luther-Universität, Zentrum für Lehrer*innenbildung, Dachritzstr. 12, 06108 Halle

© Maxi Mercedes Grehl
Maxi Mercedes Grehl
Maxi Mercedes Grehl ist Sprechwissenschaftlerin, arbeitet am Zentrum für Lehrer*innenbildung an der Martin-Luther-Universität Halle-Wittenberg und ist dort gemeinsam mit ihren Kolleginnen verantwortlich für das Seminar Kommunikation und Stimme. Sie war maßgeblich an der Konzeption und Durchführung des Onlinekurses Körper·Stimme·Haltung beteiligt. Freiberuflich arbeitet sie als Kommunikationstrainerin, Theaterpädagogin und systemische Beraterin.
Arbeitsort: Halle
E-Mail: maxi.grehl@zlb.uni-halle.de
Postanschrift: Martin-Luther-Universität, Zentrum für Lehrer*innenbildung, Dachritzstr. 12, 06108 Halle

© Uni Halle / Maike Glöckner
Friderike Lange
Dr. Friderike Lange hat in Halle Sprechwissenschaft studiert und wurde dort 2015 promoviert. Sie arbeitet als Lehrkraft für besondere Aufgaben am Zentrum für Lehrer*innenbildung der Martin-Luther-Universität Halle-Wittenberg im Bereich Kommunikation. Ihre Arbeitsschwerpunkte und Forschungsinteressen sind: Stimme und Stimmgesundheit von Lehrkräften, Standardaussprache, Kommunikation und Feedback als Haltung.
Arbeitsort: Halle
E-Mail: friderike.lange@zlb.uni-halle.de
Postanschrift: Martin-Luther-Universität, Zentrum für Lehrer*innenbildung, Dachritzstr. 12, 06108 Halle
Kontakt
„Sprechen & Kommunikation – Zeitschrift für Sprechwissenschaft“ wird herausgegeben von der Deutschen Gesellschaft für Sprechwissenschaft und Sprecherziehung e. V.
Erschienen am: 26.10.2023

Interaktive Feedbackleistungen in der digitalen und avatargestützten Aphasietherapie
Im Beitrag geht es um ein Forschungsprojekt zur Digitalisierung der Aphasietherapie. Kernidee ist die interaktive Rahmung durch einen virtuellen Übungsbegleiter, einen Avatar. Zentraler Forschungsgegenstand sind die kommunikativen Anforderungen, die sich aus dem digitalen Setting und der interaktiven Rahmung des Übungs- und Teletherapietools ergeben. Dazu wird exemplarisch eine Einzelfallanalyse einer Übungssequenz vorgestellt, die Formen und Funktionen therapeutischen Feedbacks in den Blick nimmt.
– eine Projektdarstellung und Fallanalyse
von Judith Pietschmann, Julia Werth, Josephin Voigt, Christoph Birke
Schlüsselwörter
Aphasie, Teletherapie, Avatar, therapeutische Interaktion, therapeutisches Feedback
Zusammenfassung
Dieser Beitrag gibt einen Einblick in ein aktuelles Forschungsprojekt zur Digitalisierung der Aphasietherapie, das die Entwicklung einer All-in-one-Lösung für das häusliche Üben (Eigentraining), den Live-Einsatz in der analogen Therapie und für die Tele-Therapie anstrebt. Kernidee ist die interaktive Rahmung durch einen virtuellen Übungsbegleiter einen Avatar. Zentraler Forschungsgegenstand sind die spezifischen kommunikativen Anforderungen, insbesondere die kommunikative ‘Funktionalität’ in Bezug auf Feedbackleistungen durch den Avatar, die sich aus dem digitalen Setting und der interaktiven Rahmung des Übungs- und Teletherapietools ergeben. Dazu wird exemplarisch eine sequenzielle Einzelfallanalyse einer Übungssequenz aus einer Aphasietherapie-Sitzung vorgestellt, die Formen und Funktionen therapeutischen Feedbacks in den Blick nimmt. Konkret geht es in der Ergebnisdarstellung und -interpretation um die mögliche Übertragung von Feedbackleistungen auf den Avatar und das digitale Setting.
Keywords
aphasia, teletherapy, avatar, therapeutic interaction, therapeutic feedback
Abstract
This article gives insight into a current research project on the digitalization of aphasia therapy. Its goal is to develop an app, which gives an all-in-one-solution for aphasia patients to home practice, to use in analogue therapy sessions and further to implement teletherapy. The project’s central idea for the app is the interactive framing by an avatar. The central object of research are the specific communicative requirements, especially the communicative functionality regarding feedback services provided by the avatar, resulting from the app’s digital setting and interactive framing. A sequential analysis of an analogue conversation in a speech therapy is presented, which looks at forms and functions of therapeutic feedback. Specifically, this article depicts possibilities of transferring forms of feedback onto the avatar and into the digital setting.
1 Einführung – Digitalisierung in der Sprachtherapie
Der demografische Wandel stellt die Gesundheitsversorgung in Deutschland derzeit vor große Herausforderungen: Eine wachsende Gesellschaftsgruppe älterer, therapie- und/oder pflegebedürftiger Menschen trifft auf den Fachkräftemangel in der Gesundheits- und Pflegebranche. Diese in strukturschwachen Regionen besonders akute Situation betrifft auch den Bereich Sprachtherapie/Logopädie, und der Ruf nach digitalen Versorgungskonzepten wird auch hier immer lauter.
Dass die Digitalisierung in der sprachtherapeutischen Versorgung dringend notwendig ist, wird unter Corona-Bedingungen mehr als deutlich. Die Ergebnisse einer Online-Befragung zum Stand der Umsetzung von Teletherapie im Zusammenhang mit der Covid-19-Pandemie (Bilda et al., 2020) belegen eine sehr hohe Akzeptanz bei den befragten Logopäd:innen. Demnach gilt für einen Großteil der Befragten die Teletherapie als das Versorgungsmodell der Zukunft.
„Akzeptanz und Offenheit für digitale Gesundheitsanwendungen in Form von Teletherapie sind bei den Gesundheitsberufen, PatientInnen und ReguliererInnen wie den Krankenkassen quasi über Nacht entstanden. Wir erleben den Beginn einer digitalen Transformation der Gesundheitsversorgung.“ (Bilda et al., 2020, S. 176).
Zugleich fordern Logopäd:innen und Sprachtherapeut:innen eine systematische Konzeption sprachtherapeutischer Teletherapie, bei der neben inhaltlichen Rahmenbedingungen v. a. auch technische und datenschutzrechtliche Anforderungen und Standards definiert und beschrieben werden (Bilda et al., 2020, S. 176; zum DSGV-konformen Datenschutz von Patienten- und Patientinnendaten siehe auch Jakob & Späth, 2021). Das digitale Angebot, insbesondere in Form von Apps und Softwareprogrammen, ist zwar inzwischen breit aufgestellt, jedoch von einer systematischen digitalen Versorgungskonzeption weit entfernt. Die Auswahl der Teletherapie- bzw. Konferenz-Software obliegt den Therapeut:innen (Bilda et al., 2020, S. 180). Hier gibt es bisher keine Standardlösung, die sowohl Datensicherheit gewährt und zugleich den technischen Anforderungen an das multimodale Therapiesetting gewachsen ist.
Mit dem Projekt Aphasietherapie digital – Entwicklung einer digitalen sprachtherapeutischen Versorgung (aphaDIGITAL) setzen wir an diesen und anderen Missständen der sprachtherapeutischen Versorgungssituation in Deutschland – insbesondere in Mitteldeutschland – an. Die von den eingangs zitierten Autor:innen beschriebene „digitale Transformation der Gesundheitsversorgung“ (Bilda et al., 2020, S. 176) scheint imstande, die im Bereich der Sprachtherapie grundlegenden Versorgungslücken zu schließen, unter denen Patient:innen und Therapeut:innen vielerorts leiden: Der allseits beklagte Fachkräftemangel, eine ausgesprochen schlechte Versorgungssituation gerade in ländlichen und strukturschwachen Regionen, Wartezeiten mit zu geringer Therapiefrequenz und die durch den demografischen Wandel stets steigende Zahl an Patienten und Patientinnen sind Defizite, welche die sprachtherapeutische Versorgung derzeit beschreiben (TDG, 2018, S. 11; Bilda, 2017a, S. 21; Bilda, 2017b, S. 84; Rupp, 2010, S. 63; Richter, 2015, S. 11).
Gerade im Bereich der neurologischen Störungen und insbesondere dem Störungsbild der Aphasie führen die genannten Faktoren mittel- und langfristig zu einer Gefährdung des Therapieerfolgs: Unzureichende Therapiefrequenz, belastende Fahrtwege (besonders in der Situation nach einem Schlaganfall) und das Verlassen des gewohnten häuslichen Umfelds sind nur einige der Faktoren, die sich erfolgskritisch auswirken (Bilda et al., 2020, S. 181–182).
Mit Blick auf das bestehende, zumeist therapieunterstützende digitale Angebot für die Aphasietherapie wird deutlich, dass dieses oft nur eingeschränkt-funktional und v. a. nicht ganzheitlich und den ICF-Kriterien (ICF – International Classification of Functioning, Disability an Health) gemäß konzipiert ist. Auch hier setzt das Projekt an, bei dem wir in einem ersten Schritt mit einem virtuellen Übungsbegleiter (Avatar) ein interaktives, digitales Übungssetting schaffen wollen. Im zweiten Schritt soll das digitale Übungssetting um eine Teletherapie-Komponente erweitert werden.
Im vorliegenden Beitrag zeigen wir an einem Fallbeispiel aus dem Bereich der Aphasietherapie anhand einer sequenziellen Gesprächsanalyse einer Übungssequenz, wie und mit welchen Mitteln (interaktiven Ressourcen) die Therapeutin im konkreten Fall ergebnisorientiertes und motivierendes Feedback gibt. Die Forschungsfrage lautet: Wie treten ergebnisorientiertes und motivierendes Feedback jeweils multimodal in Erscheinung, und welche dieser Erscheinungsformen lassen sich auf den Avatar oder das digitale Setting übertragen?
Wir nähern uns diesem Untersuchungsgegenstand aus unterschiedlichen Perspektiven. Zusammengeführt werden dabei die sprachtherapeutisch-klinische Expertise mit der Perspektive von Gesprächsforscher:innen mit sprechwissenschaftlicher Schwerpunktsetzung als auch die erfahrungsbasierte Perspektive der logopädisch-/sprachtherapeutischen Praxisarbeit.
Im Artikel folgt zunächst (Kap. 2) eine Einordnung und Darstellung des Forschungsprojektes aphaDIGITAL. Das interaktive Setting ist die Kernidee des Projektansatzes und zwingt zu einer theoretischen Auseinandersetzung und Konzeption interaktiver ‘Kompetenzen’, mit denen der Avatar als virtueller Übungsbegleiter ausgestattet werden soll (Kap. 3). Dabei wird insbesondere das Feedback als ein zentraler Bestandteil therapeutischer Kompetenz herausgegriffen und näher beleuchtet. Im vierten Kapitel zeigen wir anhand einer gesprächsanalytisch-sequenziellen Fallanalyse zweier kurzer Interaktionssequenzen, wie wir uns empirisch der Bestimmung und Beschreibung interaktiver Kompetenzen, insbesondere der Feedbackleistungen zu nähern versuchen. Den Abschluss des Artikels bildet die Darstellung der Analyseergebnisse (Kap. 5) und ein Fazit zur Anwendung dieser Ergebnisse auf die Konzeption der interaktiven ‘Funktionen’ des Avatars (Kap. 6).
2 Forschungsprojekt aphaDIGITAL
Das Vorhaben Aphasietherapie digital (aphaDIGITAL) setzt als Forschungs- und Entwicklungs-Projekt an der prekären sprachtherapeutischen Versorgung v. a. in ländlichen Regionen an. Es ist eingebunden in das Modellprojekt Translationsregion für digitalisierte Gesundheitsversorgung (TDG, o. D.) der Medizin und Pflegewissenschaft der Martin-Luther-Universität Halle-Wittenberg. Als regionales Strukturwandelprogramm ist das TDG-Projekt am Bundesministerium für Bildung und Forschung (BMBF) im Rahmenprogramm WIR! (Wandel durch Innovation in der Region) angesiedelt (Innovation & Strukturwandel – WIR!, o. D.). Das Ziel des aphaDIGITAL-Projektes liegt in der flächendeckenden und hochfrequenten therapeutischen Versorgung innerhalb der TDG-Modellregion (TDG-Report 2018), die sich durch eine Verbesserung des Therapieerfolgs auch teilhabeförderlich auswirkt.
Das Projekt ist im November 2021 offiziell gestartet und hat eine Laufzeit von drei Jahren. Neben der Sprechwissenschaft besteht das Projektteam aus Mitarbeiter:innen der Wirtschaftsinformatik der TH-Wildau (https://www.th-wildau.de/mathias-walther/), einem IT-Partner aus dem Bereich VR- und Multimedia-Design, der Swinging Lama UG (https://swinging-lama.de/) sowie aus Praxispartnern der Logopädie und Sprachtherapie, darunter auch die Logopädieschule des Universitätsklinikums in Halle (UKH).
2.1 Zielstellung
Das digitale Setting von aphaDIGITAL mit seinen Komponenten für das avatargestützte Eigentraining und die Teletherapie strebt eine All-in-one-Lösung an, die flächendeckend für die Aphasietherapie genutzt werden kann. Eine hochfrequente Übungsbehandlung ist nachgewiesenermaßen essenziell für den Therapieerfolg und fördert die kommunikative Teilhabe der Patient:innen. Die zu entwickelnden digitalen Therapielösungen sollen dazu beitragen, eine frühzeitige, bedarfsgerechte und individuelle sprachtherapeutische Versorgung zu gewährleisten und damit langfristig den Therapieerfolg zu sichern. Das Projektvorhaben beinhaltet folgende digitale Komponenten:
a) aphaTRIA: Entwicklung eines avatargestützten Übungsszenariums (App) via Tablet
b) aphaTHERA: Erweiterung der App um eine Tele-Therapiefunktion zur dezentralen Versorgung
Die Anleitung und Unterstützung bei der Übungsdurchführung durch einen Avatar bilden die Kernidee des Projektes. Der Avatar soll neben interaktiven auch minimal-therapeutische Funktionen (z. B. in Form von Anlauthilfen und Mundbild zur Unterstützung des Wortabrufes) übernehmen. Er führt interaktiv durch die Übungssessions und wird so zum virtuellen Übungsbegleiter. Bei der Durchführung der Aufgaben übernimmt er Rückmeldefunktionen und gibt wertschätzendes und motivierendes Feedback. Je nach Übungsverlauf soll er an die Patient:innen angepasste Vorschläge für die nächsten Übungen machen können. Die Daten zu Übungsfrequenz und -verlauf stehen als Patientenfeedback zur Verfügung und dienen Sprachtherapeut:innen zur Einschätzung des Therapieerfolges und zur Planung des weiteren Verlaufs. Therapeut:innen sind also stets eingebunden in das häusliche Üben, können Übungsstatistiken abrufen, Übungen und Übungsmaterial individuell zusammenstellen und so die Übungsinhalte und Schwierigkeitsstufen individuell anpassen. Die triadische Beziehung zwischen Patient:in, Therapeut:in und Avatar sichert eine therapeutisch begleitete Übungsumgebung. Die angestrebte Integration von KI (in Kombination aus Sprach- und Mimikerkennung) dient dem analytischen Feedback über die Qualität der Übung.
Mittels aphaTRIA sollen Patient:innen frühzeitig an die Hard- und Software herangeführt werden, um das tele-therapeutische Arbeiten via aphaTHERA anzubahnen und Hemmschwellen in Bezug auf Technikeinsatz abzubauen. Durch den direkten Kontakt per Videokonferenz wird die therapeutische Beziehung aufrechterhalten und findet eine Orientierung an den individuellen Bedürfnissen und Echtzeitreaktion statt (Bilda, 2017a, S. 22; Bilda, 2017b, S. 84; Wahl, 2018, S. 58–59; Huml, 2014, S. 11).
2.2 Forschungsgegenstände
Mit den hohen Anforderungen und Zielsetzungen in Bezug auf Funktionalität, KI-Technologie, Bedienbarkeit und Design, die sich aus der Störungsspezifik für die Konzeption des digitalen All-in-one-Tools ergeben, sind die Forschungsthemen und -aufgaben innerhalb des Projektes ausgesprochen breit aufgestellt und involvieren alle sprechwissenschaftlichen Teilbereiche. Neben dem App- und Übungsdesign liegt das Hauptaugenmerk in der Forschung v. a. in einer systematischen und empirisch fundierten Beschreibung des interaktiv-therapeutischen Handelns in der analogen Aphasietherapie und deren konzeptioneller Übertragung auf die digitale Übungsumgebung. Ziel ist es, das Interaktionsverhalten des virtuellen Übungsbegleiters entsprechend dieser Erkenntnisse zu modellieren. In der Gesamtschau befasst sich die Forschungsarbeit mit den nachfolgend skizzierten Forschungsgegenständen.
2.2.1 Interaktive Übungsumgebung, App- und Avatar-Design
An den Spezifika des Störungsbildes Aphasie, der Therapie sowie den grundlegenden ICF-Dimensionen ansetzend, müssen die spezifischen Anforderungen für die mediengestalterische, technische und inhaltlich-konzeptionelle Umsetzung der digitalen Lösungen definiert werden. Damit geraten Fragen nach der multimodalen Erfassung und Abbildung der Kommunikationsleistungen ebenso in den Blick wie Fragen nach der sprechrollen-angemessenen Avatar-Modellierung (z. B. in äußerer Erscheinung, der Stimme und Sprechweise und der interaktiven ‘Funktionalität’). Konkrete Fragestellungen betreffen hier z. B. die stimmliche und regiolektale Konfigurierbarkeit der Avatar-Stimme, die äußere Erscheinung oder das Geschlecht. Wie eine Studie von Rieke (2013, zitiert nach Malchus, 2015) zum Einsatz von Robotern in der Therapie neurologischer Störungen zeigt, favorisieren insbesondere (männliche) Patienten den Einsatz eines mit weiblichen Features ausgestatten Roboters (Malchus, 2015, S. 91). Inwieweit sich diese Befunde auch auf das digitale Setting und das Avatar-Modell übertragen lassen, muss in entsprechenden Untersuchungen geklärt werden.
2.2.2 Interaktionstheoretische Konzeption von Avatar und Übungssetting
Zentraler Forschungsgegenstand ist die interaktionstheoretisch begründete Konzeption und Modellierung des virtuellen Übungssettings samt -begleitung. Dies betrifft zum einen die interaktive Rahmung der gesamten Übungssitzung, zum anderen die Rahmung jeder einzelnen Übung. Ausgehend von der therapeutischen Arbeitsweise im klassischen Therapiesetting müssen Anforderungen an das digitale Übungsszenarium definiert werden. Die interaktionstheoretische Konzeption, Modellierung und Funktionalität des Avatars muss hinsichtlich rollenadäquater, sprachtherapeutischer, pragmatischer und phatischer Funktionen und Anforderungen erfolgen und auch motivationale Aspekte bei der Übungsdurchführung in den Blick nehmen. Zentral sind hier u. a. Fragen nach den unterschiedlichen Formen und Funktionen von Feedback und wertschätzend-motivationalen Kommunikationsweisen im therapeutischen Handlungskontext, die auf das digitale Setting übertragen werden können (Kap. 4).
2.2.3 Übungskonzeption und -material, Hilfestufen und Lösungspfade
Einen weiteren Gegenstand der Projektarbeit stellt die inhaltlich-konzeptionelle Umsetzung der Therapiebausteine dar. Dies beinhaltet die Übungskonzeption in Bezug auf Aufgabenformate, Aufgabenstellungen, Zusammenstellung von Aufgabenkomplexen und Storyboards mit Zielstrukturen, Anforderungs- und Hilfestufen sowie Lösungspfaden für alle Sprachmodalitäten (Rezeption und Produktion: Lesen, Hörverstehen, Schreiben und Sprechen). Zugleich muss das digitale Übungsmaterial erstellt werden. Hier sind insbesondere die Hilfs- und Unterstützungsfunktionen des virtuellen Übungsbegleiters zu planen und einzuspeisen. Das heißt, das mimische und sprachliche Material inklusive der Artikulationsbewegungen für die Anlauthilfen müssen per Motioncapturing abgenommen werden. Darüber hinaus sind spielerische und motivationsfördernde Elemente in die Übungskonzeption einzubauen (Gamification), die Anreiz-, Belohnungs- und Kontrollfunktionen angemessen abbilden und in motivierender Weise zusammenwirken.
Die Übungskonzeption für das digitale Szenario erfolgt in einem iterativen Test- und Evaluationsprozess, in den (angehende) Therapeut:innen und Logopäd:innen, Patient:innen und Angehörige eingebunden sind (Leinweber & Schulz, 2019, S. 36–39)
2.2.4 Training der KI-Spracherkennung
Einen weiteren Forschungsschwerpunkt des Projektes markiert die Integration der KI-Komponenten als Grundlage für die automatisierte Evaluation von Sprachproduktionsleistungen. Für die Erkennung der mündlichen Produktionsebene (z. B. bei Benennübungen) muss die Spracherkennungskomponente nicht nur auf den Trainingswortschatz, sondern v. a. auf die Aussprachebesonderheiten der Patient:innen trainiert werden, um verlässliche Erkennungsraten generieren zu können. Durch sprechwissenschaftlich-phonetische, d. h. kombiniert auditiv-akustische Analysen und Annotationen soll ein Trainingskorpus als Grundlage für das Maschinen-Lernen erstellt werden. Darüber hinaus soll das Potenzial KI-basierter Mundbild- und Mimikerkennung auf die Verbesserung der Spracherkennung an Testdaten evaluiert werden und auch in Bezug auf die Feedbackleistungen der virtuellen Übungsbegleitung hin untersucht werden. Gerade in Bezug auf Mimikry-basiertes Feedback durch den Avatar, bei dem die Feedbackreaktion immer kongruent zu der Aktion des/der Patient/-in ist (Malchus, 2015, S. 88), ist eine valide Mimikerkennung auch bei eingeschränkter mimischer Aktivität (z. B. bei Hemiparesen) eine wichtige Grundlage. Orientiert man sich an zwei- oder dreidimensionalen Emotionsmodellen, wie dem Geneva Emotion Wheel (GEW) (Bänziger et al., 2012; Scherer, 2005), steht hier eine valide Erkennung der emotionalen Valenz-Dimension im Fokus.
2.2.5 Feldtestung und therapeutische Evaluation
Weitere Aspekte der Projektarbeit sind der Praxistransfer und die Testung sowie Evaluation der digitalen Anwendung durch alle Anwendergruppen (Logopäd:innen, Sprachtherapeut:innen, Patient:innen und Angehörige). Die Testphase soll in kontrollierten Versuchs- und Kontrollgruppenvergleichen durchgeführt werden und bestenfalls den Evidenznachweis zur Anerkennung und Zertifizierung der App als digitale Anwendung (DiGA) über das Bundesinstitut für Arzneimittel und Medizinprodukte (BfArM) erbringen. Im Prüfverfahren muss die App den hohen Anforderungen in Bezug auf Sicherheit, Funktionstauglichkeit, Qualität, Datenschutz, Datensicherheit und medizinischen Nutzen bzw. Verbesserung medizinischer Verfahrens- und Versorgungsstrukturen gerecht werden. Wie Untersuchungen technologischer Entwicklungen und Produkte im Bereich der Sprachtherapie zeigen, ist eine frühe Einbindung der relevanten Nutzergruppen in den Entwicklungsprozess v. a. unter dem Aspekt der Usability für die erfolgreiche Produktentwicklung unbedingt notwendig (Leinweber & Schulz, 2019).
3 Therapeutische Interaktionskompetenzen
Gemäß den zuvor skizzierten Forschungsgegenständen des Projektes wird im Folgenden beispielhaft ein Aspekt aus dem Themenkomplex Interaktionstheoretische Konzeption von Avatar und Übungssetting (s. o.) herausgegriffen und theoretisch-konzeptionell sowie empirisch-analytisch näher betrachtet. Es geht um Formen und Funktionen von Feedback in der sprachtherapeutischen Interaktion und deren mögliche Übertragung auf das digitale Szenarium. Dabei gerät zunächst die Frage in den Blick, warum wir uns vom Kommunikationsbegriff ab- und dem Interaktionsbegriff zuwenden. Nach dieser begrifflichen Verortung werden zentrale Interaktionskompetenzen in der Sprach- und Aphasietherapie dargestellt. Auf die Bedeutung von Feedback als zentrale kommunikative Praktik in der Therapie wird im Anschluss näher eingegangen.
Kapitel vier nimmt dann eine exemplarische Analyse zu Formen und Funktionen von Feedback in einer konkreten Therapiesituation vor. Diese Falldarstellung soll hier v. a. das methodische Vorgehen bei der Analyse der Interaktionsleistungen, konkret der Feedbackleistungen, im therapeutischen Setting nachzeichnen. Die Ergebnisse und Überlegungen zur Übertragbarkeit auf das digitale Übungsszenarium und die Avatar-Interaktion (Kap. 5 und 6) sind daher als erste Ideen, nicht aber als gesicherte Ergebnisse mit breiter empirischer Datenbasis zu betrachten.
3.1 Kommunikation und Interaktion – zwei Perspektiven auf einen Gegenstand
Das sprachtherapeutische Behandlungsparadigma hat sich in den letzten 20 Jahren grundlegend verändert. Partizipation, aktive Mitbeteiligung und Einbezug von Patient:innen in den Therapieprozess sind Maximen des therapeutischen Handelns und spiegeln sich u. a. in der Anwendung der ICF, Clinical Reasoning und Shared Decision Making wider (Lange, 2012, S. 13–14). Insofern erscheint es sinnvoll und sogar notwendig, den Interaktionsbegriff stärker im sprachtherapeutischen Handlungsfeld zu etablieren.
In der sprechwissenschaftlichen Tradition steht der Kommunikationsbegriff bis heute zentral. Dies gilt nicht nur für die v. a. durch Hellmut Geißner begründete Rhetorik (rhetorische Kommunikation), sondern auch für die anderen Bereiche des Faches (sprechkünstlerische Kommunikation, therapeutische Kommunikation). Beide Begriffe, Interaktion und Kommunikation, weisen eine große gemeinsame Schnittmenge auf und fallen – jedoch mit jeweils anderem Fokus – grundsätzlich zusammen (Schmidt, 2018). Während der Kommunikationsbegriff die dem Einzelakt zugeschriebene Mitteilungsabsicht und die damit verbundene Zeichenverwendung zentral setzt, fokussiert der Interaktionsbegriff das, was auf der Ebene der Wahrnehmung zwischen zwei oder mehreren Akteuren passiert und dabei der Koordination von Verhalten bzw. konkreten Sprechhandlungen dient (Schmidt, 2018, S. 17). Das Aufeinander-Bezug-Nehmen in (Sprech-)Handlungen steht hierbei im Kern des begrifflichen Konzeptes. So wird das, was in wechselseitiger Orientierung ‘zwischen’ den Handlungen passiert und der Koordination von Verhalten dient, zentral gesetzt.
„Im Kern des Interaktionsbegriffs ist die wechselseitige Aufeinander-Bezogenheit von Handlungen. Im Fokus ist, was zwischen (Inter-) Handlungen (-aktionen) geschieht und damit der Prozess, der entsteht, wenn Handlungen sich aufeinander beziehen.“ (Schmidt, 2018, S. 17)
Beides, intentionale Sprach- bzw. Zeichenverwendung (gedankliche Ko-Orientierung im Konzept von Kommunikation) und die Wechselseitigkeit in Wahrnehmung und Ausrichtung (körperlich-zeichenhafte Orientierung und Koordination in der Interaktion) fallen in Gesprächen zusammen. Insofern ist die Schnittmenge von Kommunikation und Interaktion eine gemeinsame. Differenz ist jeweils der Fokus auf die ‘Leistungen’ dieses gemeinsam hergestellten und aufeinander orientierten Austausches.
Da der Kommunikationsbegriff die gemeinsame (aber auch individuelle) Zielorientierung, d. h. das Einwirken auf andere durch die Vermittlung von Informationen in den Mittelpunkt der Konzeption rückt, steht er als Abbild des sprechwissenschaftlichen Selbst- und Gegenstandsverständnisses zentral in der Fachterminologie. In dieser Lesart findet ein wirkungsvoll-intentionaler, Zweck-Mittel-orientierter und wechselseitig gerichteter Austausch nicht nur im Felde des Rhetorischen, sondern auch allen anderen sprechwissenschaftlichen Teilbereichen statt, eben auch in der therapeutischen Kommunikation. Für die Abbildung der in Kap. 2.2 dargestellten Forschungsgegenstände und der damit verbundenen Forschungsfragen scheint jedoch der Interaktionsbegriff besser geeignet. Die Gründe, die für die Zuwendung zum Interaktionsbegriff sprechen, seien hier kurz benannt:
Die (vermutlich gemeinsame) Intention scheint im analogen, v. a. aber im digitalen Übungssetting vergleichsweise festgeschrieben. Therapeut:in, (sein/ihr) Avatar und Patient:in wollen gemeinsam üben, um Fortschritte zu erzielen, die die kommunikative Teilhabe der Patient:innen ermöglicht und fördert. Damit ist das ‘Wozu’ bzw. die kommunikative Absicht auch durch das digitale Setting mit Aufgabenformaten und Übungen gesetzt und bedarf keiner Aushandlung oder Schwerpunktsetzung, wie es der Kommunikationsbegriff nahelegt.
Der Avatar muss mit grundlegenden multimodalen Funktionen ausgestattet werden, die nicht nur (Sprech-)Rollen- und Setting-adäquat zu bestimmen sind, sondern die zugleich einen Bezug zu den Sprachproduktionsleistungen der Patient:innen herstellen lassen und auf diese, so gut als möglich, zugeschnitten sind. Damit rückt das, was auf der Oberfläche der Wahrnehmung ‘zwischen’ Patient:in, Tablet und Avatar passiert, in den Fokus. Insbesondere hierin zeigt sich die Nähe zum Interaktionsbegriff, der im Folgenden Verwendung findet.
3.2 Therapeutische Kompetenzen und Grundhaltung – ein Kurzüberblick
Die Anforderungen an Therapeut:innen und deren kommunikative Kompetenzen sind vielfältig. Zusätzlich zur Fachkompetenz ist es wichtig, dass sie zugleich auch als „Beraterin, Zuhörerin und unterstützende, motivierende Begleiterin im Gesundungsprozess von Patienten“ (Herter-Ehlers, 2020, S. 8) agieren. Die Fähigkeit zu einer effektiven Kommunikation und zu psychosozialer Empathie ist dabei kein angeborenes Talent, sondern muss erlernt werden (Dehn-Hindenberg, 2008, S. 59).
Die sprachtherapeutische Interaktion umfasst zunächst zwei grundlegende Kompetenzbereiche (Lange, 2012, S.13): Zum einen werden konkrete Übungen und Maßnahmen durchgeführt, die der Linderung der Symptome von Patient:innen dienen sollen. Zum anderen ist die Prozessbegleitung ein grundlegender Aspekt sprachtherapeutischen Arbeitens. Prozessbegleitung meint z. B. die Unterstützung bei der Krankheitsverarbeitung, die Beratung von Angehörigen, die Vermittlung therapierelevanter Informationen, therapeutisches Ratgeben, Anleitungen für das häusliche Üben und vieles andere mehr. In beiden Bereichen ist die Qualität der Interaktion zwischen Therapeut:in und Patient:in von zentraler Bedeutung für die Bewältigung der Beeinträchtigung und beeinflusst den Therapieerfolg maßgeblich (Dehn-Hindenberg, 2010, S. 19). Damit rücken neben der Sach- und Methodenkompetenz von Therapeut:innen (Eckert, 2006, S. 91; Homburg & Lüdtke, 2003, S. 146) auch die kommunikativen und sozial-emotionalen Kompetenzen in den Fokus (Homburg & Lüdtke, 2003; Herter-Ehlers, 2020). Die kommunikativen Kompetenzen von Therapeut:innen werden in der Aphasietherapie auf besondere Weise beansprucht, da Kommunikation hier sowohl Gegenstand der Therapie selbst ist und darüber hinaus auch zur Vermittlung von Therapieinhalten und Zielen dient (Herter-Ehlers, 2020, S. 24).
Als Gütekriterien der Interaktionsqualität und damit grundlegend für den Therapieerfolg gelten in sozial-emotionaler Dimension die folgenden Aspekte (Sachse, 2016; Tuschy-Nitsch & Spiecker-Henke, 2014; Eckert, 2006; Büttner & Quindel, 2005; Lüdtke, 2004; Homburg & Lüdtke, 2003):
angemessener Umgang mit Nähe und Distanz, Symmetrie und Asymmetrie in der therapeutischen Beziehung,
Kongruenz im Ausdrucksverhalten der Therapeut:innen
emotionale Qualität der Beziehungsebene, die u. a. durch gegenseitige Akzeptanz geprägt sein sollte, interaktiv hergestellt wird und insbesondere das subjektive Wohlempfinden der Patient:innen beeinflusst,
offen-verstehende, wertungsfreie Grundhaltung,
therapeutische Grundhaltung: Echtheit, Empathie, Akzeptanz,
Empathie und emotionales Verstehen.
Die hier angesprochene emotionale Kompetenz schließt die Fähigkeiten ein, Emotionen der Patient:innen zu erkennen, darauf empathisch zu reagieren und eigene Emotionen multimodal ausdrücken zu können, und ist grundlegend für den Beziehungsaufbau (vgl. Homburg & Lüdtke, 2003). Therapeut:innen benötigen daher ein großes Repertoire kommunikativer Strategien, um Störungen auf der Beziehungsebene zu bemerken und daraus ggf. resultierende Konflikte zu lösen. Eine ausgeprägte Empathiefähigkeit sowie die Bereitschaft und Kompetenz, die emotionale Verfasstheit von Patient:innen angemessen interaktiv zu bearbeiten, muss in der therapeutischen Gesprächspraxis in konkrete Empathieangebote (s. u.) münden. Erst damit erlangt das Empathievermögen der Behandelnden den Stand einer kommunikativ-emotionalen Kompetenz, die aktiv in den Gesprächs- und Therapieprozess eingesteuert werden kann.
Das Aufzeigen des Anerkennens der emotionalen Situation des Gegenübers und der Bereitschaft zur weiteren Thematisierung dessen kann also als Darstellung von Empathie interpretiert werden. Dieses Erkennen der Notwendigkeit des interaktionalen Be- bzw. Aushandelns der emotionalen Situation des Anderen wird von Pfänder/Gülich (2013) auch als ‘Empathieangebot’ beschrieben. (Kupetz, 2015, S. 34-35)
Die Abbildung kommunikativer Kompetenzen führt in der Literatur häufig zur Darstellung konkreter Techniken der Gesprächsführung (Büttner & Quindel, 2005), die aber z. T. wenig spezifisch zugeschnitten scheinen. ‘Paraphrasieren’ und ‘Nachfragen’ oder das ‘Stellen offener Fragen’ zählen wohl eher zu den allgemeinen Standards in der therapeutischen Interaktion und markieren noch keine spezifisch sprachtherapeutischen Kompetenzen, schon gar nicht im Umgang mit Aphasiker:innen. Im Rahmen der Projektarbeit wurde daher eine breit angelegte Befragung durchgeführt, die erhebt, welchen Stellenwert Sprachtherapeut:innen und Logopäd:innen selbst den verschiedenen Aspekten kommunikativer Kompetenzen in der Aphasietherapie einräumen (Einhorn, 2021). Erhoben wurden die drei Kategorien (Einhorn, 2021, S. 94–100):
Kommunikation mit Patient:innen
Beziehungsgestaltung
Therapeut:innen-Patient:innen-Beziehung
Innerhalb jeder dieser Kategorien wurden konkrete Strategien und Gesprächstechniken nach deren Relevanz abgefragt. Hintergrund der Untersuchung ist die Übertragung grundlegender interaktiver Funktionen, die speziell auf das Störungsbild der Aphasie zugeschnitten sind, auf den Avatar. Die Befragten (n=123) gaben die folgenden Items als außerordentlich bedeutsam in der Aphasietherapie an (Einhorn, 2021, S. 94–100):
Geduld, Warten auf die Antwort bzw. lange Pausen für die Antwort lassen,
Wiederholen von Wörtern und Äußerungen bei Verständnisproblemen sowie aktive Verständnissicherung,
einfache, kurze und anschauliche Formulierungen,
Blickkontakt sowie aktive Nutzung von Mimik, Gestik und Betonung, deutliches Mundbild,
positives Feedback.
Neben diesen sehr konkreten kommunikativen Strategien lässt sich allerdings fragen, welche Indikatoren auf übergeordneter Ebene kommunikative Kompetenz anzeigen. Auf diese Frage liefert die Untersuchung von Einhorn (2021) keine Antwort. Die Literaturlage zeichnet hier v. a. folgendes Bild (z. B. Sachse, 2016; Tuschy-Nitsch & Spiecker-Henke, 2014; Eckert, 2006; Büttner & Quindel, 2005; Lüdtke, 2004; Homburg & Ludtke, 2003):
Zuhören, Verständnissicherung und kommunikative Rückkopplung,
Initiieren, Anleiten von Aufgaben und Übungen und deren interaktive Bearbeitung im Therapieverlauf,
Initiierung von Dialogen, Spontangesprächen und -äußerungen,
Sicherung und Förderung der Gesprächsbereitschaft trotz eingeschränkter Ausdrucksmöglichkeiten der Patient:innen,
Finden einer gemeinsamen Sprachebene und Adressatenzuschnitt,
Konfliktmanagement und Metakommunikation,
explizite Kooperativität (siehe dazu auch Fiehler, 1999),
motivierendes, imageschonendes Feedback.
Formen und Funktionen von Feedback in der therapeutischen Interaktion werden in den weiteren Ausführungen vertiefend betrachtet, da die Rückmeldung durch den/die Therapeut:in eine entscheidende Rolle für den Lernfortschritt spielt (Schmidt et al., 2014, S. 181).
3.3 Feedback in der sprachtherapeutischen Interaktion
Rückmeldungen übernehmen in der therapeutischen Interaktion ganz unterschiedliche Funktionen. Diese reichen von der einfachen Ergebnisbestätigung oder Korrektur über Motivation und Lob bis hin zum komplexen Ausdruck von Empathie. Mit dieser Funktionsbreite ist zugleich das Spannungsfeld umrissen, das Feedbackprozesse im Allgemeinen und in der therapeutischen Interaktion im Besonderen kennzeichnet: Konstruktion und Destruktion. Das Geben von Rückmeldungen (als Methode, als didaktische Intervention, als therapeutische Hilfestellung usw.) bewegt sich zwischen den Polen ‘Bewerten’ und ‘Beraten’ (Lange, 2021, S. 93-96) bzw. für die Sprachtherapie treffender zwischen ‘Bewerten’ und ‘Motivieren’ oder ‘Ermutigen’.
Ebenso vielfältig wie die Funktionen sind die Formen von Feedback. Geißner (1998) beschreibt Feedback als einen allgemeinen kommunikativen Vorgang der Rückmeldung, der nicht zwangsläufig verbal sein muss (S. 16). Dies legt eine multimodale Perspektive, wie sie in der in diesem Artikel dargestellten exemplarischen Analyse von Feedback-Handlungen eingenommen wird, fast zwangsläufig zugrunde. Gerade im Kontext der therapeutischen Interaktion und mit Bezug auf den Forschungs- und Entwicklungsgegenstand des aphaDIGITAL-Projektes ist die multimodale Erfassung und Beschreibung von Feedbackleistungen von grundlegender Bedeutung. Schließlich soll der/die virtuelle Übungsbegleiter:in angemessen Rückmeldungen auf die Übungsleistungen der Patient:innen geben können, und dies nicht eindimensional verbal, sondern nach Möglichkeit auf allen zur Verfügung stehenden (Animations-)Ebenen. Eine Studie von Hegel et al. (2006) zu digitalem Feedback durch Roboter legt beispielsweise nahe, dass die Anpassung der Mimik (mimicry) an die wahrgenommenen Emotionen (Freude, Angst, Neutralität) einen großen Effekt auf die Akzeptanz und Annahmebereitschaft der Proband:innen hat. Die Roboter mit mimicry wurden insgesamt als sensibler und adäquater wahrgenommen als jene mit neutralem Gesichtsausdruck (Hegel et al., 2006, S. 56–59). Zu ähnlichen Ergebnissen kommen die Untersuchungen von Kühnlenz et al. (2018) und Malchus et al. (2019). Letztere kommen zu dem Schluss:
„Es ist also davon auszugehen, dass verbale und mimische Äusserungen eines Roboters als Feedback einen Einfluss auf das Verhalten der Gesprächspartner haben.“ (Malchus et al., 2019, S. 16).
Im Folgenden werden zunächst die unterschiedlichen Formen von Feedback, die im therapeutischen Kontext Anwendung finden, vorgestellt (Kap. 3.3.1). Diese Klassifikation hilft, die in der Analyse gefundenen Rückmeldeleistungen einzuordnen und ggf. um weitere Formen zu ergänzen. Da der Analysefokus im Fallbeispiel insbesondere auf Erscheinungsformen des ergebnisorientierten Feedbacks liegt, wird dies in Kapitel 3.3.2 vertiefend dargestellt.
3.3.1 Formen von Feedback im therapeutischen Kontext
Feedback in der Sprach- und Aphasietherapie soll Patient:innen „orientieren und an das zu erreichende Ziel heranführen“ (Ritterfeld & Hastall, 2017, S. 52). Es soll aber auch in allen Facetten motivieren, z. B. durch Ermuntern, Aufheitern und Ermutigen. So wird im therapeutischen Kontext grundsätzlich zwischen korrektivem, motivierendem und ergebnisorientiertem Feedback unterschieden. Korrektives Feedback ist ein fester methodischer Bestandteil sprachtherapeutischen Arbeitens und wird v. a. in der Kindersprachtherapie in Anlehnung an Dannenbauer (2002) auch als sprachliche Modellierungstechnik bezeichnet, die aktiv zur Sprachförderung eingesetzt wird. Dabei werden die Äußerungen in korrekter Weise wiederholt (korrektives Feedback) und ggf. als Sprachangebot erweitert (Expansion).
„Eingepasst in den Kontext gemeinsamen Tuns und mit direktem Sachbezug wird die Zielstruktur [...] mit erhöhter Frequenz und deutlicher Betonung immer wieder in das Zentrum der Aufmerksamkeit gerückt.“ (Dannenbauer, 2002, S. 152)
Diese Modellierungstechniken sind an den natürlichen Spracherwerb angelehnt und nehmen die Interaktionen zwischen Kind und Bezugsperson als Grundlage. Auch in der Aphasietherapie wird korrektives Feedback als methodisches Prinzip angewendet und ist ein alltägliches Werkzeug, das jedoch meist eher unsystematisch eingesetzt wird (Schmidt et al., 2014, S. 181).
Als motivierendes Feedback können all diejenigen sprachlichen Handlungen begriffen werden, die vorwiegend auf der phatischen Interaktionsebene der (Wieder-)Herstellung, Sicherung und Förderung von Kooperation und Beteiligungsbereitschaft dienen.
Ergebnisorientiertes Feedback bezeichnen Schmidt et al. (2014)
„als eine externe Rückmeldung (in diesem Fall durch die Therapeutin) auf eine Reaktion oder Antwort eines Lernenden (hier: des*r Patienten*in) [...], die zu einem Lernfortschritt führen soll“ (S. 181).
Dies macht eine Abgrenzung zwischen Feedback und Hilfestellung als zweierlei sprachtherapeutische Praktiken notwendig. Für den vorliegenden Untersuchungskontext erscheint eine Abgrenzung sinnvoll, die als ergebnisorientiertes Feedback solche Interaktionsleistungen versteht, die
a) deutlich als eine orientierende Rückmeldung auf eine konkrete Übungsleistung zu verstehen sind,
b) anzeigen, dass die Zielstruktur noch nicht (richtig) oder aber korrekt produziert wurde,
c) keine konkreten Hilfeleistungen darstellen, wie die Vorgabe des Mundbildes, Anlauthilfe usw.
Mit Blick auf die hier beschriebenen unterschiedlichen Feedback-Formen und deren Übertragung auf ein digitales Übungssetting für die interaktiven Funktionen des Avatars ist grundsätzlich zu bedenken, dass insbesondere die Form des korrektiven Feedbacks zunächst eine (fehlerfreie) Erkennung der fehlerhaft produzierten Zielstruktur voraussetzt. Dazu müssen innerhalb der Zielstruktur die Fehlerquellen korrekt identifiziert werden, damit darauf aufbauend eine produktive Korrektur vorgenommen werden kann. Das heißt, die Spracherkennung muss so gut trainiert sein, dass sie die Fehlerquellen einer Zielstruktur auch bei eingeschränkter Artikulationsfähigkeit der Patient:innen eindeutig ausmachen kann. Inwieweit korrektives Feedback KI-basiert künftig möglich sein wird, darüber lässt sich zum jetzigen Zeitpunkt nur mutmaßen. Sicher ist aber, dass es dafür einer sehr breiten Trainingsdatenbank bedarf, die allerdings erst generiert werden muss. Voraussetzung für die Erhebung dieser Daten ist der Prototyp der App, über den im Übungseinsatz die Sprachproduktionsleistungen der Patient:innen erhoben werden können. Es erscheint daher sinnvoll, den Fokus zunächst auf mögliche Elementarfunktionen von Feedback im digitalen Kontext zu setzen und damit Formen des ergebnisorientierten und motivierenden Feedbacks in den Blick zu nehmen.
3.3.2 Ergebnisorientiertes und motivierendes Feedback
Überträgt man das Prinzip des Scaffolding auf den Kontext der Sprach- und Aphasietherapie, dann geht es in der therapeutischen Interaktion v. a. darum, mithilfe von geeigneten Instruktionen und Rückmeldungen (Feedback) eine Optimierung von Lernprozessen anzustoßen (Ritterfeld & Hastall, 2017, S. 50–56). Feedback hat also allem voran eine Orientierungsfunktion, wobei auch motivationale Aspekte nicht außer Acht gelassen werden dürfen. Dies gilt insbesondere für die Aphasietherapie, bei der Patient:innen mitunter unter enormem Erfolgs- und Leidensdruck stehen, da die kommunikative Teilhabe durch die aphasische Erkrankung mitunter empfindlich eingeschränkt ist.
Ergebnisorientiertes Feedback übernimmt hier eine solch orientierende Funktion und kann qualitativer oder quantitativer Natur sein. Quantitatives Feedback meldet beispielsweise den erreichten Anteil des festgelegten Zieles zurück und ist gerade in digitalen Übungskontexten technisch mitunter sehr gut mess- und abbildbar. Qualitatives Feedback kann sich auf verschiedene Bereiche beziehen, z. B. auf Fortschritte, Entscheidungsangemessenheit, Richtigkeitsbreite oder den Unterstützungsbedarf (Ritterfeld & Hastall, 2017, S. 52–53). Mit Blick auf digitale Übungsumgebungen arbeiten die Autoren folgende Vorteile technikbasierten Feedbacks (gegenüber dialogischem Feedback durch Therapeut:innen) heraus: Die Reaktion basiert auf statistischen Berechnungen, und es besteht die Möglichkeit der graphischen Visualisierung von (Lern-)Prozessen. Zudem kann die Technik sofort auf sich verändernde oder entwickelnde Leistungen von Patient:innen reagieren und das Lernniveau optimal anpassen. Wichtig ist jedoch, dass technikbasiertes Feedback immer spezifisch und kongruent erfolgt. Das heißt, Lernende müssen das Feedback eindeutig auf ein bestimmtes Verhalten beziehen können (Ritterfeld & Hastall, 2017, S. 53).
Unter motivationalen Aspekten wird empfohlen, in der Therapiedurchführung korrekte Äußerungen unverzüglich mit positivem Feedback und Lob zu markieren sowie unspezifische Fehler, die innerhalb oder außerhalb der Übungsstruktur auftreten, nicht zurückzumelden. Lobend-motivationales Feedback kann in der sozialen Interaktion zudem präzisiert werden und bietet die Möglichkeit, ggf. Fehler und alternative Lösungsstrategien zu diskutieren.
Die nachfolgende Analyse fokussiert beide Formen von Feedback unter der grundlegenden Fragestellung: Wie treten ergebnisorientiertes und motivierendes Feedback jeweils multimodal in Erscheinung und welche dieser Erscheinungsformen lassen sich auf den Avatar oder das digitale Setting übertragen?
4 Exemplarische Sequenzanalyse – Übung ‘Wortpaare’
Die nachfolgende Analyse zeigt anhand zweier kurzer Sequenzen einer sprachtherapeutischen Behandlungseinheit, in welchen unterschiedlichen Formen Feedback multimodal in der Aphasietherapie in Erscheinung tritt und wie diese Feedbackleistungen Einfluss auf die weitere Interaktion und die Lösungsversuche des Patienten nehmen. Diese Darstellung soll dabei in erster Linie den rekonstruktiv-analytischen Ansatz verdeutlichen, dem wir im Rahmen des Projektes folgen, und die gesprächsanalytische Vorgehensweise nachzeichnen. Eine breite datenbasierte, systematische und umfassende Erfassung von Feedbackleistungen im Aphasie-therapeutischen Kontext wird Gegenstand der zukünftigen Projektarbeit sein. Dies schließt auch die grundlegende Frage um die Datenakquise und -erhebung ein, denn es bedarf Aufzeichnungen authentischer Übungseinheiten, die wohl in mehrfacher Hinsicht ‘heikel’ zu erheben sind.
Um jedoch einen ersten analytischen Zugriff unternehmen zu können, haben wir zunächst auf im Internet zugängliches (v. a. über die Suche bei Youtube) Datenmaterial zurückgegriffen. In zwei MA-Lehrveranstaltungen ‘Gesprächsforschung – Anwendungen’, die in den Sommersemestern 2020 und 2021 durchgeführt wurden, haben wir dazu über Youtube zugängliche Aufzeichnungen verschiedener Therapie- und Übungseinheiten einer Logopädin mit einem Aphasie-Patienten herangezogen und diese unter verschiedenen Aspekten gesprächsanalytisch untersucht. Dabei rückte neben der Darstellung von Empathie und Kooperativität auch die Analyse motivierenden und erfolgsorientierten Feedbacks in den Fokus der Analyse.
4.1 Korpus
Der hier exemplarisch im Fokus stehende Videomitschnitt ist betitelt als ‘Kognitives Training in der Logopädie bei Aphasie – Übung Wortpaare’ (Logopädie Antje Wolf, 2020), wurde am 14.04.2020 über die Videoplattform YouTube online gestellt und ist seitdem öffentlich zugänglich. Interaktionsformat ist ein Therapiegespräch. Grob ist es in zwei Abschnitte untergliedert: Während zuerst Übungen im Format Wortpaare ergänzen durchgeführt werden, indem Redewendungen vom Patienten vervollständigt werden sollen, werden im zweiten Teil des Videos die Bedeutungen der Redewendungen geklärt.
Die Beteiligten an dem Gespräch sind somit die Therapeutin und der Aphasiepatient. Zu Beginn der kurzen Sequenz erklärt die Therapeutin dem Patienten die Aufgabenstellung und weist darauf hin, dass ihm derartige Übungen bereits bekannt seien und er weder zu lesen noch zu schreiben brauche. Nach und nach werden dann die verschiedenen Wortpaare erarbeitet. Die Therapeutin liest dabei den ersten Teil des Wortpaares vor und der Patient soll dieses dann mündlich vervollständigen. Gelingt ihm dies nicht, gibt die Therapeutin Hilfestellung. In der Mitte des Videomitschnitts kommt es zu einem Zwischengespräch, bei dem die Therapeutin zu einem bestimmten Wortpaar die Bedeutung erfragt. Dies könnte dem therapeutischen Zweck dienen, innerhalb der Übung ein Spontangespräch anzuregen. Danach soll der Patient noch einmal die Begriffe wiederholen, die in der Übung benannt wurden. Auch hier gibt die Therapeutin Hilfestellung. Am Ende der Übungseinheit wird eine Bewegungsübung zur Lockerung durchgeführt.
Das (Aufnahme-)Setting ist für eine Therapiesituation eher ungewöhnlich: Beide Personen sitzen frontal vor der Kamera und werden bis auf Brusthöhe gefilmt. Die Therapeutin macht nebenbei Notizen und ist somit insgesamt sehr frontal ausgerichtet. Dennoch sucht sie häufig Blickkontakt zum Patienten, wendet sich von der Kamera ab und seitlich dem Patienten zu. Die Aufnahme wurde im privaten Raum gemacht. Im Hintergrund sind Küchenzeile und Wanduhr sichtbar.
Die Dauer des Videos beträgt 8:03 Minuten. Angesichts der Tatsache, dass eine Therapieeinheit meist 30 bis 45 Minuten andauert, ist davon auszugehen, dass das Video nur einen Ausschnitt einer Therapiesitzung präsentiert und der Darstellung einer ausgewählten Übung dient.
4.2 Methode
Methodisch folgen wir den bei Deppermann (2008) beschriebenen Grundprinzipien der konversationsanalytisch fundierten ‘Gesprächsanalyse’. Im Kern steht die Sequenzanalyse. Grundlage hierfür ist eine intensive analytische Arbeit mit der Aufnahme und dem zugehörigen verbalen und visuellen Transkript (Deppermann, 2008, S. 53). Die nachfolgend dargestellte sequenzielle Detailanalyse basiert auf zwei Gesprächsausschnitten, in denen die Therapeutin Feedback gibt und die somit ‘typische’ sprachtherapeutische Gesprächs-/Feedbackpraktiken in der Aphasietherapie veranschaulichen. Kennzeichnend für die mikroskopische Sequenzanalyse ist die Perspektive auf den Gesprächsprozess. Gesprächsaktivitäten und Äußerungen werden nicht isoliert, sondern in ihrer relationalen (Folge-)Bedeutung betrachtet.
Das Sequenzialitätsprinzip bedeutet für den Gesprächsanalytiker, daß [sic] er sich stets auf einer Höhe mit den Gesprächsteilnehmern bewegt und nicht vorgreift, um Früheres durch Späteres zu erklären, da dieses den Gesprächsbeteiligten im Moment ihres Handelns auch nicht als Interpretationshilfe zur Verfügung steht [...]. (Deppermann, 2008, S. 54)
Von analytischem Interesse ist dabei die Frage, welche
„Handlungs- und Interpretationsoptionen den Interaktanten in einem Gesprächsmoment offenstanden und wie mit diesen Möglichkeiten im weiteren Verlauf verfahren wird“ (Deppermann, 2008, S. 54).
Die bei Deppermann beschriebenen Analysegesichtspunkte folgen diesem übergeordneten Sequenzialitätsprinzip und sind auch für die vorliegende Analyse handlungsleitend.
Bei der Auswahl der Sequenzen wurde nach Paarsequenzen im Sinne einer feedbackauslösenden Aktivität und der entsprechenden Rückmeldung gesucht. Ausgangspunkt waren also Lösungsangebote zu einer Übung durch den Patienten und die Rückmeldeaktivität der Therapeutin auf das erfolgte Lösungsangebot sowie die nachfolgende Reaktion des Patienten als Reaktion auf das Feedback.
Von den Sequenzen wurden Verbaltranskripte in Anlehnung an Selting et al. (2009) nach GAT2 als Basistranskripte angefertigt. Die multimodale Analyse differenziert Mimik, Gestik, Blick sowie Körperausrichtung/Haltung. Dazu wurde das Verbaltranskript um entsprechende Informationen auf den genannten Ebenen ergänzt. Die Darstellung der Analyseergebnisse erfolgt anhand von Screenshots mit entsprechender Referenz im Transkript.
4.3 Sequenzielle Analyse
Für die Analyse wurde die Videosequenz von Min. 03:50 bis Min. 04:29 gewählt. Darin soll die Redewendung zwischen Tür und Angel vervollständigt werden. Im Vorlauf der Sequenz erklärt und veranschaulicht die Therapeutin das grundlegende Prinzip der Übung und erarbeitet mit dem Patienten ein erstes Beispiel (mit Sang und Klang), dem weitere Wortpaare folgen, die gemeinsam erarbeitet werden. Bei Schwierigkeiten bietet die Therapeutin Anlauthilfen an oder gibt Hinweise auf das gesuchte Wort, indem sie beispielsweise die Wortpaare in einen semantischen Kontext einbettet. Bei einem Wortpaar schlägt sie in den Lösungen nach (in Schnee und Eis) und gibt dem Patienten mimisch und gestisch Hinweise. An dieser Stelle macht sie außerdem transparent, dass auch sie bei diesem Wortpaar Unsicherheiten bei der Lösungsfindung bzw. dem Lösungswort hatte. Darüber hinaus gibt sie ihm noch einmal den Hinweis, dass das gesuchte Wort dem vorgegebenen im Klang ähneln muss, damit es sich dabei wirklich um ein Wortpaar handelt. Daran knüpft die erste ausgewählte Sequenz in Minute 03:50 an. Wie sich zeigt, stellt diese Redewendung eine kommunikative Herausforderung für den Patienten dar und er wählt zunächst ein nichtsprachliches Lösungsangebot. Die Therapeutin geht in dieser Sequenz auf das para- und nonverbale Handeln des Patienten ein. Insbesondere Tempo, Pausen und Melodie sind darin auffällig, aber auch die Wortwahl der Therapeutin und die Strategie der Anlauthilfe, sodass die Vervollständigung der Redewendung gelingt.
4.3.1 Sequenz I – Handgeste und Einwortäußerung als erstes Lösungsangebot
Bei der hier durchgeführten Übung ‘Wortpaare’ werden die Äußerungen des Patienten in lexikalisch-semantischer Dimension an einem Erwartungshorizont gemessen, der von einem hohen Automatisierungsgrad von Sprichwörtern ausgeht und daher beispielsweise semantische Paraphrasien als nicht gültige Antworten klassifiziert. Die Vervollständigung bzw. der Lösungsversuch wird hier also trennscharf als gültig oder nicht gültig für die Aufgabenbewältigung gewertet.
01 T zwischen TÜR und -|
((wendet Kopf und Blick beim Sprechen seitlich P zu))

Fig. 1
Gesprächssequenz I beginnt mit der elliptischen Vorgabe des zu vervollständigenden Sprichwortes zwischen TÜR und -| durch die Therapeutin [Seg. 01]. Dabei wendet sie sich dem Patienten lächelnd zu, die Lippen sind leicht geöffnet, sie schaut ihn an und sucht Blickkontakt (Fig. 1). Diese körperliche Zuwendung und insbesondere der freundliche Gesichtsausdruck mit den leicht geöffneten Lippen lassen eine Art Erwartungshaltung erkennen. Zwar handelt es sich hierbei nicht um eine Feedbackleistung im o. g. Sinn, dennoch lässt sich an der offenen, gespannten und freundlichen Haltung der Therapeutin eine Zuwendung erkennen, welche die Lösungsfindung des Patienten wohl unterstützen und motivieren soll.
02 P (4.27) ((schaut nach oben)) ((Handbewegung mit links,
Griffstellung, öffnend))
((schmatzt)) äh:m ((Handgeste mit links, Greifhaltung, öffnend))

Fig. 2
03 P (0.98)
04 P [TÜ:R-| ]
((reduzierte Handgeste mit links, Griffstellung, öffnend))
05 T ((schr[eibt etwa]s auf)) (9.28)
Nach einer Pause von 4,2 Sek. und suchender Blickbewegung (schaut nach oben) [Seg. 02] bietet der Patient eine Geste als Lösungsversuch zur Vervollständigung des Wortpaares an. Er führt eine Handgeste mit Fingern in Griffstellung aus, bei der der linke Arm eine öffnende Bewegung vom Körper weg ausführt (Fig. 2). Darauf folgt eine weitere ca. 1 Sek. lange Pause [Seg. 3], der Zögerungslaut äh:m, die Wiederholung der ausgeführten Handgeste und schließlich die Einwortäußerung (EWÄ TÜ:R-| in Segment 4. Diese Wiederholung des Nomens Tür aus der Aufgabenstruktur kann als nicht gültige Lösung klassifiziert werden. Der Produktion der EWÄ folgt ein weiteres Mal die bereits ausgeführte öffnende Hand- und Armgeste, jedoch in reduzierter Form [Seg. 4].
Die Therapeutin folgt in diesem Gesprächsschritt zunächst der Ausführung der Handgeste, wendet dann den Blick ab und notiert etwas in ihren Unterlagen. Es findet also eine Aufmerksamkeitsverschiebung vermutlich zugunsten der Dokumentation dieses nichtsprachlichen Lösungsversuches statt. Die beschriebene EWÄ des Patienten (s. o.) fällt in diese Dokumentationsphase [Seg. 4 und 5]. Dem in Kap. 4.2 beschriebenen Vorgehen folgend kann dieses erste Lösungsangebot des Patienten (Zeigegeste und EWÄ) als potenziell Feedback auslösend betrachtet werden. Auffällig ist, dass zunächst keine explizite Feedbackleistung durch die Therapeutin erfolgt, denn sie unterbricht ihre Schreibaktivität nicht und so entsteht eine vergleichsweise lange Pause [Seg. 5] von insgesamt 9,2 Sek. Wie die theoretischen Ausführungen zu ergebnisorientiertem und motivationalem Feedback (Kap. 3.3.2) zeigen, sollen korrekte Äußerungen unverzüglich mit Lob und positivem Feedback honoriert werden. Das Ausbleiben von Bestätigung bzw. Lob und auch das Fortführen der Schreibtätigkeit durch die Therapeutin kann in dieser Sequenz dennoch eine Art Orientierungs- und damit Feedbackfunktion übernehmen, weil die bei richtiger Lösung erwartbare Reaktion ausbleibt. Diese Interpretation wäre zumindest zutreffend, wenn korrekte Lösungsversuche durch die Therapeutin typischerweise (unverzüglich) mit Lob honoriert würden und diese Reaktion für den Patienten damit potenziell erwartbar wäre. Die Reaktion des Patienten lässt dies auch ablesen, denn er wartet die lange Schreibpause der Therapeutin ab, wobei sein Blick in dem Raum vor seiner Körpermitte ruht, wo er zuvor die Zeigegeste ausgeführt hat.
06 T °h ((hörbare nasale Einatmung)) hm::: -
((Blick nach oben mit hochgezogenen Augenbrauen))

Fig. 3

Fig. 4
Nach dieser (Schreib-)Pause findet erneut eine Aufmerksamkeitsverschiebung zurück zum Patienten und der Übung statt. Diese wird körperlich daran deutlich, dass die Therapeutin die (nach vorn gerichtete) Schreibposition verlässt, sich zurücklehnt und dem Patienten leicht seitlich zuwendet, ohne sich ihm jedoch richtig zuzuwenden. Dabei legt sie den Kopf leicht in den Nacken und ihr Blick geht nach oben [Seg. 6]. Begleitet wird diese veränderte Ausrichtung durch das lang gedehnte Häsitationspartikel hm::: -mit auffallender Schwebeintonation. Das Abbild des Grundfrequenzverlaufs im Oszillogramm (Fig. 4) zeigt, dass das Partikel auf nahezu gleicher Tonhöhe realisiert wird (s. o. 203,5 Hz – entspricht einem Ton zwischen gis und a in der kleinen Oktave). Auditiv wirkt dieses ‘mhh’ – zumindest in der Tendenz – gesummt, wofür v. a. die gleichbleibende Tonhöhe und die gerade Kontur verantwortlich zeichnen. Die deutlich markierte progrediente Intonationskontur in Kombination mit dem nach oben gewandtem Kopf und Blick an die Decke kann in diesem Gesprächsschritt Unterschiedliches anzeigen – z. B. Nachdenken oder Überlegen. Mit Initiierung dieser neuen Gesprächsaktion (und Haltungswechsel) fixiert der Patient mit seinem Blick wieder die Therapeutin, folgt ihrer Körperbewegung mit seinem Blick und öffnet die Lippen leicht.
4.3.2 Sequenz II – Modifikation der Aufgabenstellung durch Wechsel der Modalität
Im weiteren Verlauf der Interaktion geht die Therapeutin auf das initiale nichtsprachliche Lösungsangebot des Patienten und dessen Handgeste ein und bittet ihn, diese Geste erneut auszuführen. Diese Aufforderung ist nicht nur eine Bitte um Wiederholung des ersten Lösungsangebotes, sondern stellt zugleich eine Modifikation der Aufgabenstellung dar. Nach der gefüllten Pause [Seg. 06 s. o. Sequenz I] richtet die Therapeutin ihren Blick auf die Hand, mit der der Patient die unterstützende Geste seiner Antwort durchgeführt hat. Dabei runzelt sie die Stirn (Fig. 5) und es ist nicht ganz klar, worauf sich dieses Stirnrunzeln bezieht.
07 T ZEIG mir ma nochma was du grade jezeigt hast.||

Fig. 5
Möglicherweise zeigt dies einen Deutungsversuch der Handgeste an, eine Interpretation, die der weitere Interaktionsverlauf durchaus nahelegt (s. u.). Das Anzeigen von Nachdenken ist hier aber ebenso plausibel als mögliche Erklärung für das Stirnrunzeln. Damit reagiert sie also zunächst mit einem mimischen Signal auf das Lösungsangebot. Diese mimisch begleitete Äußerung ZEIG mir ma nochma was du grade jezeigt hast.|| [Seg. 07] mit der erneuten Vorgabe der Zielstruktur [s. u. Seg. 08] schafft für den Patienten einen Interpretationsrahmen, der anzeigt, dass sein Lösungsangebot (noch) nicht korrekt ist, da positives Feedback ausbleibt, das Lösungspotenzial aber bereits erkannt bzw. ein Lösungsweg gefunden scheint. In dieser Lesart modifiziert das mimisch gestützte Feedback die Übungsanforderung für den Patienten. Er soll nicht mehr nur verbal das Wortpaar ergänzen, sondern kann alternativ seine eigene Handbewegung zur Deblockierung nutzen. Das Feedback erlangt hier eine Doppelfunktion, da die Handgeste als multimodale Stimulation einbezogen wird. Die Therapeutin nutzt die Mimik folglich, um den Patienten zu motivieren, seinem Ansatz zur Aufgabenbewältigung zu folgen.
07 T ZEIG mir ma nochma was du grade jezeigt hast.||
08 =zwischn TÜR [un]-|
09 P [tü] TÜR tür.||

Fig. 6
10 T ha?

Fig. 7
11 P ((wiederholt Handgeste)) ngiep
12 (2.7)
13 ((wiederholt Handgeste)) ngie:p
Der Patient kommt nun dieser Aufforderung nach und wiederholt seine zuvor ausgeführte Handgeste mit der EWÄ ‘Tür’ [Seg. 09]. Zudem erweitert er im Verlauf sein Lösungsangebot und bietet in der analysierten Sequenz wiederkehrend onomatopoetische Äußerungen an. Das Quietschgeräusch in [Seg. 11] und [Seg. 13] wird in Kombination mit der bereits bekannten Handgeste angeboten, die ebenfalls sinnkonstituierend für die onomatopoetische Äußerung wirkt.
Die Therapeutin kommentiert zunächst die EWÄ in Segment 10 mit dem Rückmeldesignal ha? [Seg. 10] in leicht aufsteigendem Melodieverlauf (Fig. 7), begleitet von minimalem Kopfnicken. Auch hier nutzt sie multimodale Ressourcen, die vermutlich die Lösungsfindung unterstützen und motivieren sollen. Dadurch macht sie ihren Aufmerksamkeitsfokus, der auf dem Patienten liegt, deutlich und zeigt emotionale Beteiligung. Beides sind Faktoren, die als motivierend gewertet werden können. Die vom Patienten gewählten EWÄ, Gesten und onomatopoetischen Strukturen dienen in variierender Form und mit unterschiedlicher Gültigkeit der Aufgabenbewältigung der Sprichwortvervollständigung.
Im weiteren Verlauf der Übungssequenz kommt der Patient in Minute 4,22 schließlich zur gültigen Lösung [s. u. Seg. 16].
14 T und wie heißt der SPRUCH?|=
15 T =zwischn TÜR und -
16 T a
17 P ANGel.
18 T jeNAU;
Die Therapeutin wechselt mit der Frage in Segment 14 erneut die Modalität für die Lösung und zeigt an, dass die Zielstruktur verbal ergänzt werden soll. Unterstützend gibt sie die Aufgabenstruktur in schnellem Anschluss vor [Seg. 15] und gibt eine Anlauthilfe [Seg. 16]. Die unverzügliche Bestätigung der korrekten Lösung, so wie es im Kontext therapeutischen Feedbacks zu erwarten ist, erfolgt dann gewissermaßen in ‘Reinform’ in Segment 18 mit jeNAU;. Begleitet wird die verbale Bestätigung durch leichtes Kopfnicken, wobei sich die Therapeutin vom Patienten abwendet und erneut etwas aufzuschreiben beginnt – vermutlich das korrekte Zielwort. Insgesamt zeigt sich in dieser Sequenz auf phonetischer Ebene eine regionale Färbung (Berliner Dialekt) der Therapeutin.
19 T hast du mir grad die ANGel [je-]zeigt da?
20 P [mh ]
21 P mh hier((zeigt nach links)) [ANGel ]
22 T [wie die] AUFgeht?
Die Sequenz endet mit einer Rückversicherung in Bezug auf die Interpretation der Handgeste, die die Therapeutin initiiert. Diese ist wohl auch als Beziehungsarbeit zu klassifizieren, bestätigt v. a. aber die vom Patienten genutzten Ressourcen des Zeigens und Lautmalens.
5 Analyseergebnisse
Die Ergebnisse der oben illustrierten Analyse lassen sich wie folgt zusammenfassen: Die Rückmeldung bzw. das Feedback dient in erster Linie der Orientierungsfunktion auf dem Weg der Wort- bzw. Lösungsfindung und nimmt dabei insbesondere die vom Patienten angebotenen lösungsfördernden Modalitäten in den Blick. Damit erweitert sich der analytische Blick und auch das Verständnis von Feedback grundlegend. Feedbackleistungen sind in dieser Lesart nicht ausschließlich als verbale Aktivitäten zu klassifizieren und an die typischerweise auftretenden Sprechhandlungen wie Loben, Bestätigen, (Be-)Werten usw. gebunden. Im therapeutischen Kontext dehnt sich der Feedbackbegriff, so wie es die Analyse gezeigt hat, eher in Richtung back-channel-behavior, v. a. aber in eine multimodale Betrachtung von Rückmeldeleistungen. Damit erfolgt das Feedback in erster Linie implizit, also nicht durch bewertende Verbalisierungen, sondern körperlich, mimisch, prosodisch und durch die Modifikation der Übung.
Aus der Analyse des therapeutischen Handelns und des impliziten Feedbacks in den beiden Sequenzen wird deutlich, dass lange Pausen (Dokumentieren und Überlegen), ein körperliches Anzeigen von erwartungsvoller Spannung und mimisches Feedback Patient:innen non-verbal dazu anregen kann, nach individuellen Lösungs- und ggf. Deblockierungsstrategien zu suchen und ein neues Lösungsangebot zu machen. Die genutzten multimodalen Feedbackkanäle der analysierten Therapiesituation können in eine körperliche, pragmatische wie prosodische Ebene untergliedert werden. Auf körperlicher Ebene ist eine Zuwendung mit erhöhter Körperspannung zu beobachten sowie Blickkontakt, Lächeln und einem leicht geöffneten Mund. Auf pragmatischer Ebene zeigen sich das Bitten um Wiederholung, die Modifikation der Aufgabenstellung zugunsten des Lösungsansatzes des Patienten, Aufmerksamkeitsverschiebung (etwas aufschreiben) bei ungültiger Antwort und bei richtiger Antwort eine unverzügliche Bestätigung. Begleitet wird dies durch die prosodische Ebene, auf der sich z. T. lange Pausen mit gedehnten Häsitationspartikeln in Schwebeintonation finden lassen, sowie eine Synchronisation der Turnlängen, Pausen und der Sprechmelodie (Birke & Werth, 2020, S. 13). Des Weiteren fallen in den Gesprächssequenzen phonetische Abweichungen von der Standardaussprache auf: Die Therapeutin spricht mit dialektaler Färbung, was durch einen geteilten regionalen Bezug bspw. Nähe zum Patienten herstellen kann.
Das Zeigen eines Aufmerksamkeitsfokus und der emotionalen Beteiligung der Therapeutin wurde in dieser Analyse als motivierender Faktor und implizites Feedback gewertet. Jene Merkmalsbündel sind jedoch nicht zweifelsfrei als Feedback zu kategorisieren, sondern können aufgrund der sich überschneidenden Beschreibungsebenen auch aus der Perspektive empathischen Handelns betrachtet werden. Eine interaktionslinguistische Perspektive auf Empathie zeigt bspw., dass Ressourcen zur Darstellung von Empathie im Zusammenspiel mehrerer Ebenen auftreten. Dies sind verbale Ressourcen (u. a. Fragenstellen), prosodisch-phonetische und kinetische Ressourcen zur affektorientierten Darstellung von Mitgefühl oder verstehensorientiertem Verständnis sowie mimische, haptische und kinetische Ressourcen (Kupetz, 2015, S. 56–59). Es erscheint in Anbetracht der Analyse kaum möglich, eine trennscharfe Differenzierung zwischen Empathie und Feedback vorzunehmen. Der therapeutische Kontext fordert womöglich eine Überschneidung jener Ebenen geradezu heraus, sodass emotionales und therapeutisches Feedback an dieser Stelle als Expertenhandeln gewertet werden kann, was ein fallanalytisches Vorgehen bei der Analyse dieses Handelns, wie im vorliegenden Fall nachgezeichnet, plausibel macht.
6 Fazit
Der Bedarf an digitalen Versorgungskonzepten ist nicht nur pandemiebedingt, sondern v. a. als Folge politischer Entscheidungen der zurückliegenden Jahre enorm. Ob die allseits geforderte Digitalisierung und der damit verbundene Hype imstande sind, diese gesellschaftlich-strukturellen Herausforderungen zu lösen, sollte grundsätzlich zur Debatte stehen.
Der Ansatz, dem wir mit dem aphaDIGITAL-Projekt folgen, besteht keinesfalls darin, leibhafte, ko-präsente Therapie oder gar die Therapeut*innen selbst ersetzen zu wollen und so die durch den Fachkräftemangel klaffende Versorgungslücke zu schließen. Ein solches Ansinnen widerspricht dem therapeutischen Grundverständnis zutiefst: Die therapeutische Beziehung ist die stärkste Einflussgröße für den Therapieerfolg und somit bestimmen die Beziehungsebene und die Interaktionsqualität den Erfolg der Therapie (Schneeberger, 2018, S. 15). In unserem Verständnis leistet das Projekt einen Beitrag, um Brücken zu bauen, damit Patient:innen geholfen werden kann. Damit verbindet sich die grundsätzliche Fragestellung nach Einsatzgebieten, Potenzialen und Grenzen digitaler Angebote und Versorgungskonzepte. Ein Potenzial sehen wir in der interaktiven Rahmung und Übungsbegleitung durch den Avatar und den hohen Grad an Individualisierbarkeit der Übungsumgebung (und des -materials). Zu diesem Zweck wird sich unsere Forschungsarbeit zentral der Frage widmen, wie sich (analog) therapeutisches Handeln und die damit verbundenen multimodalen Ressourcen digital und durch den Avatar abbilden lassen.
Die Anforderungen an die Modellierung der digitalen Übungsumgebung und des Avatars sind ausgesprochen komplex. Die Analyseergebnisse münden in der grundlegenden Fragestellung, wie ein Avatar im therapeutischen Setting modelliert werden kann, mit welchen Features und kommunikativen Skills er ausgestattet werden muss und wie ‘menschlich’ er agieren und erscheinen sollte. Effekte, wie der von MacDorman (2006) beschriebene Uncanny-Valley-Effekt (Gruselgraben, der sich auftut, wenn Avatare zu menschlich aussehen oder agieren), sind dabei ebenso ins Kalkül zu ziehen wie die in der Literatur beschriebenen positiven Effekte digitaler Übungsszenarien (z. B. niedrigere Antworthemmschwellen durch Wegfall der therapeutischen Bewertung) (Rademacher, 2009, S. 166–171).
Welche konkreten Schlüsse lassen sich an dieser Stelle aus der hier dargestellten Analyse ziehen?
Zu modellierende Feedbackelemente könnten sein:
nach Aufgabenstellung: körperliche Zuwendung, Aufrichtung bzw. Spannung, motivierendes Lächeln, leicht geöffneter Mund, Blickkontakt (bis zur Turnübernahme und Lösungsangebot) als eine Ausdrucksform freudig-gespannten Abwartens,
zur Anzeige des ‘Nachdenkens/Überlegens’, um ggf. KI-Verarbeitungszeiten längerer Äußerungen zu überbrücken: Pausen machen, dabei ist der Kopf leicht in den Nacken gelegt, der Blick ist nach oben gerichtet, die Augenbrauen leicht nach oben gezogen, Rückmeldepartikel hm mit progredienter Intonation,
bei Ausbleiben einer Antwort/ungültigem Lösungsangebot: Wechsel von körperlicher Zu- und Abwendung (Zuwendung zur Motivation, Abwendung kann ggf. zu einem Herabsetzen der Hemmschwelle führen).
Ob und mit welchem therapeutischen Effekt sich die Ansätze zu den o. g. Feedback-Funktionen im digitalen Setting umsetzen lassen, muss letztlich im therapeutischen Einsatz evaluiert werden. Evaluationsstudien markieren eine der bei Jaecks et al. (2020) grundlegend formulierten Forderungen für die digitale Sprachtherapie. Die Feldtestung und therapeutische Evaluation soll im Rahmen des Projektes in Kooperation mit verschiedenen regionalen sprachtherapeutischen Praxispartnern, lokalen Reha- und Therapiezentren und der Fachrichtung Logopädie am Universitätsklinikum Halle (UKH) durchgeführt werden.
Die Beschäftigung mit dem Untersuchungsgegenstand wirft für künftige Analysen auch die Frage nach einer trennscharfen Differenzierung zwischen den Konzepten von Feedback und Empathie auf. Auffällig ist, dass Empathie und Feedback im therapeutischen Expertenhandeln häufig über mulitmodales back-channel-behaviour dargestellt werden. In der Interaktionsforschung werden bspw. vier interaktionssemantische Basisdimensionen als Teilaktivitäten benannt, die die Darstellung emotionaler Beteiligung konstituieren: Evaluieren, Intensivieren, Subjektivieren und Veranschaulichen (Deppermann, 2004, S. 86; Drescher, 2003, S. 96). Auch diese Phänomene können oberflächennah analysiert und für die Modellierung des Avatars zurate gezogen werden. Analytisch in den Blick genommen werden sollten darüber hinaus nach Kupetz (2015, S. 56–59) auch Verständnisäußerungen sowie verbale, prosodisch-phonetische, mimische und proxemische Ressourcen der Empathiedarstellung.
Literatur
Bänziger, K., Mortillaro, M. & Scherer, K. R. (2012). Introducing the Geneva Multimodal expression corpus for experimental research on emotion perception. Emotion, 12(5), 1161–1179. https://doi.org/10.1037/a0025827
Bilda, K., Dörr, F., Urban, K. & Tschuschke, B. (2020). Digitale logopädische Therapie. Ergebnisse einer Befragung zum aktuellen Ist-Stand aus der Sicht von LogopädInnen. Logos 28(3), 176–183.
Bilda, K. (2017a). Potenziale und Barrieren. In K. Bilda, J. Mühlhaus & U. Ritterfeld (Hrsg.), Neue Technologien in der Sprachtherapie (S. 20–34). Thieme.
Bilda, K. (2017b). Teletherapie bei Aphasie: Ein videogestütztes Sprechtraining mit integriertem Videokonferenzsystem. In K. Bilda, J. Mühlhaus & U. Ritterfeld (Hrsg.), Neue Technologien in der Sprachtherapie (S. 84–89). Thieme.
Birke, Ch. & Werth, J. (2020). Analyse einer Gesprächssequenz aus der Aphasie-Therapie im Hinblick auf Empathie. (Hausarbeit, unveröff. Mskr., Martin-Luther-Universität Halle-Wittenberg).
Büttner, C. & Quindel, R. (2005). Sicherheit und Kompetenz im Therapiegespräch. Springer.
Dannenbauer, F. M. (2002). Grammatik. In S. Baumgartner & I. Füssenich (Hrsg.), Sprachtherapie mit Kindern. uni-Taschenbücher.
Deppermann, A. (2008). Gespräche analysieren. Eine Einführung. VS Verlag für Sozialwissenschaften.
Einhorn, L. (2021). Kommunikativ-interaktive Anforderungen an einen virtuellen Übungs-(beg)-leiter für Aphasiepatient-/-en/-innen im privaten Therapie-Übungssetting. (MA-Thesis, unveröff. Mskr., Martin-Luther-Universität Halle-Wittenberg)
Fiehler, R. (1999). Was tut man, wenn man kooperativ ist? In A. Mönnich & E. W. Jaskolski (Hrsg.), Kooperation in der Kommunikation (S. 52–58). Reinhardt.
Geißner, H. (1998). Vom Oberflächen- zum Tiefenfeedback. In H. Geißner & E. Slembek (Hrsg.), Feedback: Das Selbstbild im Spiegel der Fremdbilder (S. 13–30). Röhrig Universitätsverlag.
Geißner, H. & Slembek, E. (1998) (Hrsg.). Feedback: Das Selbstbild im Spiegel der Fremdbilder. Röhrig Universitätsverlag.
Hegel, F., Spexard, T., Wrede, B., Hortmann, G. & Vogt, T. (2006). Playing a different imitation game: Interaction with an Empathic Android Robot. Proceedings of the 6th IEEE/RAS International Conference on Humanoid Robots, 56–61.
Herter-Ehlers, U. (2020). Kommunikative Kompetenzen in der Logopädie. Ein Konzept zur Entwicklung von kommunikativen Kompetenzen in der Ausbildung – Zusammenfassung der Masterarbeit. Sprechen. Zeitschrift für Sprechwissenschaft 69, 23–34. http://www.bvs-bw.de/SPRECHEN/sprechen_2020-1-Nr_69.pdf#page=23 (27.08.2020).
Homburg, G. & Lüdtke, U. (2003). Beziehungsgestaltung: Standards therapiedidaktischer Kompetenzen. In M. Grohnfeldt (Hrsg.), Lehrbuch der Sprachheilpädagogik und Logopädie. Bd. 4, Beratung Therapie und Rehabilitation (S. 127–131). Kohlhammer.
Huml, M. (2014). Vorwort. In Bayerische TelemedAllianz Jedamzik, S. (Hrsg.), Spektrum Telemedizin Bayern. Aktueller Überblick telemedizinscher Projekte und Anwendungen in Bayern (S. 11). Bayerische Anzeigenblätter GmbH.
Innovation & Strukturwandel – WIR! (o. D.). WIR! – Wandel durch Innovation in der Region.
https://www.innovation-strukturwandel.de/strukturwandel/de/innovation-strukturwandel/wir_/wir_?utm_source=hootsuite
Jakob, H. & Späth, M. (2021). Sprachtherapeutische Apps am Beispiel neolexon: Herausforderungen beim Zugang in die Versorgung und Chancen für Therapeuten und Patienten. Sprache – Stimme – Gehör, 1(21), 17–21.
Jaecks, P., Johannsen, K. & von Lehmden, F. (2020). Zukunftskonzept Digitalisierung. Fünf Forderungen für die digitale Sprachtherapie. Logos, 28(3), 184–188.
Kupetz, M. (2015). Empathie im Gespräch. Eine interaktionslinguistische Perspektive. Stauffenburg.
Kühnlenz, B., Busse, F., Förtsch, P., Wolf. & Kühnlenz, K. (2018, 27.-31. August). Effect of explicit emotional adaptation on prosocial behavior of humans towards robots depends on prior robot experience. 2018 27th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN). DOI: 10.1109/ROMAN.2018.8525515
Lange, F. (2021). Feedback als Haltung in der Lehrer*innenbildung – im Spannungsfeld zwischen Beraten und Bewerten. In S. Voigt-Zimmermann (Hrsg.), Miteinander sprechen – verantwortlich, kompetent, reflektiert (S. 89–103). Frank & Timme.
Lange, S. (2012). Kommunikationskompetenz in den Therapieberufen: Gemeinsam ans Ziel. Schulz-Kirchner.
Leinweber, J. & Schulz, K. (2019). Digitalisierung in der Aphasietherapie. Eine ethische Betrachtung. Aphasie suisse. Aphasie und verwandte Gebiete, (46), 34–41.
Logopädie Wolf, A. [Antje Wolf]. (2020, 14. April). Kognitives Training in der Logopädie bei Aphasie Übung Wortpaare. [Video]. YouTube. https://www.youtube.com/watch?v=rsmmJ0yjYII
Lüdtke, U. (2004). Emotionen im Unterricht. Theorie und Praxis einer Relationalen Didaktik im Förderschwerpunkt Sprache. In M. Grohnfeldt (Hrsg.), Lehrbuch der Sprachheilpädagogik und Logopädie, Bd. 5 (S. 106–126). Kohlhammer.
MacDorman, K. F. (2006). Introduction to the special issue on android science. Connection Science, 18(4). 313–317. DOI: 10.1080/09540090600906258
Malchus, K. (2015). Evaluation emotionaler und kommunikativer Verhaltensweisen in Mensch-Roboter Interaktionen in therapierelevanten Szenarien zur Entwicklung eines Modells für die roboterunterstützte Therapie bei Sprach- und Kommunikationsstörungen. (Dissertation Universität Bielefeld).
Malchus, K., Wrede, B. & Jaecks, P. (2019). Roboterunterstütztes Benenntraining bei Aphasie – eine Einzelfallstudie. Aphasie und Verwandte Gebiete, 45(1), 14–22.
Radermacher, I. (2009). Einsatz computergestützter Verfahren in der Aphasietherapie. Sprache – Stimme – Gehör, 33(4), 116–171.
Richter, J. (2015). Effizienz neurolinguistischer Teletherapie bei zerebralem Insult mit Aphasie – eine prospektive Längsschnittstudie. (Med. Diss. Erlangen-Nürnberg).
Ritterfeld, U. & Hastall, M. (2017). Begrifflichkeiten, Systematik, Akzeptanzfaktoren und Innovationen. In K. Bilda, J. Mühlhaus & U. Ritterfeld (Hrsg.), Neue Technologien in der Sprachtherapie (S. 35–43). Thieme.
Rupp, E. (2010). Fortschritte in der Behandlung und Diagnostik zentraler neurogener Sprachstörungen. Ergebnisse des Projektes „Teletherapie bei Aphasie“. (Phil. Diss. Ludwig-Maximilians-Universität München)
Sachse, R. (2016). Therapeutische Beziehungsgestaltung. Hogrefe.
Scherer, K. R. (2005). What are emotions? And how can they be measured? Social Science Information, 44(4), 693–727.
Schmidt, S., Kisielewicz, D. & Heide, J. (2014). Die Rolle von Feedback in der Aphasietherapie: Eine Therapiestudie zur Behandlung von Wortfindungsstörungen. Spektrum Patholinguistik, 7, 181–190.
Schmidt, A. (2018). Interaktion und Kommunikation. In D. Hoffmann & R. Winter (Hrsg.), Mediensoziologie (S. 15–38). Baden-Baden: Nomos.
Schneeberger, S. (2018). Qualitative Analyse von Patienten- und Therapeuteninterviews bezüglich allgemeiner Wirkfaktoren und der Patient-Therapeut-Beziehung in der Sprachtherapie. (MA-Thesis, Europäische Fachhochschule).
Selting, M., Auer, P. & Barth-Weingarten, D. (2009). Gesprächsanalytisches Transkriptionssystem 2 (GAT 2). Gesprächsforschung – Online-Zeitschrift zur verbalen Interaktion. 10, 353-402. (http://www.gespraechsforschung-online.de/fileadmin/dateien/heft2009/px-gat2.pdf)
TDG (o. D.). Apha Digital – Entwicklung einer digitalen, dezentralen sprachtherapeutischen Versorgung. https://inno-tdg.de/projekte/aphadigital/
TDG: Translationsregion für digitalisierte Gesundheitsversorgung (Hrsg.) (2018). Die Zukunft für Gesundheit und Pflege, TDG-Report 2018, Medizinische Fakultät der Martin-Luther-Universität Halle-Wittenberg.
Tuschy-Nitsch, D. & Spiecker-Henke, M. (2014). Der Patient und sein Therapeut. In M. Spiecker-Henke (Hrsg.), Leitlinien der Stimmtherapie. Thieme.
Pfänder, S., Herlinghaus, H. & Scheidt, Carl (2017). Synchronisation in Interaktion: Eine interdisziplinäre Annäherung an multimodale Resonanz. Resonanz-Rhythmus-Synchronisierung. Interaktion in Alltag, Therapie und Kunst. Transcript, 65–84.
Voigt, J. (2019). Virtueller-Sprach-Therapieraum: Potenziale, Anforderungen und Grenzen. BA-Thesis MLU Halle (Saale). (unveröff. Mskr.).
Wahl, M., Steiner, J. & Mühlhaus, J. (2018). Neue Medien in der Sprachtherapie. In J. Steiner (Hrsg.), Ressourcenorientierte Logopädie. Perspektiven für ein starkes Netzwerk in der Therapie (S. 161–172). Bern: Hogrefe.
Wehmeyer, M., & Grötzbach, H. (2014). Grundlagen. In M. M. Thiel, C. Frauer & S. Weber (Hrsg.), Aphasie. Wege aus dem Sprachdschungel. 6. Aufl., Berlin/Heidelberg: Springer, 3-14.
Weidner, K. & Lowman, J. (2020). Telepractice for Adult Speech-Language Pathology Services: A Systematic Review. Perspectives of the ASHA Special Interest Groups, 5, 326–338.
Zeller, C. (2018). Softwarebasierte Aphasietherapie. Entwicklung und Erprobung des kommunikativ-pragmatischen Übungsprogramms AKOPRA. Tectum.
Zheng, C., Lynch, L. & Taylor, N. (2016). Effect of computer therapy in aphasia: a systematic review. Aphasiology, 30(2–3), 211–244.
Ziegler, W. (2012). Rehabilitation aphasischer Störungen nach Schlaganfall. In H. Chr. Diener & C. Weimar (Hrsg.), Leitlinien für Diagnostik und Therapie in der Neurologie (S. 1087–1095). Thieme.
Anhang
Folgesequenz nach den analysierten Sequenzen
Segment Nr. Sprecher Wortlaut
Teil 2
4:15
00017 Therapeutin ((guckt ihn an))
00018 und wie heißt der SPRUCH?|=
00019 =zwischn TÜR und (-) a
00020 P ANGel
00021 T jeNAU
00022 hast du mir grad die ANGel [je-]
00023 P [mh ]
00024 T zeigt da
00025 P ((nickt))
00026 mh hier((zeigt nach links)) [ANGel ]
00027 T [wie die] AUFgeht
00028 P ((nickt)) <<zustimmend>> mh;||
00029 T ((nickt))(.) <<zustimmend>> mh?||
Autorinnen

Judith Pietschmann
Judith Pietschmann, Dipl.-Sprechwissenschaftlerin, studierte an der Martin-Luther-Universität Halle-Wittenberg (MLU) und promovierte 2017 im Rahmen eines Forschungsprojektes zur Optimierung der Gesprächsinteraktion im telefonischen Kundendienst. Als Wissenschaftliche Mitarbeiterin der Abteilung Sprechwissenschaft und Phonetik der MLU lehrt und forscht sie in den Schwerpunktbereichen rhetorische Kommunikation, Sprechwirkungsforschung und therapeutische Interaktion. Derzeit ist sie verantwortlich im Drittmittelprojekt AphaDIGITAL (Leitung: Prof. Dr. Susanne Voigt-Zimmermann) tätig, welches einen Beitrag zur Digitalisierung der Aphasietherapie unter sprechwissenschaftlicher Prämisse leistet.
Postanschrift: Martin-Luther-Universität Halle-Wittenberg, Institut für Musik, Medien- und Sprechwissenschaften, Sprechwissenschaft und Phonetik, Emil-Abderhalden-Str. 26-27, D-06108 Halle (Saale)
E-Mail: judith.pietschmann@sprechwiss.uni-halle.de

© Julia Werth
Julia Werth
Julia Werth ist Atem-, Sprech- und Stimmlehrerin nach Schlaffhorst-Andersen und Sprechwissenschaftlerin (B.A.). An der Martin-Luther-Universität Halle-Wittenberg (MLU) arbeitete sie als wissenschaftliche Hilfskraft am Drittmittelprojekt AphaDIGITAL. Derzeit beendet sie das Masterstudium Sprechwissenschaft an der MLU mit ihrer Abschlussarbeit „Entwicklung phonetischer und rhetorischer Kompetenzen Deutschlernender“. Atem-, Sprech- und Stimmlehrerin, BA Sprechwissenschaft
Postanschrift: CJD Schule Schlaffhorst-Andersen, Bornstraße 20,
31542 Bad Nenndorf
E-Mail: julia.werth@hotmail.de

© Josephin Voigt
Josephin Voigt
Josephin Voigt absolvierte 2014 die Ausbildung zur staatlich anerkannten Logopädin. Sie studierte weiterführend den Bachelorstudiengang Sprechwissenschaft an der Martin-Luther-Universität Halle-Wittenberg (MLU), indem sie am Drittmittelprojekt AphaDIGITAL mitwirkte. Derzeit befi ndet sie sich im Masterstudium der Sprechwissenschaft an der MLU und ist als Logopädin selbstständig tätig.
Josephin Voigt, BA Sprechwissenschaft
Postanschrift: Logopädie Voigt, Schadowstraße 1, D-04177 Leipzig
E-Mail: josephin.voigt@googlemail.com

© Christoph Birke
Christoph Birke
Christoph Birke ist B.Sc. Patholinguistik. Seit 2019 studiert er im Masterstudiengang Sprechwissenschaft an der Martin-Luther-Universität Halle-Wittenberg (MLU). Neben dem Studium arbeitete er als studentische Hilfskraft im BabyLAB der Universität Potsdam (Leitung: Prof. Dr. Barbara Höhle) und im Projekt AphaDIGITAL an der MLU. Neben dem Studium bietet er semiprofessionellen Theatergruppen Sprecherziehung an, moderiert bei Radio Corax e.V. Podcasts „Seenotrettung“ und spricht für den MDR „Nachrichten in Leichter Sprache“.
Christoph Birke, B.Sc. Patholinguist Interdisziplinäres Therapiezentrum Halle (Nord),
Trothaer Straße 102-103, D-061118 Halle (Saale)
E-Mail: birkechristoph@gmail.com
Kontakt
„Sprechen & Kommunikation – Zeitschrift für Sprechwissenschaft“ wird herausgegeben von der Deutschen Gesellschaft für Sprechwissenschaft und Sprecherziehung e. V.
Erschienen am: 23.09.2022

Schweigen in einer digitalen Welt
Schweigen ist keineswegs das Gegenteil von Sprechen: Beide sind komplementäre Pole auf einer Skala kommunikativer Mittel. Die Bedeutung des Schweigens kann nur über den jeweiligen Kontext konstruiert werden und das kann in digitaler Kommunikation zu Missverständnissen führen. Was ein Schweigen tatsächlich bedeutet bzw. bedeuten soll, muss stets zwischen den Kommunizierenden ausgehandelt werden.
von Sina Lautenschläger
Schlüsselwörter
kommunikatives Schweigen, Still-Sein, digitale Kommunikation, Mediatisierung, Interventionsstrategien
Zusammenfassung
Schweigen ist keineswegs das Gegenteil von Sprechen: Beide sind komplementäre Pole auf einer Skala kommunikativer Mittel. Während die Bedeutung von Verbalisiertem aber durch die konkrete Wortwahl und den Kontext eingegrenzt wird, kann die Bedeutung eines Schweigens ausschließlich über den Kontext konstruiert werden, da materiell nichts angeboten wird. Und gerade diese starke Kontextabhängigkeit kann in digital vermittelter Kommunikation zu Missverständnissen führen, die bereits auf der basalen Unterscheidung von Schweigen (als kommunikativer Handlung) und Stille (als nicht-kommunikativem Zustand) angelegt sind und durch die Entkontextualisierung der Interagierenden begünstigt werden. Im Zusammenhang mit dieser grundlegenden Unterscheidung lassen sich verschiedene Arten des Schweigens aufzeigen.
Was ein Schweigen tatsächlich bedeutet bzw. bedeuten soll, muss stets zwischen den Kommunizierenden ausgehandelt werden und zeigt sich nicht zuletzt durch die verschiedenen Interventionsstrategien, die sich in Keyboard-to-Screen-Kommunikation finden lassen und Parallelen zu den Strategien in Face-to-Face-Gesprächen aufweisen.
Keywords
communicative silence, being silent, digital communication, mediatization, intervention strategies
Abstract
Silence is by no means the opposite of speech: Both are complementary poles on a scale of communicative means. However, while the meaning of what is verbalized is specified by the particular choice of words and the context, the meaning of an act of silence can be constructed exclusively through the context, since in material terms nothing is offered. And it is precisely this strong context dependency that can lead to misunderstandings in digital communication. These misunderstandings are already inherent in the basic distinction between being silent (as a communicative act) and quietness (as a non-communicative state) and are furthered by the de-contextualization of those who interact. In the context of this basic distinction, different types of silence can be identified.
What an act of silence actually means or is supposed to mean always has to be worked out between the communication partners and becomes obvious not least in the various intervention strategies that can be found in keyboard-to-screen communication, showing parallels to the strategies in face-to-face conversation.
1 Einleitung
Obwohl Reden und Schweigen als „Komplementärkräfte im Kommunikationsgeschehen“ (Mayer, 2007, 686) zu verstehen sein sollten, wird Schweigen gemeinhin ex negativo als das Fehlen von Rede definiert – es „entsteht dort, wo Reden aufhört. Und es endet dort, wo Reden wieder einsetzt. Schweigen wird also durch Reden begrenzt“ (Bergmann, 1982, 147) und oszilliert als „sprachliche Extremform (das Andere der Sprache und zugleich deren Teil)“ (Schmitz, 1990, 32) im Spannungsfeld Sprache – Nicht-Sprache. Die Tatsache, dass Schweigen als „lack of speech“ (Jaworski, 1993, 46) konzipiert wird und ein materielles Nichts darstellt, bedeutet dabei aber weder, dass es keine kommunikative Funktion hat, noch, dass es als Gegensatz des Sprechens anderen Regeln unterworfen ist. Vielmehr zeigt Schweigen sehr prägnant,
„was überall in der Sprache gilt: Vieldeutigkeit, Kontextabhängigkeit, Bedeutungskonstruktion durch die Sprecher. Die – abstrakt betrachtet – Vieldeutigkeit der Zeichen wird in der Situation durch die Sprecher auf das je einzeln Gemeinte erst festgelegt.“ (Schmitz, 1990, 32)
Gerade die Digitalisierung und Mediatisierung haben dazu beigetragen, dass sich Kommunikationspraktiken und mit ihnen auch kommunikative Erwartungshaltungen ändern. Die damit zusammenhängenden Fragen, wie sie etwa im Zuge der 2020 stattgefundenen DGSS-Tagung „Mündlichkeit 4.0: Sprechen in einer digitalen Welt“ gestellt wurden, nämlich „wie sich die Form, miteinander zu sprechen, wie sich die Inhalte, die wir kommunizieren, durch die Einbindung des Digitalen verändern“ (DGSS, 2020) und welche Unterschiede sich zwischen dem Sprechen in der „digitalen Welt“ und dem in der „analogen Welt“ ergeben (ebd.), sind auch für Schweigen in sogenannter Keyboard-to-Screen-Kommunikation (KtS-Kommunikation) (Dürscheid & Frick, 2014), also in digitaler, schriftlich vermittelter Kommunikation virulent. Dies lässt sich nicht nur, aber auch an den massenhaft im Internet kursierenden Memes nachvollziehen, die die Bedeutsamkeit von Schweigen deutlich anzeigen:

Abb. 1 Metakommunikation über Schweigen (Quelle: Instagram 1+3 sacdasm_only , 2 classicalfuck
Während Meme 1 auf humorvolle Weise darauf anspielt, dass es weder schwer noch unmöglich ist, auf Whatsapp-Nachrichten zu antworten, zeigen die Memes 2 und 3, dass sich das Verhältnis von Schreiben – Nicht-Schreiben zu einem (Macht-)Spiel entwickelt hat. Dies impliziert, dass es nicht nur Spielregeln, sondern auch Sieger*innen und Verlierer*innen gibt, wobei offenbar gilt: Wer länger schweigt, gewinnt. Da aber kein Kontaktabbruch angestrebt wird, scheint es eine der Spielregeln zu sein, das Verhältnis zwischen Zuwendung und Ignorieren, also Schreiben und Schweigen, auszubalancieren.
Die sich hier abzeichnende Relevanz von Schweigen lässt sich auch in authentischer, privat geführter Messenger-Kommunikation 1 nachvollziehen und bildet die Grundlage dieses Beitrages. In der Analyse des dort aufkommenden Schweigens, genauer: der Analyse der Metakommunikation über dieses Schweigen, zeigen sich viele Parallelen zu den die Schweigephasen beendenden Interventionsstrategien, die Bergmann (1982) in Face-to-Face-Gesprächen feststellt, aber es offenbart sich auch ein Spezifikum der KtS-Kommunikation: das (längerfristige) Zurück-Schweigen. Bevor in Abschnitt 4 auf diese Strategien genauer eingegangen wird, sei im Zusammenhang mit Schweigen zunächst auf die Mediatisierung und die Entgrenzung der Medien eingegangen, um im Zuge dessen einige ausgewählte Charakteristika der Messenger-Kommunikation am Beispiel von Whatsapp darzulegen. Im darauffolgenden Abschnitt wird der grundlegende und analyserelevante Unterschied zwischen Schweigen und Still-Sein erörtert und neben den verschiedenen Schweigearten auf graduelles Schweigen eingegangen.
2 Mediatisierung, Entgrenzung, Whatsapp und soziale Kontrollmechanismen
Mit Mediatisierung ist nach Krotz (2001) das Wechselverhältnis von medienvermittelter Kommunikation und gesellschaftlicher Praxis gemeint. Menschen entwickeln nicht nur Technik und somit Medien, sondern sie eignen sie sich auch sozial an – und wegen dieser Aneignung ändern sich die Alltagspraktiken, an die die Medien wiederum angepasst werden (Krotz, 2001: 31). Das hat letztlich zu einer Entgrenzung von Medien geführt (Krotz, 2001, 19 ff.): Waren sie früher an bestimmte Zeiten und Orte gebunden – Beispiele sind das Festnetztelefon oder der heimische Fernseher, auf dem samstagabends um 20:15 Uhr eine Unterhaltungsshow oder ein Spielfilm geschaut wurde –, sind sie dies heute nicht mehr. Besonders durch das Smartphone als täglicher Begleiter ist nicht nur das Streamen von Filmen und Serien überall und zu jeder Zeit bequem möglich geworden, sondern auch die zwischenmenschliche Kommunikation, sei es per Whatsapp-Chat, FaceTime, Instagram (Direct Message), Facebook (Messenger), Snapchat oder klassischen Anruf. Diese nun zumindest theoretisch mögliche Rund-um-die-Uhr-Erreichbarkeit hat wiederum Auswirkungen auf das Kommunikationsverhalten und die Erwartungen, die daran geknüpft sind. Denn offenbar wird im Zuge der Mediatisierung die Möglichkeit der Nicht-Erreichbarkeit ausgeklammert oder zumindest stark vernachlässigt (Lautenschläger, 2021), was sich an Beispiel 4 und besonders an Beispiel 5 nachvollziehen lässt.

Abb. 2 Kommunikative Erwartungshaltung (eigenes Korpus)
Durch die Äußerungen „Danke für die Antwort“ und „Okay dann halt nicht!!“ wird nicht nur erkennbar, dass es einen (zumindest einseitig vorausgesetzten) normativen zeitlichen Rahmen gibt, innerhalb dessen eine Reaktion erfolgen muss, sondern auch, dass er überschritten wurde, weshalb Interventionen (s. Abschnitt 4) stattgefunden haben 2. In beiden Fällen wird diese Redezugvakanz (Bergmann, 1982; s. auch Abschnitt 3.1) durch Unerreichbarkeit („Hatte mein Handy nicht am Schreibtisch“; „Hab mein Handy nicht immer in der Hand!“) entschuldigt bzw. begründet, was in Beispiel 5 durch die Re-Reaktion („Ja ist klar“) als unglaubwürdige Ausrede bezeichnet wird. Dies wiederum verweist auf die Annahme, dass das Gegenüber das Smartphone (fast) immer mit sich führt und eine Nicht-Reaktion durch Nicht-Erreichbarkeit (= Still-Sein, s. u.) daher tendenziell ausgeschlossen ist, weshalb von einer intendierten kommunikativen Handlung (= Schweigen, s. u.) ausgegangen wird.
Messenger wie Whatsapp 3 gelten als primär schriftbasierte Kommunikationsplattformen (Dürscheid & Frick, 2016, 60), die aber neben der Standardmodalität der Schrift auch weitere semiotische Ressourcen anbieten wie Emojis, Sticker, GIFs, Videos oder Audio-Formate (Sprachnachrichten). Relevant sind hier die schriftbasierten Textnachrichten, also die Kommunikationsform Chat 4, bei der zentral ist, dass die Interagierenden in der Regel sowohl räumlich als auch zeitlich getrennt, also entkontextualisiert sind (Höflich, 2016, 45); die Kommunikation erfolgt daher quasi-synchron oder asynchron, aber niemals simultan bzw. synchron 5.
KtS-Kommunikation, also Kommunikation, die über eine Tastatur getippt und auf den Bildschirm der Empfänger*innen übermittelt wird (Dürscheid & Frick 2014), ist nicht nur entgrenzt, sondern auch entkontextualisiert: Da die sprachliche Interaktion von überall aus möglich ist, wissen die Schreibenden voneinander nicht ganz genau, in welchen konkreten Kontexten sich das Gegenüber gerade befindet. Damit ist auch nicht einschätzbar, ob der schriftliche Austausch das dominante Engagement oder lediglich als Zeitvertreib das untergeordnete Engagement darstellt. Mit untergeordnetem Engagement meint Goffman (2009, S. 60), dass
„der Einzelne es nur in dem Maße und so lange pflegen darf, wie seine volle Aufmerksamkeit nicht vom dominanten Engagement gefordert ist. Untergeordnete Engagements gehen gedämpft, abgestimmt und diskontinuierlich vonstatten“.
Fahre ich also gerade in der Straßenbahn und schreibe meinem Gegenüber, unterbreche ich den Chat, sobald ich aussteigen muss – die Fortbewegung ist das dominante, die Kommunikation das untergeordnete Engagement. Teile ich dabei meinem Gegenüber nicht mit, wo bzw. in welcher Situation ich mich gerade befinde, dann kann das abrupte Enden meines Engagements Irritationen auslösen und zu Interventionsstrategien führen, die das Schweigen bzw. Still-Sein (s. Abschnitt 3) beenden sollen.
Insbesondere Whatsapp bietet zudem eine Vielzahl an awareness cues, d. h. Informationen auf der Benutzeroberfläche (Mai & Wilhelm, 2015, S. 14) mit sozialer Kontrollfunktion, die Auswirkungen auf die Interaktion haben und sich auf die Interpretation von Schweigen auswirken, was Beispiel 6 gut demonstriert.
Neben der Möglichkeit, den Online-Status zu aktivieren und dadurch erkennen zu können, an welchem Tag und zu welcher Uhrzeit das Gegenüber die App das letzte Mal geöffnet hat 6, kann die Lesebestätigung aktiviert werden. Diese zeigt durch das Blaufärben der Haken an, ob eine Nachricht gelesen wurde bzw. ob der Chat geöffnet wurde, nachdem die Nachricht dort versendet wurde. Und genau diese Nachprüfbarkeit hat nun interaktive Konsequenzen:

Abb. 3 Lesebestätigung und ihre interaktive Wirkung (eigenes Korpus)
Sobald eine Nachricht als gelesen bzw. abgespielt markiert wurde 7, können Unsicherheiten darüber entstehen, warum das Gegenüber noch nicht geantwortet hat, wenn es doch die Nachricht abgehört bzw. gelesen oder zumindest wahrgenommen haben muss. Kurzum: Nur weil auf der Äußerungsebene nichts passiert, gilt dies nicht analog auch für die Interaktionsebene.
Wie Abb. 3 zeigt, findet im Zeitraum von 09:43 Uhr bis 10:11 Uhr nichts statt, es werden keine Nachrichten ausgetauscht; trotzdem stellt Person B 8 nach 28 Minuten die Frage „Bist du jetzt sauer?“ – und diese Frage zeigt, dass zumindest in der Wahrnehmung von B nicht nichts, sondern etwas Negatives geschehen ist und sich durch Schweigen manifestiert. Durch die Nachprüfbarkeit des Abhörzeitpunktes – A hat die Nachricht nicht nur sofort gesehen, sondern auch abgehört – geht B offenbar davon aus, dass A kommunikativ verfügbar ist, weshalb dessen Redezugvakanz (s. u.) als markiertes, d. h. kommunikativ bedeutsames Schweigen interpretiert und als Reaktion auf den Inhalt der Sprachnachricht gedeutet wird. Mit der Nachfrage „Bist du jetzt sauer?“ soll nach 28-minütiger Vakanz nicht nur das Schweigen gebrochen, sondern auch überprüft werden, ob es sich wirklich um Schweigen handelt, und wenn ja, mit welcher Bedeutung es (nicht) zu verstehen ist. Bevor detaillierter auf solche und ähnliche Interventionsstrategien eingegangen wird, soll zunächst die Vielfältigkeit von Schweigen skizziert werden.
3 (Graduelles) Schweigen, Still-Sein und Schweigearten
Schweigen ist nicht gleich Schweigen, denn zu differenzieren sind nicht nur verschiedene Arten des Schweigens, also etwa Still-Sein, verschiedene Arten der Pause (Bergmann, 1982; Meise, 1996; Schwitalla, 2012) oder konventionelles und markiertes Schweigen, sondern innerhalb dieses kommunikativen Schweigens ist noch zwischen verschiedenen Intensitätsgraden zu unterscheiden (s. Abb. 6), die auch von der jeweiligen Kommunikationsform abhängen. Zunächst soll aber Abb. 4 einen übergeordneten, von Kommunikationsformen abstrahierenden Überblick gewährleisten.

Abb. 4 Schweigearten (Lautenschläger i. V.)
Da linguistische Auseinandersetzungen mit Schweigen bisher primär anhand mündlich geführter Face-to-Face-Gespräche innerhalb der Gesprächslinguistik stattgefunden haben, überrascht es wenig, dass hier mit deren Termini und Kategorien operiert wird. Da aber evident ist, dass es Unterschiede zwischen medial mündlichem und medial schriftlichem Schweigen gibt, müssen einige Schweigephänomene im Zusammenhang mit schriftlicher Interaktion verworfen oder kommunikationsformadäquat modifiziert werden 9, was im Rahmen dieses Beitrages allerdings nicht geleistet werden kann.
Im Hinblick auf die hier relevante KtS-Kommunikation interessieren daher nur die durch Umrandung hervorgehobenen Phänomene (besonders das markierte Schweigen bzw. die Redezugvakanz), die Parallelen zwischen mündlich und schriftlich realisierter Kommunikation aufweisen (s. Abschnitt 4), aber eben nicht identisch sind (s. Abschnitt 3.2). Um sie adäquat analysieren zu können, ist es zuvor aber notwendig, ein Schweigen von einem Still-Sein (Stille) abzugrenzen.
Um beide Phänomene unterscheiden zu können, muss die (Zuschreibung von) Intentionalität 10 herangezogen werden, auch wenn gerade dieses Kriterium in KtS-Kommunikation wegen der Entgrenzung und Entkontextualisierung nicht bzw. kaum prüfbar ist. Denn Schweigen ist analog zum Sprechakt als Schweigakt zu verstehen, bei dem eine finale kommunikative Handlungsintention vorliegt; es wird also kommunikativ-intendiert eingesetzt. Abzugrenzen davon ist Still-Sein als kommunikativ bedeutungsloser und unmarkierter Zustand des Sich-nicht-Äußerns (Meise, 1996, S. 16). Bei dieser Unterscheidung kann es in der kommunikativen Praxis – und das indizieren die Pfeile in der Grafik – durchaus zu Verwechslungen kommen. Dadurch, dass Schweigen und Still-Sein beide materiell nichts sind und sich als Fehlen von etwas manifestieren, sind der Kontext – und dazu zählt ganz maßgeblich sowohl das Wissen darüber, in welcher Situation sich das Gegenüber gerade befindet, als auch generelles Wissen über dessen typisches Kommunikationsverhalten – und mit ihm auch besagte awareness cues (zunächst) die einzige Möglichkeit der Bedeutungsentschlüsselung.
In einer Face-to-Face-Situation hingegen ist die Frage, ob es sich um eine Handlung (Schweigen) oder einen Zustand (Stille) handelt, einfacher zu beantworten: Teilt man sich beispielsweise ein Büro und arbeiten beide Personen konzentriert an ihren PCs, dann ist das Nicht-Sprechen der beiden Parteien nicht als Schweigen, sondern als Still-Sein zu verstehen. Wenn mein Gegenüber mich dann in dieser Situation anspricht, ich aber nicht antworte, weil ich so vertieft in meine Arbeit bin, kann es meine Nicht-Reaktion durch einen kurzen Blick überprüfen und feststellen, dass es sich dabei weniger um ein Schweigen handelt als um ein auf konzentriertes Arbeiten zurückzuführendes Still-Sein. Diese Art der Rückversicherung ist bei Whatsapp-Kommunikation nicht gegeben. Will man dort auf dieser grundlegenden Ebene Missverständnisse verhindern, empfiehlt es sich, kommunikative Vorkehrungen zu treffen, wie sie in Abb. 5 zu sehen sind:

Abb. 5 Kommunikative Vorkehrung (eigenes Korpus)
Durch den Hinweis darauf, dass man noch einkauft, wird dem Gegenüber verdeutlicht, dass man, wie die Lesebestätigung erkennen lässt, die Nachricht zwar bereits gelesen hat, aber nicht (angemessen) darauf reagieren kann, weil das dominante Engagement gerade beim Einkaufen liegt und man somit nicht kommunikativ bedeutsam schweigt, sondern lediglich still ist.
Für kommunikatives und insbesondere markiertes Schweigen lässt sich abschließend Folgendes festhalten (vgl. Lautenschläger i. V.): Es ist …
1. … zwar das Fehlen von Rede, aber nicht von Kommunikation;
2. … materiell und syntaktisch nichts, aber semantisch alles;
3. … multifunktional und ambig;
4. … äußerst stark kontextabhängig und somit auch
5. … rezipientenabhängig: Es existiert nur dann, wenn das angeschwiegene Gegenüber es als solches (an)erkennt.
Schweigen mag zwar materiell ein Nichts sein – es offenbart sich als ein Fehlen von etwas, das erwartet wurde –, aber gerade durch den Bruch mit Interaktionserwartungen wird es hochgradig bedeutsam (Schmitz, 1990, S. 31): Es ist das Fehlen von Rede, nicht aber das Fehlen von Kommunikation (Jaworski, 1993, S. 46). Schweigen kann ähnliche Funktionen und Bedeutungen haben wie Sprechen; es ist daher ebenso wie Sprechen multifunktional und ambig, wobei die Ambiguität etwas stärker ausgeprägt ist als beim Sprechen. Denn während die Bedeutung von Verbalisiertem durch die konkrete Wortwahl und den Kontext eingegrenzt wird, kann die Bedeutung eines Schweigens ausschließlich über den Kontext konstruiert werden. Mit dieser enormen Kontextabhängigkeit geht auch die Rezipientenabhängigkeit einher: Ob ein Schweigen überhaupt als bedeutsames Schweigen anerkannt wird oder ob man davon ausgeht, dass das Gegenüber lediglich still ist, hängt immer davon ab, welche Interpretation die angeschwiegene Person vornimmt. Neben dem konkreten Kontext, in dem ein Schweigen platziert wird, ist also auch die Beziehungskomponente der Interagierenden und ihr jeweiliges Wissen voneinander enorm bedeutsam. Wenn A von B weiß, dass B immer um 19 Uhr Feierabend macht und sich in der Regel immer erst nach 19 Uhr meldet, auch wenn er oder sie die Nachrichten bereits vorher liest, dann kann A eine Nicht-Reaktion von B also erst nach 19 Uhr als ein bedeutsames Schweigen interpretieren, auch wenn B vielleicht schon seit 15 Uhr beredt schweigt. Hieran wird deutlich, dass – mit sprechakttheoretischen Termini ausgedrückt – nicht die Illokution, d. h. die ‚eigentlich‘ vollzogene Handlung im Fokus steht, sondern die Wirkung, die Perlokution, die ein Schweigen aufseiten der angeschwiegenen Person hat und sich interaktional manifestiert. Sobald A also merkt, dass B schweigt, setzen in der Regel Interventionsstrategien ein (s. Abschnitt 4), wie sie bereits in Abb. 3 erkennbar wurden.
Letztlich gilt: Kommunikatives Schweigen stellt keinen Gegensatz oder Widerspruch zum Sprechen dar, sondern beides sind Kommunikationsmodalitäten mit je eigenen Stärken und Schwächen, wobei allerdings beim Schweigen das „‚Weniger an Schall‘ [bzw. das Weniger an Schrift, SL] […] durch ein ‚Mehr an Wirkung‘ ausgeglichen [wird].“ (Wenderoth, 1998, S. 142)
3.1 Schweigearten
Wie Abb. 4 anzeigt, kann innerhalb des hier relevanten kommunikativen Schweigens generell zwischen konventionellem und markiertem Schweigen differenziert werden. Das konventionelle Schweigen ist in bestimmten Situationen qua Konvention angemessen oder zumindest erwartbar. Ein Beispiel dafür ist das Schweigen aus Höflichkeit, das Jaworski (1993, S. 59) auch als formulaic silence bezeichnet: „Formulaic silence is understood here to be a customary act of saying nothing in reaction to specific stimuli. It occurs when saying something, formulaic or not, would pose a greater threat to another person’s face than remaining silent.“ Markiertem Schweigen hingegen fehlt diese Konventionalität, es wird als Bruch mit der Erwartungshaltung, als (negativ) „markierte[s] Fehlen eines vom Partner erwarteten (Sprachhandlungs-)Tuns“ (Heinemann, 1999, S. 307) aufgefasst.
Die sogenannte Redezugvakanz (Bergmann, 1982) kann dabei, muss aber nicht, mit diesem markierten Schweigen übereinstimmen. Mit Redezugvakanz gemeint ist jener „Typus einer Schweigephase, der dadurch entsteht, daß ein Redezug, zu dessen Übernahme einer der angesprochenen Rezipienten verpflichtet wurde, (zunächst einmal) vakant bleibt.“ (Bergmann, 1982, S. 154) Besonders salient werden Redezugvakanzen bei Paarsequenzen, die der konditionellen Relevanz stark unterworfen sind (Kallmeyer, 1979, S. 70). Konkret heißt dies, dass das Auftreten von Sequenz 1 – z. B. ein Gruß oder eine Frage – das Auftreten von Sequenz 2 – einen Gegengruß oder eine Antwort – konventionell hochgradig erwartbar macht. Bleibt Sequenz 2 aber aus, ist dies dispräferiert (s. u.) und markiert, wobei es dann die Aufgabe der sequenzinitiierenden Person ist, das Schweigen des Gegenübers zu interpretieren, denn
[d]ieses ‚Nichts‘ […] offenbart ja als solches nicht, was es bedeutet oder worin es seinen Grund hat. Das Ausbleiben einer konditionell relevanten Folgeäußerung zwingt daher den Sequenzinitiator dazu, sich auf die Suche nach dem Grund oder der Bedeutung dieses ‚Nichts‘ zu machen. (Bergmann, 1982, S. 156)
Diese Suche mündet in verschiedenen Interventionsstrategien, von denen Bergmann in Face-to-Face-Gesprächen vier identifiziert hat, die aber im Hinblick auf KtS-Kommunikation noch um eine fünfte ergänzt werden müssen (s. Abschnitt 4).
3.2 Graduelles Schweigen
Ganz gleich, ob es sich nun um konventionelles oder markiertes Schweigen handelt, lassen sich verschiedene Grade des Schweigens unterscheiden, die wiederum von Kommunikationsform und -modus abhängig sind. Daher werden bei den folgenden Überlegungen die Unterschiede von KtS- und Face-to-Face-Kommunikation explizit hervorgehoben.
Mit absolutem Schweigen ist gemeint, dass wortwörtlich nichts übermittelt wird: kein Laut, keine Gestik, keine Mimik. Es kann daher nur in KtS-Kommunikation auftreten, nicht aber in zwangsläufig multimodal ablaufender Face-to-Face-Interaktion, da hier zwar nonvokal interagiert werden kann, aber unvermeidlich im gemeinsam erlebten Wahrnehmungsraum nonverbale Informationen übertragen würden 11 und somit nicht nichts vermittelt wird. Absolutes Schweigen ist demnach nonvokal und zudem averbal in dem Sinne, dass weder eine sprachliche Äußerung getätigt wird noch körpersprachliche (proxemische, mimische, gestische) Elemente vorliegen. Das Maximum an Informationsübermittlung stellt die Lesebestätigung dar, anhand derer überprüft werden kann, ob die Nachricht gelesen bzw. der Chat geöffnet wurde (vgl. Beispiel 6 aus Abb. 3).
Das andere Ende der Skala bildet das verbale Schweigen, das „Schweigen im Reden, das Schweigen mit dem Wort“ (von Sass, 2016, S. 15, Herv. i. O.), das auch als Thematisierungsverzicht oder als Um-den-heißen-Brei-Herumreden bezeichnet werden kann.

Abb. 6 Graduelles Schweigen (Lautenschläger i. V.)
Zwischen diesen zwei Extremen finden sich das explizite und das implizite Schweigen (Bilmes, 1994). Ersteres bezieht sich darauf, dass keine Laute oder Schriftzeichen produziert werden, aber durch nonverbale Körpersprache etwas zum Ausdruck kommt. Hier wird erkennbar, dass explizites Schweigen nicht in KtS-Kommunikation auftreten kann, sondern lediglich in Face-to-Face-Interaktionen. Das implizite Schweigen bezieht sich auf Minimalreaktionen wie Emojis oder knappe Äußerungen 12 und lässt sich sowohl bei Face-to-Face-Gesprächen als auch bei Whatsapp-Chats erkennen.

Abb. 7 Implizites Schweigen (Quellen: 8: https://ask.fm/SchoenePictures/answers/112671734035; 9: eigenes Korpus)
Emojis sind als digitales Äquivalent zu Gestik und Mimik zu verstehen: Als ikonifiziert-indexikalische Zeichen imitieren und simulieren sie z. B. Gesichtsausdrücke und üben dadurch u. a. kontextualisierende Funktionen aus, zeigen also etwa an, dass eine sprachliche Äußerung spaßig gemeint ist (Beißwenger & Pappert, 2019). Da die Emojis aber bewusst und willentlich ausgewählt werden müssen und nicht wie reguläre Körpersprache zum Teil unbewusst ausgedrückt werden, sind sie in der Skala beim impliziten Schweigen angesiedelt. Auch kurze verbale Äußerungen, die entweder als (konventionell) angemessen oder (markiert) unangemessen interpretiert werden können, sind als (mögliches) implizites Schweigen zu kategorisieren. In Abb. 7 fällt bei beiden Beispielen durch die jeweilige Reaktion auf, dass sie als Problemindikatoren fungieren: In Beispiel 8 kann die (offenbar polysem gewordene) Partikel okay nicht gedeutet werden, weshalb eine Vielzahl möglicher Lesarten aufgezeigt wird, während in Beispiel 9 die Partikel aha in Kombination mit dem nüchtern wirkenden Schlusspunkt 13 (Dürscheid & Frick, 2016, S. 93) als Ausdruck von Kränkung bzw. Schmollen (Wenderoth, 1998) interpretiert wird, weshalb eine Rechtfertigung erfolgt, die mit einer Entschuldigung eingeleitet wird.
An Beispiel 9 ist außerdem erkennbar, dass bei sprachlichen Interaktionen zusätzlich zur konditionellen Relevanz eine Präferenzorganisation vorliegt (vgl. Levinson, 1990/1983). Das bedeutet, dass es bestimmte, unmarkierte Reaktionen auf eine Aktion gibt, die man als first priority response (Bilmes, 1994) bezeichnet. Frage ich mein Gegenüber „Willst du morgen mit mir einen Kaffee trinken?“, dann hoffe ich, dass die Antwort „Ja“ lautet; eine dispräferierte Reaktion ist ein Nein und eine noch stärker dispräferierte Reaktion ist ein markiertes Schweigen, das ebenfalls mit einem Nein gleichgesetzt würde (Meise, 1996, S. 64), aber zusätzlich noch mit der Erwartungshaltung bräche, überhaupt eine verbale Reaktion zu erhalten. Bleibt die präferierte Variante aus und wird durch Schweigen oder knappe Äußerungen wie „Aha.“ ersetzt, handelt es sich um markierte, nicht-bevorzugte zweite Teile, die je nach kommunikativem Kontext Interventionsstrategien oder andere interaktive Bearbeitungsschritte (wie die Rechtfertigung) auslösen können.

Abb. 8 Konditionelle Relevanz ohne Paarsequenz (eigenes Korpus)
Zudem zeigt sich an Beispiel 9, noch deutlicher aber an Beispiel 10, dass präferierte Reaktionen nicht nur an konventionalisierte Paarsequenzen gebunden sind, sondern generell an Erwartungshaltungen, die sich auch aus der Beziehung der Interagierenden ergeben.
Auf diesen assertiven Sprechakt, der eine Folgeäußerung nicht zwingend erwartbar macht, erfolgt nach ca. 8 Stunden verstrichener Zeit ein direktiver Sprechakt, der als erster Teil einer Paarsequenz fungiert und somit einen zweiten Teil verlangt, der dann mit einer Erklärung, warum die präferierte Reaktion ausgeblieben ist, letztlich erbracht wird.
Da, wie erwähnt, nicht zweifelsfrei erschlossen werden kann, ob es sich um Schweigen oder Still-Sein handelt und welche Bedeutung das (vermeintliche) Schweigen haben könnte, geht Person A hier mit der Frage „Antwortest du nicht mehr?“ inklusive des Erstaunen ausdrückenden Emoticon „:o“ auf die bereits thematisierte Suche nach dem Grund für die fehlende Reaktion, sprich: Sie wendet eine Interventionsstrategie an. Dabei ist die Basis der Interventionen stets, dass die Zeitspanne überschritten wurde, in der die „normative Erwartung, daß der Gesprächsteilnehmer, der am Zug ist, seiner Redepflicht schon noch nachkommen wird“ (Bergmann, 1982, S. 158), hätte aufrechterhalten werden können. Wie viel Zeit dem Gegenüber dabei eingeräumt wird, hängt wiederum von der Beziehung der Interagierenden und deren Wissen voneinander ab.
4 Interventionsstrategien
Bezogen auf aufgezeichnete und transkribierte Face-to-Face-Kommunikation stellt Bergmann (1982, S. 167 ff.) für Schweigephasen im Gespräch insgesamt vier Interventionsstrategien fest, die das Schweigen des Gegenübers beenden sollen:
Wiederholung
Selbstkorrigierende Intervention (Reformulierung)
Korrekturinitiierende Intervention (Fokussierungsaufforderung)
Explizite Formulierung der Interpretation
Obwohl diese kommunikativen Phänomene in einer anderen Kommunikationsform erhoben wurden, lassen sich diese Strategien, z. T. etwas modifiziert, auch auf die hier relevante KtS-Kommunikation übertragen und sollen von mir um einen fünften Punkt ergänzt werden:
Zurück-Schweigen

Abb. 9 Wiederholung, Reformulierung und Re-Thematisierung (eigenes Korpus)
Die Strategien 1 und 2 überschneiden sich im vorliegenden Datenmaterial und können am treffendsten als Verdacht des Überlesens beschrieben werden.
Für Face-to-Face-Gespräche konstatiert Bergmann, dass Wiederholungen zwei Grundbedingungen haben:
Zum einen gründet sich die Wiederholung einer sequenzinitiierenden Äußerung auf die Möglichkeit, daß diese Äußerung gar nicht beim Rezipienten ‚angekommen‘ ist und eben deshalb der nochmaligen Formulierung bedarf. […] Zum anderen aber kommt in der unveränderten Wiederholung einer sequenzinitiierenden Äußerung zum Ausdruck, daß für den Sprecher diese Äußerung selbst nicht korrekturbedürftig ist, sie vielmehr so, wie sie formuliert wurde, in Ordnung und verstehbar war. (Bergmann, 1982, S. 167)
Für selbstkorrigierende Interventionen stellt er fest, dass „ein Sprecher zu verstehen gibt, daß er in seiner eigenen ersten Äußerung die Störungsquelle sieht, auf die die Schweigereaktion des Rezipienten sich zurückführen läßt“ (Bergmann, 1982, S. 168), sodass die Äußerung reformuliert wird, um die Störung zu beseitigen.
Bei Whatsapp-Chats hingegen zeigt sich im Korpus, dass 1:1-Wiederholungen trotz Copy-and-Paste-Möglichkeit nur dann vorkommen, wenn sie mit der Antwortfunktion einhergehen, dabei aber häufig von einem reformulierten Text begleitet werden, der eine Re-Thematisierung bezweckt, wie sie sich in Beispiel 11 ganz rechts finden lässt.

Abb. 11 Explizites Formulieren der Interpretation (eigenes Korpus)
Der Unterschied, der sich zu Bergmanns Feststellungen ergibt, ist der, dass hier zum einen ein verbales Schweigen vorliegt: Die Interagierenden schreiben einander, ohne das Thema – hier: die Schönheit des Autos – aufzugreifen, was sich in Einklang bringen lässt mit der Annahme, dass die „Äußerung gar nicht beim Rezipienten ‚angekommen‘ ist“ (Bergmann, 1982, S. 167). Sie wurde also ggf. flüchtig wahrgenommen, aber nicht registriert und beantwortet. Bei der Re-Thematisierung einen Tag später 14 im Ausschnitt rechts zeigt sich dann die Überschneidung von der Reformulierung („Wie findest du ihn denn eigentlich?“) mit der auf die Antwortfunktion mit zitiertem Text zurückgehenden Wiederholung („Schatz, schau doch wie stilvoll er von innen ist“). Die Reformulierung findet hier aber offenbar nicht unter der Annahme statt, dass die ursprüngliche Formulierung undeutlich gewesen wäre, sondern unter dem besagten Verdacht des Überlesens.
Korrekturinitiierende Interventionen, die sich als Fokussierungsaufforderung manifestieren, lassen sich analog zu Bergmanns Beispielen sehr häufig finden. Dabei
gibt der Sequenzinitiator durch eine solche Intervention auch zu verstehen, daß nach seiner Ansicht die nicht auf ihn fokussierte Aufmerksamkeit des Rezipienten der Grund für das entstandene Schweigen ist. Die Fokussierungsaufforderung dient also dazu, eine Korrektur des Orientierungszustandes des Rezipienten zu initiieren […]. (Bergmann, 1982, S. 177)
Der einzige Unterschied zwischen Face-to-Face- und KtS-Kommunikation besteht darin, dass sich bei Ersterer leichter feststellen lässt, ob das geführte Gespräch das dominante oder untergeordnete Engagement darstellt, was bei der entkontextualisierten KtS-Kommunikation nicht zweifelsfrei gelingt. Als häufiger Aufmerksamkeitserreger gilt Hallo? oder aber auch das (iterierte) ?.
Wie vor allem Beispiel 12 zeigt, kann die Fokussierungsaufforderung auch mit Strategie 4, der expliziten Formulierung der Interpretation einhergehen, die bereits in Beispiel 6 („Bist du jetzt sauer?“) begegnete. Während bei den anderen drei Strategien die Interpretation des Schweigens lediglich implizit bleibt, wird sie hier verbalisiert und lässt Rückschlüsse darüber zu, wie die angeschwiegene Person das Schweigen einschätzt. Während bei Beispiel 6 von einer wie auch immer gearteten Verfehlung ausgegangen wird, die das Gegenüber verärgert haben könnte 15, geht A in Beispiel 12 zunächst davon aus, dass bei B ‚irgendetwas nicht gut‘ sein könnte, weshalb die Frage „Alles gut?“, gefolgt von der Fokussierungsaufforderung „??“ formuliert wird. Nach ca. 2,5 Stunden Wartezeit findet sich ein erneutes Explizieren der Interpretation des Schweigens, bei der von absichtlicher Ignoranz ausgegangen wird.

Abb. 11 Explizites Formulieren der Interpretation (eigenes Korpus)
Dass Schweigen eine dispräferierte Reaktion darstellt und überhaupt als Reaktion wahrgenommen wird – man beachte die Lesebestätigung und die Äußerung „Ich sehe dass du es gelesen hast …“ in Beispiel 17 16 –, zeigt sich jeweils in den Ausformulierungen, die die Bedeutung des Schweigens als auf Unlust bzw. Desinteresse beruhende Absage erkennen lässt.
All diese Strategien werden genutzt, um die Redezugvakanz – und damit ist sowohl das markierte Schweigen als auch das Übergehen bestimmter Themen, also das verbale Schweigen, gemeint – zu beenden und das Gegenüber dazu zu bewegen, seinen Redezug zu übernehmen.
Darüber hinaus lässt sich eine fünfte Strategie, das Zurück-Schweigen, beobachten. Die Besonderheit in der Erforschung des Zurück-Schweigens liegt darin, dass sie ausschließlich in der Metakommunikation mit am eigentlichen Chat Unbeteiligten erhoben werden kann.
Anstatt die zuerst schweigende Person also (konfrontativ) auf ihr Schweigen anzusprechen bzw. eine der anderen Interventionsstrategien anzuwenden, wird ein Zurück-Schweigen geplant, das offenbar dazu dient, Desinteresse zu simulieren und dem Gegenüber anzuzeigen, dass man ihm keine hohe Priorität im eigenen Leben einräumt (Lautenschläger, 2021). Ziel ist es – hier sei an Beispiel 3 in Abb. 1 erinnert –, länger zu schweigen und dadurch ‚zu gewinnen‘, sprich: das Gegenüber zu einer verbalen (Re-)Aktion zu bewegen.

Abb. 12 Metakommunikation über strategisches Zurück-Schweigen (eigenes Korpus)
Die Beispiele 18 und 20 verweisen darauf, dass sich das strategische und geplante Schweigen als ein psychischer Kraftakt erweist („Ich muss mich schon wieder total zusammen reißen […]“; „Wird gar nicht so einfach“), den zu vollbringen sich aber letztlich lohnt. Dabei ist es wichtig, das kommunikative Schweigen als Still-Sein auszugeben, um die gewünschte Wirkung zu erzielen. So merkt die Studentin, die Beispiel 20 zum Korpus beigesteuert hat, an: „Zumindest hat das anschweigen [sic!] geholfen, da dann wieder von ihm zumindest ein ‚Na du‘ kam und eine Konversation eingeleitet wurde :-)“.
Es stellt allerdings eine Schwierigkeit dar, den Nachweis zu erbringen, dass ein Schweigen im entsprechenden Chat tatsächlich als Still-Sein ausgegeben wird. Prinzipiell gelingt dies nur, wenn die Metakommunikation über das geplante Schweigen und der tatsächlich betroffene Chat vorliegen, was in Beispiel 21 der Fall ist. In diesem speziellen Kontext handelt es sich aber nicht um den Versuch, die Redezugvakanz des Gegenübers zu beenden, sondern – und das lässt sich aus dem Begleittext erschließen, den die Studentin mit dem Screenshot eingereicht hat – um eine Höflichkeitshandlung:
Ich erzählte meiner besten Freundin erneuert [sic!] von dem Verhalten von X. und meinte, in der Sprachnachricht, dass ich X entweder meine Meinung sagen will oder einfach nicht darauf reagieren will. Darauf meinte meine beste Freundin, dass sie einfach nicht antworten würde, was ich dann auch nicht tat.
Statt also eine Imageverletzung zu begehen und X ‚die Meinung zu sagen‘, wird diese konfrontative Handlung ausgelassen und durch als Still-Sein getarntes Schweigen substituiert. Mit der entschuldigenden Behauptung, bereits geschlafen zu haben, wird zudem ein weiterer möglicher Konflikt vermieden, der aufkommen könnte, wenn das Schweigen offenkundig als markiertes Schweigen bzw. Schmollen ausgeübt würde, denn: „Schmollen weist die Verantwortung für das Vorgefallene dem oder den ‚Angeschmollten‘ zu“ (Wenderoth, 1998, S. 144) und kann entsprechend als Vorwurf gedeutet werden, der seinerseits wiederum zu Gegenvorwürfen führen kann (z. B. Hundsnurscher, 2001).

Abb. 13 Schweigen, das als Still-Sein getarnt wird (eigenes Korpus)
5 Fazit
Schweigen ist ein vielschichtiges interaktives Kommunikationsmittel, das zwar materiell nichts ist und als Fehlen von Rede konzipiert wird, aber gerade durch dieses markierte Fehlen seine Wirksamkeit entfaltet.
Schweigen existiert auch jenseits des Verbal-Prosodischen und nimmt, das konnten die Beispiele zeigen, in der KtS-Kommunikation einen hohen Stellenwert ein: Dadurch, dass wir durch das Smartphone theoretisch rund um die Uhr erreichbar sind und mehr Reden möglich wird, wird automatisch auch mehr Schweigen möglich. Während bei Face-to-Face-Kommunikation auf Grundlage des gemeinsamen Wahrnehmungsraumes mehr kontextuelle Möglichkeiten zur Verfügung stehen, ein Schweigen zu dechiffrieren und es von einem etwaigen Still-Sein zu unterscheiden, sind die Interagierenden in digitaler, schriftlich vermittelter Kommunikation entkontextualisiert und in hohem Maße auf ihr Wissen über das Gegenüber und dessen typische Kommunikationsroutinen angewiesen. Soziale Kontrollmechanismen wie der Online-Status oder die Lesebestätigung können dabei, wenn sie aktiviert sind, zusätzliche Orientierung bieten, aber auch zu Verunsicherungen führen und schon nach relativ kurzer Redezugvakanz zu Interventionsstrategien führen, wie sie in Abschnitt 4 diskutiert wurden. Dabei manifestiert sich im Hinblick auf KtS-Kommunikation eine Taktik, die von den aus Face-to-Face-Gesprächen abgeleiteten Interventionsmöglichkeiten abweicht: das Zurück-Schweigen. Letztlich zeigt sich besonders an dieser Strategie, wie sehr Schweigen mit Provokation und Prävention, aber auch mit Macht und Dominanz einhergeht: So soll es einerseits das zuerst schweigende Gegenüber zu einer (Re-)Aktion provozieren bzw. animieren und dabei den Eindruck von Abhängigkeit oder des Hinterherlaufens verhindern sowie eine eigene Stärkeposition markieren bzw. simulieren, andererseits kann Schweigen auch präventiv wirken und (möglicherweise) konfliktauslösende verbale Äußerungen substituieren.
Schweigen ist nicht Nichts. Auch wenn es nur eine Form hat – das merkliche Fehlen von Schall bzw. Schrift –, besitzt es doch verschiedene Funktionen, Bedeutungen und auch graduelle Abstufungen: Es bewegt sich zwischen den Extremen des absoluten und verbalen Schweigens und kann explizit oder implizit realisiert werden. Dabei kann es, stets abhängig vom jeweiligen Kontext, als konventionelles und somit erwartbares oder aber als unerwartet-markiertes Schweigen gemeint bzw. gedeutet werden.
Doch ganz gleich, in welcher Spielart es eingesetzt bzw. interpretiert wird: Schweigen ist innerhalb (und außerhalb) digitaler Kommunikation ein zentrales Mittel und hat eine große kommunikative Wirkmacht, der man (nicht nur) in linguistischen Betrachtungen gerecht werden sollte, will man die Kommunikation in einer digitalen Welt und auch jenseits davon umfänglich untersuchen.
Literatur
Androutsopoulos, J. (2018). Digitale Interpunktion: Stilistische Ressourcen und soziolinguistischer Wandel in der informellen digitalen Schriftlichkeit von Jugendlichen. In A. Ziegler (Hrsg.), Jugendsprachen/Youth Languages. Aktuelle Perspektiven internationaler Forschung/Current Perspectives of International Research. (S. 721–748). de Gruyter.
Beißwenger, M. & Pappert, S. (2019). Handeln mit Emojis. Grundriss einer Linguistik kleiner Bildzeichen in der WhatsApp-Kommunikation. Universitätsverlag Rhein-Ruhr.
Bergmann, J. R. (1982). Schweigephasen im Gespräch – Aspekte ihrer interaktiven Organisation. In H.-G. Soeffner (Hrsg.), Beiträge zu einer empirischen Sprachsoziologie. (S. 143–184). Narr.
Bilmes, J. (1994). Constituting silence: Life in the world of total meaning. In Semiotica 98(1/2), 73–87.
DGSS (2020): https://www.dgss.de/aktuelles/tagungen/ [Zugriff am 11.05.2021]
Dürscheid, C. (2020). Zeichen setzen im digitalen Schreiben. In J. Androutsopoulos & F. Busch, Register des Graphischen. Variation, Interaktion und Reflexion in der digitalen Schriftlichkeit. (S. 31–51). de Gruyter.
Dürscheid, C. (2005). Medien, Kommunikationsformen, kommunikative Gattungen. Linguistik Online, 22 (1).
Dürscheid, C. & Frick, K. (2016). Schreiben digital. Wie das Internet unsere Alltagskommunikation verändert. Alfred Kröner Verlag.
Dürscheid, C. & Frick, K. (2014). Keyboard-to-Screen-Kommunikation gestern und heute: SMS und WhatsApp im Vergleich. In A. Mathias et al. (Hrsg.), Sprachen? Vielfalt! Sprache und Kommunikation in der Gesellschaft und den Medien. (S. 149-181). Networx Nr. 64.
Goffman, E. (2009). Interaktion im öffentlichen Raum. Campus Verlag. Übersetzte Neuausgabe des Originals von 1963.
Heinemann, W. (1999). Das Schweigen als linguistisches Phänomen. In H. Eggert & J. Golec (Hrsg.), „… wortlos der Sprache mächtig“. Schweigen und Sprechen in der Literatur und sprachlicher Kommunikation. (S. 301–314). Metzler.
Höflich, J. R. (2016). Der Mensch und seine Medien. Mediatisierte interpersonale Kommunikation. Eine Einführung. Springer.
Hundsnurscher, F. (2001). Streitspezifische Sprechakte. Vorwerfen, Insistieren, Beschimpfen. In G. Preyer, M. Ulkan & A. Ulfig (Hrsg.), Intention – Bedeutung – Kommunikation. Kognitive und handlungstheoretische Grundlagen der Sprachtheorie. (S. 363–375). Humanities Online.
Jaworski, A. (1993). The Power of Silence. Social and Pragmatic Perspectives. Sage Publications Inc.
Kallmeyer, W. (1979). Kritische Momente. Zur Konversationsanalyse von Interaktionsstörungen. In W. Frier (Hrsg.), Grundfragen der Textwissenschaft. Linguistische und literaturwissenschaftliche Aspekte. Amsterdamer Beiträge zur neueren Germanistik, Bd. 8. (S. 59–109). Rodopi.
Krotz, F. (2001). Die Mediatisierung kommunikativen Handelns. Der Wandel von Alltag und sozialen Beziehungen, Kultur und Gesellschaft durch die Medien. Westdeutscher Verlag.
Lautenschläger, S. (i. V.). Markiertes Schweigen. Zur Relevanz von Schweigen in digitaler Kommunikation.
Lautenschläger, S. (2021). Willst du gelten, mach dich selten: Tabu und Schweigen in interpersonalen Beziehungen. In K. Kuck (Hrsg.), Tabu-Diskurse. Aptum 02/2021, 212–229.
Levinson, S. C. (1990/1983). Pragmatik. Ins Deutsche übersetzt von Ursula Frieß. Niemeyer.
Mai, L. & Wilhelm, J. (2015). Ich weiß, wann du online warst, Schatz. Die Bedeutung der WhatsApp-Statusanzeigen für die Paarkommunikation in Nah- und Fernbeziehungen. Tectum.
Mayer, H. (2007). Schweigen. In G. Ueding (Hrsg.), Historisches Wörterbuch der Rhetorik, Band 8: Rhet-St. (S. 686–706). Niemeyer.
Meise, K. (1996). Une forte absence. Schweigen in alltagsweltlicher und literarischer Kommunikation. Narr.
Misoch, S. (2006). Online-Kommunikation. UVK Verlagsgesellschaft.
Sass, von H. (2013). Topographien des Schweigens. Eine einleitende Orientierung. In ders. (Hrsg.), Stille Tropen. Zur Rhetorik und Grammatik des Schweigens. (S. 9–29). Verlag Karl Alber.
Saville-Troike, M. (1985). The Place of Silence in an Integrated Theory of Communication. In D. Tannen & M. Saville-Troike (Hrsg.), Perspectives on silence. (S. 3–18). Ablex Publishing Corporation.
Schmitz, U. (1990). Beredtes Schweigen – Zur sprachlichen Fülle der Leere. Über Grenzen der Sprachwissenschaft. In ders. (Hrsg.), Schweigen. Osnabrücker Beiträge zur Sprachtheorie, Bd. 42, 5–58.
Schwitalla, J. (2012). Gesprochenes Deutsch. Eine Einführung. 4., neu bearbeitete und erweiterte Auflage. Erich Schmidt Verlag.
Statista 2021: https://de.statista.com/statistik/daten/studie/181086/umfrage/die-weltweit-groessten-social-networks-nach-anzahl-der-user/ [Zugriff am 11.05.2021]
Statista 2019: https://de.statista.com/statistik/daten/studie/505947/umfrage/reichweite-von-social-networks-in-deutschland/ [Zugriff am 11.05.2021]
Ulsamer, F. (2002). Linguistik des Schweigens. Eine Kulturgeschichte des kommunikativen Schweigens. Lang.
Wenderoth, A. (1998). „Hast du was …?“ – Die stille Gewalt der Schmollenden … Gedanken zu Tätern und Opfern. In F. Januschek & K. Gloy, Sprache und/oder Gewalt? Osnabrücker Beiträge zur Sprachtheorie, Bd. 57, 137–152.
Abbildungsverzeichnis
Siehe PDF-Datei
Autorin

Sina Lautenschläger
Sina Lautenschläger promovierte 2016 zum Thema Geschlechtsspezifische Körper- und Rollenbilder. Eine korpuslinguistische Untersuchung an der Universität Kassel, an der sie bis Januar 2021 als Lehrkraft für besondere Aufgaben tätig war. Seit Februar 2021 arbeitet sie an der Otto-von-Guericke-Universität Magdeburg als wissenschaftliche Mitarbeiterin im Projekt Zwischen Elfenbeinturm und rauer See – zum prekären Verhältnis zwischen Wissenschaft und Politik und seiner Mediatisierung am Beispiel der „Corona-Krise“.
E-Mail: sina.lautenschlaeger@ovgu.de
Kontakt
„Sprechen & Kommunikation – Zeitschrift für Sprechwissenschaft“ wird herausgegeben von der Deutschen Gesellschaft für Sprechwissenschaft und Sprecherziehung e. V.
Erschienen am: 23.09.2022

Maske und Stimmgesundheit
Nach mehr als einem Jahr Maskenpflicht in Schulen berichten Lehrer:innen vermehrt über Stimmprobleme. In diesem Artikel wird eine deutschlandweite Befragung von Lehrer:innen vorgestellt. Von den teilnehmenden 499 Lehrkräften geben 45 % an, seit Beginn der Maskenpflicht Stimmprobleme zu haben. Des Weiteren werden Einschränkungen in Bezug auf Sprachverständlichkeit, Mimik und Gestik sowie Veränderungen im Kommunikationsverhalten genannt.
Auswirkungen des Tragens einer Maske im Schulalltag auf die eigene Wahrnehmung der Stimmgesundheit von Lehrerinnen und Lehrern – Ergebnisse einer deutschlandweiten Umfrage.
von Clara Luise Finke und Marit Fiedler
Schlüsselwörter
Maske, Stimme, Stimmgesundheit, Stimmbeschwerden, Lehrkräfte, Kommunikation
Zusammenfassung
Nach mehr als einem Jahr Maskenpflicht in Schulen berichten Lehrer:innen vermehrt über Stimmprobleme. In diesem Artikel wird eine deutschlandweite Befragung von Lehrer:innen vorgestellt, die im Frühsommer 2021 durchgeführt wurde. Die Ergebnisse zeigen, dass von den teilnehmenden 499 Lehrkräften 45 % angeben, seit Beginn der Maskenpflicht Stimmprobleme zu haben, davon klagen 86 % über eine schnellere Stimmermüdung, 78 % über Heiserkeit, 75 % über eine flache Atmung, 70 % über einen Räusperzwang sowie 59 % über Kehlkopf-Schmerzen. Des Weiteren werden Einschränkungen in Bezug auf Sprachverständlichkeit, Mimik und Gestik sowie Veränderungen im Kommunikationsverhalten (bspw. lauteres Sprechen, deutlicheres Artikulieren oder häufigeres Wiederholen von Äußerungen) genannt. Obwohl ein hoher Prozentsatz der Befragten (73 %) FFP2-Masken während des Unterrichts trägt, scheinen keine allgemeinen Regeln hinsichtlich der Trage- oder Pausenzeiten von Masken an Schulen zu existieren bzw. werden Vorgaben des Arbeitsschutzes nicht eingehalten. Die Ergebnisse der Umfrage zeigen, dass eine stärkere Auseinandersetzung mit diesen Themen stattfinden muss, um einerseits den Infektionsschutz zu gewährleisten und andererseits die Stimmgesundheit im Blick zu behalten.
Keywords
face mask, voice, voice health, vocal strain, teachers, communication
Abstract
After more than a year of wearing masks in schools, teachers are increasingly reporting voice problems. This article presents a Germany-wide survey of tea- chers carried out in the early summer of 2021. The results show that of the 499 participating teachers, 45 % reported voice problems since the start of the mandatory masking, of which 86 % complained of more rapid voice fatigue, 78 % of hoarseness, 75 % of shallow breathing, 70 % of having to clear the throat and 59 % over laryngeal pain. Furthermore, limita- tions on speech intelligibility, facial expressions and gestures as well as changes in communication beha- vior (e. g. speaking louder, articulating more clearly or repeating phrases more frequently) are also men- tioned. Although a high percentage of respondents (73 %) wear FFP2 masks during class, there seem to be no general rules regarding wearing or break times for masks in schools or occupational safety and health requirements are not complied with. The results of the survey show that these issues need to be dealt with more intensively in order to ensure protection against infection on the one hand and to keep an eye on the voice health on the other.
1 Einleitung
Stimmliche Belastungen von Lehrkräften sind aufgrund der aktuellen Pandemie und der damit einhergehenden Hygienebestimmungen deutlich gestiegen und werden in Seminaren, Gesprächen und Einzelsitzungen zunehmend verbalisiert. Im Rahmen von (digitalen) Stimm-Workshopangeboten der Autorinnen im Frühjahr 2021 beschrieben die teilnehmenden Lehrer:innen, dass stimmliche Belastungen „unter den Masken“ erheblich zugenommen hätten und dass verstärkt Heiserkeit und Atemprobleme aufträten.
Das Tragen eines Mund-Nasen-Schutzes aus Gründen des Infektionsschutzes begleitet Lehrer:innen inzwischen seit mehr als einem Jahr. Wurden zu Beginn oftmals noch die sogenannten Alltagsmasken (d. h. Stoffmasken ohne Normierung) eingesetzt, hat sich mittlerweile die Verwendung von medizinischen Masken (OP-Masken) und FFP2-Masken etabliert, die als „Medizinprodukte [...] das Gegenüber vor abgegebenen infektiösen Tröpfchen des Trägers“ schützen sollen (Internetquelle 1). Je nach Infektionsgeschehen in den Bundesländern und den dort geltenden Corona-Verordnungen sowie je nach Schulform differieren die Bestimmungen zum Tragen des Mund-Nasen-Schutzes. Während an Grundschulen zum Beispiel lange Zeit auf eine Maskenpflicht verzichtet wurde, gab es an weiterführenden Schulen (Gymnasien, Realschulen usw.) relativ bald entsprechende Vorgaben. Zunächst nur im Schulgebäude verpflichtend, wurde in Hochzeiten der Pandemie in nahezu allen Schularten auch im Klassenraum und am Sitzplatz eine Maskenpflicht für alle eingeführt.
Dass das Tragen eines medizinischen Mundschutzes Angehörige vieler Berufsgruppen vor (neue) Herausforderungen stellt und zu stimmlichen Beschwerden führen kann, zeigt exemplarisch eine im letzten Jahr veröffentlichte Studie aus Chile. Von 221 befragten Krankenhaus-Mitarbeiter:innen gaben 33 % an, im vorangegangenen Monat Probleme mit ihrer Stimme entwickelt zu haben (Heider et al., 2020). Lehrende bilden bezüglich des Auftretens von Stimmbeschwerden durch dauerhaftes Masketragen also keine Ausnahme. Jedoch besteht die Besonderheit bei Lehrkräften darin, dass ihre Stimmen ohnehin einer außergewöhnlichen Belastung unterliegen (stv. Gutenberg & Pietsch, 2003; Hammann, 2004; Lemke, 2012; Schiller, 2017), denn sie sprechen über viele Jahre täglich mehrere Stunden unter häufig ungünstigen akustischen Bedingungen (Raumverhältnisse, Lärmbelastung) und mentalen Herausforderungen (Klassenführung, Dauer-Präsenz, hohes Konfliktpotenzial). Für ihren sprechintensiven Beruf sind Lehrkräfte – im Gegensatz zu anderen Berufssprecher:innen wie bspw. Schauspieler:innen – meist nicht oder zumindest nicht ausreichend ausgebildet. Dies führt dazu, dass die Wahrscheinlichkeit, an einer berufsbedingten Stimmstörung zu erkranken, sehr hoch ist (stv. Nusseck et al., 2019; Roy et al., 2004; Schiller, 2017; van Houtte et al., 2011).
Es ist anzunehmen, dass das Tragen eines Mund-Nasen-Schutzes die prekäre stimmliche Situation der Lehrkräfte verschärft und zu zusätzlichen Problemen führt – so wird es von Seminarteilnehmer:innen vermehrt geäußert. Die Autorinnen haben daher im Rahmen einer deutschlandweiten Online-Umfrage vom 21.05.2021 bis 21.06.2021 ermittelt, welche Rolle das Masketragen im Schulalltag spielt, inwiefern Lehrkräfte im Schuldienst hierdurch stimmliche Belastungen wahrnehmen und ob sie ggf. bereits erste Schritte eingeleitet haben, um diesen zu begegnen. Im Folgenden werden die Ergebnisse der Befragung vorgestellt und Handlungsempfehlungen abgeleitet. Zuvor werden zwei grundsätzliche Aspekte zu den Rahmenbedingungen des Masketragens im Schulkontext erörtert.
2 Ausgewählte Rahmenbedingungen zum Tragen einer Maske im Schulkontext
2.1 Maskenpflicht und Arbeitsschutz(maßnahmen)
Basierend auf den Vorgaben der SARS-CoV-2-Arbeitsschutzverordnung (Internetquelle 2) gibt die Deutsche Gesetzliche Unfallversicherung (DGUV) Handreichungen zur Durchführung der Gefährdungsbeurteilung aller in Schulen Beschäftigten (d. h. Lehrer:innen, Schüler:innen und Verwaltungsmitarbeiter:innen) heraus und formuliert:
„In Schulen sind Regelungen zum Tragen von und zum richtigen Umgang mit Masken (inkl. Tragepausen) festzulegen. Diese Regelungen sind den Schülerinnen, Schülern und den Lehrkräften im Rahmen einer Unterweisung nahezubringen.“ (Internetquelle 3).
Dabei ist zu unterscheiden, welche Art von Maske (z. B. OP-Maske, FFP2-Maske mit oder ohne Ventil) getragen wird.
Einfache OP-Masken dienen dem Fremdschutz und sind keine Atemschutzgeräte im Sinne der DGUV – im Gegensatz zu den FFP2-Masken. OP-Masken werden allerdings wie FFP2-Masken mit Ausatemventil behandelt (ebd.). Im DGUV-Schreiben zum „Schutzstandard an Schulen“ wird in Bezug auf OP-Masken darauf hingewiesen, dass eine Gefährdungsbeurteilung stattzufinden hat, und für „gesunde Erwachsene mit körperlich leichter Arbeit wird als Ausgangswert für die Gefährdungsbeurteilung eine Tragezeit bis zu drei Stunden empfohlen“ (ebd.). Im DGUV-Schreiben „Empfehlungen zur Tragedauer für Mund-Nase-Bedeckungen“ wird sogar von einer Tragedauer von lediglich „zwei Stunden mit einer anschließenden Erholungsdauer von 30 Minuten“ gesprochen (Internetquelle 4).
Die sogenannten FFP2-Masken hingegen sind
„partikelfiltrierende Halbmasken“ (englisch: „Filtering Face Piece“) und „Gegenstände der persönlichen Schutzausrüstung (PSA) im Rahmen des Arbeitsschutzes. Sie sind ursprünglich als sogenannte ,Staubschutzmaske‘ aus dem Bereich des Handwerks bekannt“ (Internetquelle 5).
Sie schützen bei dichtem Sitz und damit korrekter Anwendung vor Partikeln, Tröpfchen und Aerosolen. Dadurch bieten sie neben dem Fremdschutz auch einen gewissen Eigenschutz. Auch für diesen Maskentyp hat der Arbeitgeber eine Gefährdungsbeurteilung nach DGUV durchzuführen. Die DGUV gibt für FFP2-Masken (ohne Ventil) eine maximale Tragezeit von 75 Minuten an und eine anschließende Pause von 30 Minuten (Internetquelle 6, S. 148). Der Ausschuss für Arbeitsmedizin des Bundesministeriums für Arbeit und Soziales (BMAS) wiederum gibt in seiner Stellungnahme zur „Tragezeitbegrenzungen für FFP2-Masken“ keine generellen Tragezeiten an, es müsse aber eine Gefährdungsbeurteilung stattfinden sowie eine Unterweisung und Beratung von „besonders Schutzbedürftigen“; „Schwangere müssen separat berücksichtigt werden“ (Internetquelle 7). Zudem wird darauf hingewiesen, dass
„unter Berücksichtigung der SARS-CoV-2-Arbeitsschutzregel und der SARS-CoV-2-Arbeitsschutzverordnung im Arbeits- und Gesundheitsschutz stets die Umsetzung des TOP-Prinzips gelten muss und alle technischen und organisatorischen Maßnahmen umgesetzt werden müssen, bevor FFP2-Masken als Schutzmaßnahme eingesetzt werden“ (ebd.).
Das bedeutet, dass FFP2-Masken die letzte Maßnahme im Infektionsschutz und im Rahmen der Gefahrenabwehr sein sollten.
Der Umgang mit der Maskenpflicht ist bundesweit in den Ländern und deren Schulen sehr unterschiedlich geregelt worden. Jede Schulbehörde und jedes Bildungsministerium hat eigene Corona-Schul-Verordnungen erlassen, und die Bestimmungen änderten und ändern sich in regelmäßigen Abständen. Bei einer stichprobenartigen Recherche im Internet finden sich verschiedene Angaben: So sollten bspw. in Bayern FFP2-Masken freiwillig ab 15 Jahren getragen werden, obwohl anscheinend eher OP-Masken empfohlen wurden (Internetquelle 8). Dennoch gab es offenbar Zeiten mit strenger FFP2-Maskenpflicht auf dem ganzen Schulgelände, zumindest beschreibt das ein Artikel aus der Süddeutschen Zeitung vom 14.06.2021 (Internetquelle 9). Demgegenüber gab es bspw. in Niedersachsen keine grundsätzliche Empfehlung zum Tragen von FFP2-Masken an Schulen (Internetquelle 10).
2.2 Verständlichkeit
Ob eine Lehrkraft von ihren Schüler:innen (rein akustisch) verstanden wird, hängt von vielen Faktoren ab: Dazu zählen u. a. die Raumakustik, die Sprechlautstärke und der Grundschallpegel im Unterricht. Um in Bildungsprozessen lernen und sich konzentrieren zu können sowie Stress zu vermeiden, sollte der Grundschallpegel nicht über 30 bis 45 Dezibel (dB) liegen (Schönwälder et al., 2004, S. 116). In der Studie von Schönwalder et al. wurde ein durchschnittlicher Schallpegel von 60 bis 85 dB im Unterricht gemessen (ebd.). Hammann (2004, S. 163) konstatiert sogar, dass laut Studien der Umgebungslärm in 50 % der Sprechzeit bei 80 dB und mehr liegt und im Sportunterricht auch Werte bis zu 115 dB erreicht werden (die konkrete Quellenangabe zu den Studien wird jedoch nicht aufgeführt). Schönwälder et al. (2004) gehen davon aus, dass der „Lärm der mittleren Intensität“ als Belastung und Störung empfunden wird – jener oben genannte gemessene durchschnittliche Umgebungslärm von 60 bis 85 dB im Klassenraum. Um sich akustisch verständlich zu machen, muss eine Lehrkraft also in jedem Fall eine Sprechlautstärke von mehr als 60 dB nutzen. Damit geht sie über die empfohlene Obergrenze der stimmphysiologischen Sprechlautstärke von 60 dB hinaus (Krause et al., 2013, S. 67). Schiller (2017, S. 274 f.) bspw. gibt die durchschnittliche Sprechlautstärke von Lehrkräften mit 75 dB an, was demnach 15 dB über dem für die Stimme unbedenklichen Lautstärkepegel liegt.
Kommt nun die Maske hinzu, findet eine weitere Veränderung der Sprechlautstärke statt. Pörschmann et al. (2020) fanden in akustischen Modellversuchen heraus, dass Masken zu einem grundsätzlichen Übertragungsverlust des erzeugten Sprachsignals führen. Während ein Mikrofaserschal, eine medizinische Einweg- sowie eine einfache Stoffmaske den Sprachschall nur sehr wenig dämpfen, können vor allem Stoffmasken mit doppelter Lage (sogenannte Community-Masken) die Schallabstrahlung in frontaler Richtung um mehr als 10 dB verringern. KN95- sowie FFP2-Masken führen dazu, dass im Bereich zwischen 3 und 5 kHz (das ist der Bereich, der für die Tragfähigkeit einer Stimme und deren klangliche Qualität entscheidend ist, Wendler et al., 2005, S. 84) sogar bis zu 15 dB verloren gehen. Auch Heider et al. (2020, pp. E1227) sprechen davon, dass Gesichtsmasken wie ein akustischer Filter während des Sprechens wirken und insbesondere die hohen Frequenzen beim Sprechen mit Maske um 3 bis 12 dB gedämpft werden. Dies sei jedoch abhängig vom Maskentyp (OP-Maske vs. FFP2-Maske). Jene hohen Frequenzen werden relevant, wenn es einerseits um die Durchschlagskraft (Habermann, 2003, S. 136 ff.) bzw. die Tragfähigkeit einer Stimme geht und andererseits um die Sprechverständlichkeit in Bezug auf die Konsonantenerkennung. Nollmeyer (2014, S. 12) definiert Tragfähigkeit als einen Begriff der Wahrnehmung, der anzeigt, ob eine Stimme gut über Störgeräusche hinweg oder zugleich erklingende Instrumente bzw. Orchesterklänge (wie es bei professionellen Sänger:innen oft der Fall ist) gehört werden kann. Tragfähigkeit bildet sich akustisch als sogenannter Sängerformant (Wendler et al., 2005, S. 84) bzw. Sängerformanten (Wendler & Seidner, 1997, S. 120) ab – für das Sprechen werden diese äquivalent als Sprecherformanten bezeichnet (Knuth, 2018, S. 21 f.). Diese werden bei ca. 3000 Hz gebildet (Nollmeyer, 2010, S. 184) bzw. zwischen 2 und 4 kHz, manchmal auch noch etwas darüber (Föcking & Parrino, 2015, S. 50; Wendler & Seidner, 1997, S. 209). Sängerformanten sind „sich in den Ansatzräumen bündelnde hochfrequente Obertöne im Stimmspektrum“, die sich als „Energiedichten“, d. h. als „auffallend intensives Vorkommen von Obertönen“ (ebd.) im Stimmklang vor allem bei den Vokalen abbilden. Da auch Konsonanten durch den nachfolgenden oder vorhergehenden Vokal beeinflusst werden (sogenannte Koartikulation), können auch diese in der Lautbildung und damit letztlich der Verständlichkeit beeinflusst werden. Frequenzbereiche von über 2 kHz sind außerdem für die Erkennung von Konsonanten (z. B. k, f und s) von Bedeutung. Wenn nun ausgerechnet die Frequenzbereiche zwischen 3 und 5 kHz durch das Masketragen gedämpft werden, können sich die Sprechstimmen von Lehrkräften noch weniger gegenüber dem Umgebungslärm in der Schule behaupten und werden weniger gut verstanden.
Insgesamt lässt sich schlussfolgern, dass Lehrer:innen bereits ohne Maske oft mit erhöhter Sprechlautstärke unterrichten, was auf die Dauer zu Stimmbeschwerden führen kann. Tragen sie nun eine KN95- oder FFP2-Maske, wird ihr Sprechschall um bis zu 15 dB gedämpft. Das bedeutet im Umkehrschluss für die Verständlichkeit: Lehrkräfte müssen eine nochmals erhöhte Sprechlautstärke einsetzen, um von ihren Schüler:innen verstanden zu werden. Werte von 80 bis 90 dB sind dann denkbar, die stark von der physiologischen Sprechlautstärke (bis 60 dB) abweichen und durch die enorme Stimmbelastungen entstehen können. Ähnliches gilt natürlich auch für die Schüler:innen.
3 Untersuchungsdesign
Die Online-Umfrage wurde anonymisiert über LimeSurvey durchgeführt. Sie enthielt 18 Fragen (plus ggf. konkretisierende Folgefragen) in 4 Themenblöcken:
Persönliche Angaben und Ausbildung: Fragen zu Geschlecht, Bundesland und Berufsjahren sowie zur fachlich-pädagogischen Qualifikation und sprecherzieherischen Ausbildung
Maskenverwendung im Schulalltag: Fragen zum Umfang des Masketragens, Pausenregelungen sowie zur Schulung im richtigen Gebrauch der Masken
Einfluss der Masken auf das Kommunikationsverhalten: Fragen zu möglichen Auswirkungen des Masketragens auf das verbale, paraverbale und nonverbale Kommunikationsverhalten
Krankenstand: Fragen zu stimmlichen Beschwerden, Facharztbesuchen und Krankschreibungen
Die Umfrage war vom 21.05.2021 bis 21.06.2021 geöffnet und wurde beworben durch direkte Kontakte zu Schulen und Lehrkräften in verschiedenen Bundesländern sowie durch Mitarbeiter:innen des Zentrums für Lehrer:innenbildung und Schulforschung der Universität Leipzig.
4 Ergebnisse
4.1 Person und Ausbildung
Teilgenommen haben 499 Lehrkräfte aus 14 Bundesländern. Am häufigsten vertreten ist Sachsen (60,52 %), gefolgt von Nordrhein-Westfalen (12,42 %) und Niedersachsen (9,02 %). Nicht vertreten sind Rheinland-Pfalz und Bremen. 79 % der Teilnehmenden ordnen sich dem weiblichen Geschlecht, 21 % dem männlichen Geschlecht zu. Der deutlich höhere Anteil weiblicher Personen spiegelt nahezu die Realität in der Berufspraxis: Der Frauenanteil im Lehramt liegt bei ca. 73 % (vgl. Internetquelle 11).
Die Aufschlüsselung der absolvierten Berufsjahre zeigt eine relative Gleichverteilung von Berufsanfänger:innen über erfahrene Lehrer:innen bis hin zu gestandenen Lehrpersönlichkeiten, teils kurz vor dem Renteneintritt:

Die Auswertung der Angaben zur fachlich-pädagogischen Qualifikation zeigt, dass 15 % im Quer- bzw. Seiteneinstieg als Lehrkraft unterrichten und 85 % ein grundständiges Lehramtsstudium absolviert haben. Von den 499 befragten Lehrer:innen hatten knapp drei Viertel (73 %) im Rahmen ihres Lehramtsstudiums oder ihrer wissenschaftlichen Ausbildung als Lehrkräfte im Quer- oder Seiteneinstieg Sprecherziehung.
4.2 Maskenverwendung im Schulalltag
Von den 499 teilgenommenen Lehrkräften tragen 73 % FFP2-Masken und 26 % OP-Masken. 38 % haben eine Einführung in die hygienische Verwendung von Masken an ihrer Schule durch die Schulleitung und/oder das Bildungsministerium erhalten; d. h. 62 % erhielten keine Einführung. Nicht erfragt wurde, ob in der Einführung auch spezifische Hinweise zum sinnvollen Gebrauch der Maske hinsichtlich der Stimme und deren Gesunderhaltung sowie zur Atmung gegeben wurden.
Knapp die Hälfte (48 %) der Befragten tragen die medizinische Maske an einem durchschnittlichen Schultag 4 bis 6 Stunden am Tag, etwas weniger als ein Drittel (27 %) 2 bis 4 Stunden. 13 % der Befragten tragen die Maske bis maximal 2 Stunden, wiederum 13 % mehr als 6 Stunden.
73 % der Befragten geben an, dass sie im Schulalltag Pausen haben, in denen sie die Masken absetzen dürfen. Die Pausen finden in der Regel nach 45 oder 90 Minuten statt und haben zumeist eine Dauer von 5 bis 20 Minuten. In den folgenden exemplarischen Zitaten von Lehrkräften aus verschiedenen Bundesländern und Schulformen (es werden keine Anpassungen der Zitate hinsichtlich Orthografie und Interpunktion vorgenommen) wird neben der Beschreibung des Pausenumfangs deutlich, welche Beobachtungen die Lehrkräfte bzgl. der daraus resultierenden Belastung machen:
„In den Schulpausen ... 5–15 Minuten ... insgesamt meist 30–45 Minuten innerhalb von 7 Stunden. Aber nur, wenn ich an's Fenster gehe und keine Schüler da sind. Und wenn es überhaupt zeitlich machbar ist. Teils nur, wenn ich kurz esse oder trinke. Es müsste eigentlich ‚Zeit zum Atmen‘ geben, auch für Schüler. Die Kopfschmerzen und Belastungen sind immens!!!“ (Nordrhein-Westfalen, Berufskolleg)
„10–20 min 2x täglich eher ‚illegal‘ während der Aufsicht in den Hofpausen, in denen eigentlich Maskenpflicht ist …“ (Brandenburg, Sonder-/Förderschule)
„Nach max. 70 Minuten Unterricht ist eine 10-minütige Lüftungspause auf dem Schulhof für SchülerInnen und LehrerInnen Pflicht. In den regulären Pausen schaffe ich es als Lehrkraft jedoch kaum die Maske abzunehmen, da sich im Lehrerzimmer meist viele KollegInnen aufhalten.“ (Sachsen, Gymnasium)
Einige Befragte (7 %) geben an, dass es keine einheitlichen Regelungen gibt (bzw. Regelungen nicht eingehalten werden können) und Pausen dementsprechend sehr unregelmäßig sind (z. T. auch abhängig von den Aufgaben am jeweiligen Schul-/Arbeitstag):
„Es sind keine offiziellen Pause. Ich nehme sie ab, wenn ich auf Abstand bin oder am Platz hinter meiner Schutz’scheibe’.“ (Sachsen, Grundschule)
„Bei Hospitationsbesuchen im Rahmen meiner Tätigkeit als Fachausbildungsleiter nach ca. 2,5 Stunden erst. Ansonsten meist nach 2 bzw. 4 Stunden. Die vorgesehene Tragezeit und anschließende Pause kann ich so nicht einhalten.“ (Sachsen, Grundschule)
Fast ein Drittel der Befragten (27 %) gibt an, gar keine Pausen zu haben, und schildert Versuche, damit umzugehen:
„Am Fenster in Räumen (heimlich), ansonsten ist es mir legal nicht gestattet, ich müsste das Schulgelände verlassen.“ (Mecklenburg-Vorpommern, Gymnasium)
„Ich rücke mir ab und zu den Lehrertisch ganz nach hinten, setze mich und spreche ohne Maske, weil ich das Gefühl habe, dass mich die Schüler sonst nicht verstehen. Sobald ich aufstehe, ziehe ich die Maske auf. Ich nehme auch die Maske ab, wenn ich allein in einem Zimmer oder auf einem Gang bin. Einfach zum Durchatmen! Die Maskenpflicht belastet mich und meine Schüler sehr.“ (Sachsen, Oberschule)
11 % (vor allem entsprechend der Verordnung für Grundschulen in Sachsen) äußerten, dass im Unterrichtsraum keine Maskenpflicht herrscht und die Masken lediglich außerhalb des Unterrichts – auf den Gängen und in den Pausen – getragen werden müssen.
Auf die Frage, ob sich die Lehrer:innen bzgl. des Unterrichtens mit Maske eigeninitiativ weitergebildet haben, antworteten 9 % der Befragten mit „Ja”, die meisten davon im Internet.
4.3 Auswirkungen des Masketragens auf das Kommunikationsverhalten
Die befragten Lehrkräfte nehmen aufgrund des Masketragens deutliche Veränderungen im Kommunikationsverhalten wahr:
Unter Sonstiges haben die Lehrkräfte weitere individuelle Beobachtungen vermerkt. Insbesondere im Fremdsprachenunterricht ergeben sich zusätzliche Herausforderungen, wie diese Beispiele zeigen:

„Im Englischunterricht muss ich die Maske manchmal kurz abnehmen, damit die Kinder die richtige Aussprache verstehen.“ (Berlin, Grundschule)
„Mundstellung wird nicht gesehen von den Schüler*innen.“ (Niedersachsen, Oberschule)
Bezüglich der Verständlichkeit scheint ein weiterer Aspekt von Bedeutung: 15 Lehrkräfte schreiben explizit, dass sie ihre Schüler:innen schlechter verstehen, wenn eine Maske getragen wird; bei den Schüler:innen wiederum sei zu beobachten, dass sie bei mehreren im Raum anwesenden Personen nicht mehr wissen, wer gerade spricht. Zusätzlich werden negative Auswirkungen bzgl. der Klassenführung bzw. des Classroom-Managements (zur Begrifflichkeit stv. Dollase, 2012; Haag & Streber, 2012) formuliert:
„man verliert an Raumwirkung, d. h. die Kinder nehmen einen weniger wahr und lassen sich schlechter führen und leiten, alles entgleitet viel mehr. Hat normal die Präsenz im Raum genügt ist jetzt vieles ein Kraftakt (Disziplin, Struktur, Orga ...) Es ist furchtbar! Die Kinder verstehen mich kaum, ich verstehe die Kinder kaum.“ (Bayern, Grundschule)
Mehrfach wird die eingeschränkte nonverbale Kommunikation im Bereich der Mimik thematisiert und angedeutet, welche Versuche unternommen werden, um diese auszugleichen:
„Inhalte können schlechter vermittelt werden, weil die Mimik auf beiden Seiten fehlt.“ (Nordrhein-Westfalen, Gymnasium)
„Ich muss mich stärker auf die Augenpartie konzentrieren, um die nonverbalen Kommunikation wenigstens ein bisschen einbauen zu können.“ (Sachsen, Gymnasium)
Besondere Herausforderungen ergeben sich in inklusiven Settings – z. B. bei Schüler:innen mit Hörproblemen oder mit Migrationshintergrund, d. h. in Fällen, bei denen die Mimik zur Verständnissicherung besonders wichtig ist:
„Ich habe eine Schülerin mit Hörproblemen, da ist das Unterrichten mit Maske problematisch, da sie den Mund sehen muss, um etwas zu verstehen.“ (Nordrhein-Westfalen, Berufskolleg)
„Nonverbaler Aspekt bei der Verständigung fehlt besonders Schülern mit Migrationshintergrund.“ (Sachsen, Berufsschule)
Weitere Auswirkungen werden bezüglich des allgemeinen Gesprächsverhaltens beschrieben:
„ich vermeide Gespräche“ (Sachsen, Grundschule)
„Die SchülerInnen reden merklich weniger.“ (Sachsen, Gymnasium)
Vereinzelt werden sonstige physiologische Beschwerden und Herausforderungen genannt, bspw.:
„Maske festhalten beim Sprechen“ (Sachsen, Oberschule)
„Fasern in den Augen und im Hals – sehr unangenehm“ (Niedersachsen, Gymnasium)
„Ich habe öfter Kopfschmerzen.“ (Sachsen, Grundschule)
4.4 Auswirkungen des Masketragens auf subjektive Stimmbeschwerden
Seitdem es eine generelle Maskenpflicht gibt, nehmen 45 % der befragten Lehrkräfte Stimmbeschwerden bei sich wahr. Bezüglich der Beschwerdeart wurde auf einer sechsstufigen Skala zu vorgegebenen Kriterien geantwortet:


Fasst man die ersten drei Ausprägungen pro Item („A = trifft immer zu“, „B = trifft zu“ und „C = trifft eher zu“) als „zutreffend“ zusammen, zeigt sich folgende Häufigkeitsverteilung bzgl. vorhandener Stimmbeschwerden, in absteigender Reihenfolge:
86 % der befragten Lehrkräfte merken demnach eine schneller eintretende Stimmmüdigkeit, 78 % eine häufigere Heiserkeit, 75 % eine flache Atmung, 70 % einen Räusperzwang bzw. häufigeres Räuspern und 59 % Schmerzen in Kehlkopf/Rachen/Mund. Ein Blick auf die Geschlechterverteilung zeigt, dass Lehrer etwas weniger von Stimmbeschwerden betroffen sind (36 %) als Lehrerinnen (47 %), dennoch scheint es keine rein geschlechtsspezifische Thematik zu sein.
Ein möglicher Einfluss von (nicht vorhandener) sprecherzieherischer Ausbildung auf die Wahrnehmung von Stimmbeschwerden zeigt sich wie folgt: Diejenigen, die angaben, Sprecherziehung im Studium erhalten zu haben, nehmen zu 41 % Stimmbeschwerden bei sich wahr, die Gruppe ohne sprecherzieherische Ausbildung zu 56 %.
Zudem geben diejenigen, die Stimmbeschwerden wahrnehmen, im Vergleich zu jenen Befragten, die keine Stimmbeschwerden wahrnehmen, in Bezug auf Veränderungen im Kommunikationsverhalten (siehe Abschnitt 4.3) häufiger an, präziser zu artikulieren (89 % zu 75 %) und lauter sprechen zu müssen (96 % zu 81 %).
Um einen möglichen Einfluss der Tragezeiten von Masken auf Stimmbeschwerden zu eruieren, sollten die Lehrkräfte auf einer sechsstufigen Skala antworten (trifft nie zu – trifft nicht zu – trifft eher nicht zu – trifft eher zu – trifft zu – trifft immer zu). Die Ergebnisse zeigen, dass die Stimmbeschwerden zunehmen, je länger die Maske getragen wird:
Die Gruppe derjenigen, die mit der Aussage „trifft immer zu“ angibt, dass ihnen die Stimme wegbleibt, verdoppelt sich nahezu stetig in Abhängigkeit der zunehmenden Tragedauer.
3 % der Befragten gaben an, seit Beginn der Maskenpflicht bei einem Facharzt bzw. einer Fachärztin für HNO-Heilkunde oder Phoniatrie gewesen zu sein, 5 % der Befragten waren seit Beginn der Maskenpflicht aufgrund von Stimmbeschwerden krankgeschrieben.
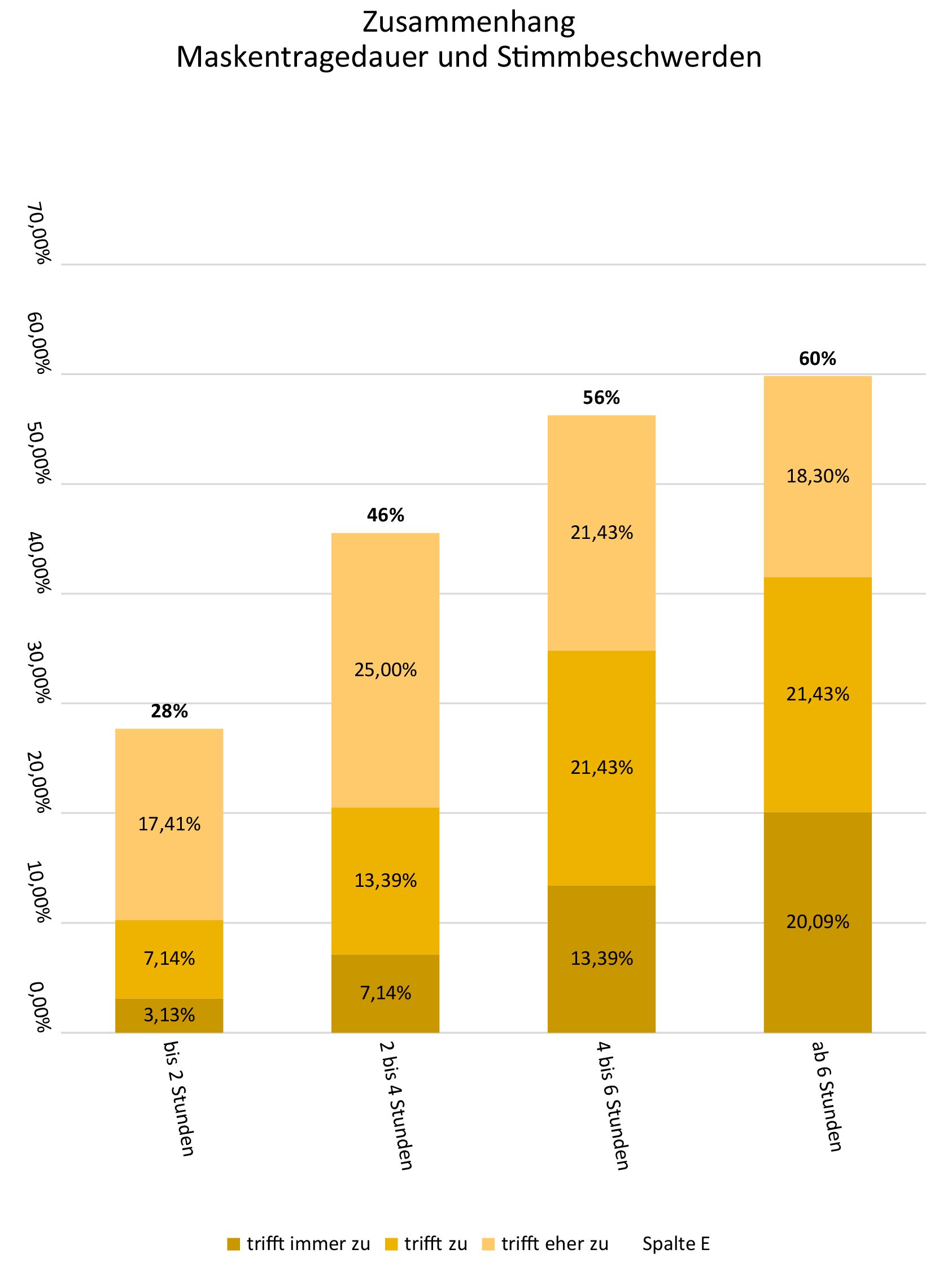
Im eingangs erfragten Stimmstatus zeigt sich, dass 5 % der Befragten eine akute Stimmerkrankung mit ärztlich diagnostiziertem Krankheitsbild (v. a. akute Laryngitis und funktionelle Dysphonie) aufweisen. Ebenfalls 5 % der Befragten geben an, dass sie akute Stimmbeschwerden mit Verdacht auf eine Stimmerkrankung haben (Stimme versagt öfters, Stimmmüdigkeit, Halsschmerzen, Heiserkeit) und beschreiben bspw. folgende Zustände:
„Heiserkeit, durch das sehr schlechte Atmen durch die Maske und das stundenlange Aufsetzen, wird meine Stimme rau und ich muss mich sehr oft räuspern und verspüre starkes Kratzen im Hals.“ (Nordrhein-Westfalen, Berufskolleg)
„seit Dezember 2020 totale bzw. teilweise Dysphonie“ (Sachsen, Grundschule)
„Es ist noch nichts diagnostiziert. Aber ich muss mich ständig räuspern, längeres zusammenhängendes Sprechen funktioniert nicht so wie früher und mir entgleitet die Stimme, wenn ich sie etwas mehr anstrengen muss, zB um kurz lauter zu sprechen. Deshalb werde ich morgen einen Arzt aufsuchen.“ (Sachsen-Anhalt, Gymnasium)
5 Diskussion
5.1 Zu den Teilnehmenden und deren sprecherzieherischer Ausbildung
In dem Wissen darum, dass die Umfrage eine Momentaufnahme darstellt, lassen sich die Ergebnisse der Befragung nicht pauschalisieren. Aufgrund der Freiwilligkeit wurden zudem möglicherweise insbesondere jene Lehrer:innen zur Teilnahme motiviert, die eher über Schwierigkeiten durch das Tragen einer Maske klagen, als diejenigen Lehrkräfte, denen das keine Probleme bereitet. Allerdings zeigt sich in der Verteilung der Umfrageteilnehmenden bzgl. des Alters, des Geschlechts, der Schulform etc. (siehe Abschnitt 4.1) ein durchaus repräsentativer Querschnitt, sodass dennoch klare Tendenzen sichtbar werden.
Etwa die Hälfte der befragten 499 Lehrkräfte nimmt Stimmbeschwerden durch das Masketragen wahr. Dabei lässt sich festhalten, dass es einen Unterschied zu machen scheint, ob die Befragten im Rahmen ihrer fachlich-pädagogischen Qualifikation Veranstaltungen zur Sprecherziehung besucht haben oder nicht: Die Zahl derer, die Stimmbeschwerden wahrnimmt, ist in der Gruppe ohne sprecherzieherische Ausbildung 15 % größer (56 % ohne sprecherzieherische Ausbildung zu 41 % mit sprecherzieherischer Ausbildung). Nichtsdestotrotz sind die Herausforderungen des Sprechens mit Maske für alle Lehrkräfte neu. Da davon auszugehen ist, dass das Masketragen aus Gründen des Infektionsschutzes noch länger erhalten bleiben wird, sollte in Sprecherziehungskursen mit (angehenden) Lehrer:innen das Tragen einer Maske im Schulkontext gesondert geübt und der Umgang damit reflektiert werden.
5.2 Zur Maskenverwendung im Schulalltag
Sofern sie nicht von der Maskenpflicht befreit sind, verwenden alle befragten Lehrkräfte OP-Masken (26 %) oder FFP2-Masken (73 %) im Schulalltag. Vor dem Hintergrund des Arbeitsschutzes gibt die DGUV für FFP2-Masken eine maximale Tragezeit von 75 Minuten und für OP-Masken eine maximale Tragezeit von 120 Minuten mit jeweils anschließender 30-minütiger Pause vor. Hier zeigt sich eine deutliche Diskrepanz zwischen Soll- und Ist-Zustand, da die Mehrheit der befragten Lehrkräfte angibt, erst nach 90 Minuten eine Maskenpause zu haben (siehe Abschnitt 2.1). Auch die vorgesehene Pausendauer wird in den seltensten Fällen realisiert, was vermutlich vor allem mit den Pausenregularien an Schulen zusammenhängt. Hier sollten die Verantwortlichen dringend nachbessern und klare Pausenregelungen vorschreiben, die dem Arbeitsschutz entsprechen. Dies bedeutet ggf. auch, die üblichen Regelungen zur Schulstunden- und Pausendauer außer Kraft zu setzen, um Lehrer:innen und Schüler:innen in dieser besonderen Situation zu entlasten und auch in stimmphysiologischer Hinsicht gesund zu erhalten.
Wie in Abschnitt 2.1 ausgeführt, ist es laut Bundesanstalt für Arbeitsschutz und Arbeitsmedizin notwendig, alle Lehrer:innen und Schüler:innen im Tragen von Masken zu unterweisen und auf mögliche Gefahren hinzuweisen (Internetquelle 2). Inwieweit diese Vorgabe an den Schulen umgesetzt wird, bleibt fraglich: Lediglich 38 % der Befragten geben an, eine Einweisung erhalten zu haben (siehe Abschnitt 4.2). Da weder die Form noch konkrete Aspekte der Einweisung explizit erfragt wurden, lässt sich keine Aussage darüber treffen, ob spezifische Hinweise zum sinnvollen Gebrauch der Maske gegeben wurden, die die Stimmgesundheit und Atmung betreffen. Aufgrund des stimmintensiven Berufs einer Lehrkraft sollte den Arbeitgebern die Wichtigkeit solcher berufsspezifischen Empfehlungen und Hinweise deutlich gemacht werden.
Die DGUV empfiehlt außerdem, dass der Arbeitgeber den Beschäftigten bei „der Nutzung einer FFP2-Maske oder einer vergleichbaren Atemschutzmaske [...] eine arbeitsmedizinische Vorsorge anzubieten [hat], wenn die Masken regelmäßig länger als 30 min pro Arbeitstag getragen werden“ (Internetquelle 3). Aus den Ergebnissen der Befragung lässt sich kein Hinweis darauf ableiten, dass die Lehrkräfte solch eine Vorsorge wahrgenommen hätten. Auch hier sollte ein entsprechendes Angebot (inkl. Berücksichtigung der Stimmprophylaxe) geschaffen bzw. die Teilnahme beworben werden.
Die Relevanz von Hinweisen zur Stimmprophylaxe zeigt sich bspw. in der Beobachtung, dass insbesondere die Kieferbewegung beim Sprechen dazu führt, dass die Masken verrutschen; befragte Lehrer:innen schildern, dass sie sich immer wieder während der Kommunikation an die Maske fassen müssen, um die Maske zu richten (siehe Abschnitt 4.3). Eine Möglichkeit, dies zu vermeiden, ist es, die Kieferbewegungen zu reduzieren (die, am Rande bemerkt, bei vielen Personen ohnehin zumeist recht klein ausfallen). Dies wirkt sich wiederum negativ auf die Spannungsverhältnisse im Mundbereich aus, wodurch auch die Stimme und die Artikulation beeinträchtigt werden können und damit das stimmliche Wohlbefinden und die Verständlichkeit.
Abschließend ist anzumerken, dass es bislang keine wissenschaftlichen Studien gibt, die das Thema Masketragen im schulischen Kontext in den Mittelpunkt stellen. Demzufolge fehlen Belege, um abzuwägen, wie unterschiedliche Aspekte in Einklang gebracht werden können: wirkungsvoller Infektionsschutz einerseits und Schutz vor weiteren möglichen gesundheitlichen Gefahren (Stimme, Atmung etc.) für Lehrer:innen und Schüler:innen sowie mögliche Beeinträchtigungen in der Unterrichtskommunikation (Verständnissicherung, Konzentration, Emotionsdeutung etc.) andererseits. Solche Studien könnten bei einer Gefährdungsbeurteilung von hohem Nutzen sein und ggf. Orientierung bieten, bspw. bei der Frage, ob der Einsatz von Raumluftfiltern und/oder CO2-Ampeln für bedarfsgesteuertes Lüften präferiert werden sollte, anstatt dauerhaft Masken zu tragen. Gleichzeitig ist bei solchen Überlegungen wiederum im Blick zu behalten, welche neuen Gegebenheiten sich dadurch einstellen (z. B. eine veränderte Luftqualität durch Feuchtigkeitsentzug), auf die bzgl. der Stimmhygiene ebenfalls reagiert werden muss (z. B. Handreichungen an Lehrkräfte bzgl. ausreichender Lüftung, Feuchthalten der Schleimhäute etc.).
5.3 Zu den Auswirkungen auf das Kommunikationsverhalten
Fast alle befragten Lehrkräfte geben an, dass sie mit der Maske lauter sprechen müssen. Wird über einen langen Zeitraum unphysiologisch laut gesprochen, steigt die Gefahr, funktionelle und organische Stimmerkrankungen zu entwickeln. Neben weiteren wissenschaftlichen Untersuchungen dieser Problematik sollte daher ein besonderes Augenmerk auf die stimmliche Ausbildung und das regelmäßige Training gelegt werden. Zusätzlich sind methodische Formen in den Unterrichtsverlauf zu integrieren, die ohne stimmliche Präsenz der Lehrkraft auskommen.
Außerdem zeigen die Ergebnisse der Befragung deutliche Auswirkungen des Masketragens auf das allgemeine schulische Gesprächsverhalten. Aussagen wie „Ich vermeide Gespräche“ oder „Schüler:innen reden merklich weniger“ (siehe Abschnitt 4.3) sind als äußerst bedenklich zu werten, da sie kontraproduktiv für gelingende Lehr-Lern-Situationen sind (stv. Meyer, 2020, S. 67 ff.).
Bereits im „normalen“ Regelunterricht ist es nötig, dass für „Schülerinnen und Schüler, für die die Unterrichtssprache eine Fremdsprache ist oder die unter einer Aufmerksamkeitsstörung leiden, [...] die verbal übermittelte Information zu 100 Prozent“ (Schönwälder et al., 2004, S. 116) zu verstehen ist. Dabei sollen „Lehrkräfte [...] sich verständlich machen können, ohne die Stimme stark anheben zu müssen“ (ebd.). Wird nun aber die Sprechlautstärke durch die Maske gedämpft und fällt die Mimik als wichtiges Kommunikationsmittel zum großen Teil weg, werden vor allem Schüler:innen mit inklusiven Lehr-Lern-Bedürfnissen und/oder Migrationshintergrund stärker benachteiligt.
Auch an Grundschulen ist die Mimik der Lehrer:innen ein entscheidendes Kriterium für gelingende Lehr-Lern-Situationen. Kinder erlernen nicht nur das Schreiben und Lesen in der Grundschule, sondern auch die Deutung von Emotionen. Damit dies gelingen kann, müssen Kinder das gesamte Gesicht einer Lehrerin bzw. eines Lehrers sehen können.
Besondere Herausforderungen ergeben sich sowohl für den Fremdsprachenunterricht als auch für weitere Fächer wie Darstellendes Spiel und Musik. Besonders in diesen Fächern sind Lehrkräfte und Schüler:innen darauf angewiesen, dass sie alle zwischenmenschlichen Kommunikationsmittel gezielt einsetzen können. Auch der Sportunterricht verlangt ein hohes Maß an stimmlicher und körperlicher Präsenz, um den Unterricht strukturiert gestalten zu können.
Um den spezifischen Lehr-Lern-Bedürfnissen in bestimmten Schularten oder Fächern gerecht zu werden, sollten Infektionsschutzkonzepte geprüft und entwickelt werden, die nicht ausschließlich auf das Tragen von Masken angewiesen sind.
5.4 Zu Auswirkungen des Masketragens auf subjektive Stimmbeschwerden
Neben den Symptomen Stimmmüdigkeit, Heiserkeit, Räusperzwang und Kehlkopf-Schmerzen wird von 75 % der Befragten, die Stimmbeschwerden wahrnehmen, eine flache Atmung als weiteres Symptom genannt. Heider et al. (2020) stellen diesbezüglich eine Hypothese auf. Sie vermuten, dass durch das Tragen einer Maske die Stimmproduktion beeinflusst wird, indem sie die phonorespiratorische Koordination der/des Maske Tragenden verändert. Studien zur Aerodynamik von Gesichtsmasken hätten gezeigt, dass es während der Einatmung zu einem Druckabfall unter den Masken kommt, was eine größere Anstrengung des Trägers beim Einatmen erfordert (ebd., pp. E 1232). Dies könnte eine Erklärung für die wahrgenommene flache Atmung seitens der befragten Lehrkräfte sein.
Des Weiteren zeigen die Befragungsergebnisse sehr deutlich die Auswirkungen eines durchaus naheliegenden Zusammenhangs: Je länger die Maske am Stück getragen wird, desto drastischer steigt die Wahrscheinlichkeit, dass den Lehrer:innen die Stimme wegbleibt.
45 % der 499 Befragten geben an, seit dem Tragen der Masken stimmliche Beschwerden wahrzunehmen (siehe Abschnitt 4.4). Von dieser Gruppe äußern 28 %, dass ihnen nach maximal 2 Stunden Tragedauer die Stimme wegbricht; nach 2 bis 4 Stunden ist die Zahl um 18 Prozentpunkte auf 46 % deutlich gestiegen. Dies lässt sich als Indikator dafür werten, dass die Tragedauer tatsächlich in jenen Grenzen gehalten werden sollte, die von der DGUV empfohlen wurden, also 2 Stunden ohne die Einhaltung von Pausenzeiten nicht übersteigen sollte (siehe Abschnitt 2.1).
13 % der Befragten tragen die Masken mehr als 6 Stunden (s. Abschnitt 4.2) und ebenso 13 % der Befragten geben an, dass ihnen spätestens ab einer Tragedauer von 6 Stunden die Stimme versagt. Es wäre zu vermuten, dass es sich um dieselben 13 % handelt, jedoch korrelieren diese Ergebnisse nur teilweise.
Diejenigen Befragten, die Stimmbeschwerden wahrnehmen, geben im Vergleich zu jenen Befragten, die keine Stimmbeschwerden wahrnehmen, in Bezug auf Veränderungen im Kommunikationsverhalten (siehe Abschnitt 4.4) häufiger an, präziser zu artikulieren (89 % zu 75 %) und lauter sprechen zu müssen (96 % zu 81 %). Es zeigt sich gewissermaßen ein Teufelskreis, da dauerhaft (zu) lautes Sprechen verstärkt zu Stimmproblemen führen kann – erst recht, wenn die Betroffenen über keine professionelle Sprech- und Kommunikationsweise verfügen (Einsatz der Kraftstimme, präzise Artikulation zur Entlastung der Stimme, Verwendung nonverbaler Mittel etc.).
Nicht eruiert wurde, ob die Befragten auch schon vor dem Tragen der Masken Stimmprobleme hatten. Anzumerken ist außerdem, dass in der Untersuchung keine Kontrollgruppe erhoben wurde, da zum Zeitpunkt der Befragung fast überall Maskenpflicht herrschte. Vergleicht man jedoch die Ergebnisse mit Studien aus Zeiten vor der Pandemie, zeigt sich folgendes Bild:
Untersuchungen von Lemke (2012, 2006) zeigen, dass bereits zwischen 37,4 % und 40 % der Lehramtsstudierenden Stimmauffälligkeiten haben, davon 16,8 % hinsichtlich des Stimmklangs. Gutenberg und Pietsch (2003) stellten 43,82 % auffällige Stimmen fest, wobei das nur bei 32 % letztlich bestätigt wurde.
Für Lehrer:innen im Vorbereitungsdienst nennt Schiller (2017) einen ähnlich hohen Prozentsatz von 37 %. Besonders häufig sind dabei die Symptome Rauigkeit, Räusperzwang oder Lautstärkeprobleme.
Für Lehrkräfte im Beruf geben Nusseck et al. (2019) an, dass 58 % im Laufe der Berufszeit schon einmal ein Stimmproblem erlebt haben. Amerikanische und belgische Untersuchungen von Smith et al. (1997), Roy et al. (2004), van Houtte et al. (2011) und Hunter und Banks (2017) zeigen, dass die Prävalenz von Stimmbeschwerden in der Berufsgruppe der Lehrkräfte im Vergleich zu Nicht-Lehrkräften generell höher ist.
Die Studien zeigen insgesamt ein vielfältiges Bild. Gleichzeitig ist anzumerken, dass nicht immer die gleichen Parameter (Beschwerdeart, -anzahl etc.) untersucht wurden, sodass ein Vergleich sicherlich nur bedingt zulässig ist. In der vorliegenden Untersuchung, bei der knapp die Hälfte der Befragten (45 %) subjektive Stimmprobleme seit Einführung der Maskenpflicht in den Schulen wahrnehmen, lässt sich teilweise eine Erhöhung der Stimmprobleme im Vergleich zu den hier genannten Studien feststellen: Ein Fünftel bis ein Drittel der deutschen Lehramtsstudierenden hat Auffälligkeiten im Bereich des Stimmklangs, bei mehr als einem Drittel der Lehrer:innen im Vorbereitungsdienst liegen Stimmerkrankungen vor. Mehr als die Hälfte der deutschen Lehrkräfte im Beruf hat irgendwann im Laufe des Berufslebens subjektiv wahrgenommene und/oder diagnostizierte Stimmprobleme. Das wiederum ist eine höhere Zahl als in der vorliegenden Befragung, wobei anzumerken ist, dass ein anderer Analysezeitraum fokussiert wurde (ein Jahr versus viele Berufsjahre).
Im Unterschied zur vorliegenden Arbeit handelt es sich bei einem Großteil dieser Studien um diagnostische Untersuchungen und nicht um eine individuelle Selbsteinschätzung. Daher ist nicht auszuschließen, dass bei diagnostischer Untersuchung der befragten Lehrkräfte ein noch höherer Prozentsatz an stimmlichen Auffälligkeiten und Erkrankungen zu beobachten wäre. Bestärkt wird diese Vermutung durch das Untersuchungsergebnis, dass lediglich 3 % der Befragten aufgrund ihrer akuten Stimmprobleme eine fachärztliche Einrichtung aufgesucht haben. Dies ist in der praktischen Arbeit mit Lehrkräften ein vertrautes Bild. Beobachtungen zeigen, dass dies häufig aus der Annahme resultiert, dass „die Stimme ja nicht veränderbar sei“. Umso wichtiger ist es, sowohl im Lehramtsstudium als auch im Vorbereitungsdienst und im Beruf einen stärkeren Fokus darauf zu richten, dass Stimme veränderbar ist und an ihr gearbeitet werden kann (und für diesen sprechintensiven Beruf auch muss).
Außerdem zeigt der Blick auf die Studien, dass es länderabhängige Unterschiede gibt. Zu vermuten wäre, dass dies u. a. an den unterschiedlichen Sprachen und den damit einhergehenden stimmlich-artikulatorischen Besonderheiten liegt (z. B. Artikulationsbasis).
Abschließend möchten wir darauf verweisen, dass die psychischen Belastungen für Lehrkräfte durch die Pandemie als sehr hoch angenommen werden können (Internetquelle 12 und 13) und das Masketragen ggf. „nur noch“ ein zusätzlicher belastender Faktor ist. Wenn die Belastungen der Lehrer:innen hoch sind, nehmen auch Stimmbeschwerden zu (Hammann, 2004, S. 171). Daher wäre es im Sinne einer gesundheitlichen Prävention und Entlastung von Lehrkräften wünschenswert, die verordneten Infektionsschutzmaßnahmen situationsbedingt und unter Berücksichtigung neuer wissenschaftlicher Erkenntnisse immer wieder abzuwägen.
6 Fazit und Handlungsempfehlungen
Die Befragungen zum Ist-Zustand zeigen, dass das Tragen einer Maske für viele Lehrkräfte zu erheblichen subjektiven Stimmbeschwerden und kommunikativen Einschränkungen im Schulalltag führt. 45 % der befragten Lehrkräfte nehmen Stimmbeschwerden bei sich wahr; Symptome wie Stimmmüdigkeit, Heiserkeit, flache Atmung und Räusperzwang werden am häufigsten genannt. Zudem geben die Befragten an, lauter sprechen und deutlicher artikulieren zu müssen sowie Äußerungen häufiger zu wiederholen. Auch wenn die Maskenpflicht an Schulen phasenweise in vielen Bundesländern zurückgefahren und zwischenzeitlich sogar ganz aufgehoben wurde (z. B. Sachsen: Maskenpflicht bei Inzidenz unter 35 an Schule aufgehoben, Internetquelle 14), sind evidenzbasierte Handlungsanleitungen für ähnliche Szenarien in der Zukunft dringend nötig. Nur so können zunehmende stimmliche Erkrankungen bei Lehrer:innen und Lernschwierigkeiten bei Schüler:innen minimiert werden.
Anliegen der Autorinnen ist es, Stimmfachärzt:innen und Sprechwissenschaftler:innen zu motivieren, diesem Thema in weiterführenden Untersuchungen die nötige Aufmerksamkeit zu schenken. Auch die praktische Sprecherziehung an den Universitäten sollte sich mit diesen neuen Herausforderungen auseinandersetzen und Konzepte zur Stimmgesundheit in pandemischen Zeiten entwickeln. Den Autorinnen geht es nicht darum, die Masken an sich abzuschaffen, sondern alle Handlungsoptionen situationsbedingt unter Berücksichtigung des Infektionsschutzes im Blick zu behalten. Nicht zuletzt sollen auf Basis der Ergebnisse Entscheidungsträger:innen in Schulbehörden Argumentations- und Gestaltungsgrundlagen angeboten werden.
Folgende Handlungsempfehlungen für die Bildungsministerien der Länder, die Schulämter und die Schulen ergeben sich aus den Ergebnissen der Umfrage:
Zum Schutzstandard an Schulen sollte auch der Schutz der Stimme zählen. Diesbezüglich sollten Regularien und Handreichungen zur Stimmhygiene entwickelt werden. Es ist unerlässlich, Lehrkräften eine arbeitsmedizinische Vorsorge zum Thema Masketragen anzubieten und sie auf diese Möglichkeit gezielt hinzuweisen.
Es muss klare Regularien in Bezug auf Maskenart, Tragedauer und Maskenpausen geben. Diese sind auf Basis der DGUV-Empfehlungen zu erarbeiten und den Lehrer:innen und Schüler:innen klar zu kommunizieren. Hierfür sollten auch die Länge von Unterrichtseinheiten angepasst sowie neue Pausenzeiten etabliert werden, um die empfohlene Maskentragedauer der DGUV einzuhalten. (Dauerhaftes) Masketragen als personenbezogene Maßnahme sollte erst dann verordnet werden, wenn alle anderen Maßnahmen im Sinne des TOP-Prinzips, d. h. zuerst technische (T), dann organisatorische (O) und zuletzt personenbezogene (P) Maßnahmen, bereits ausgeschöpft wurden. Darüber hinaus sollte überprüft werden, ob Lehrer:innen situationsabhängig auf einfache OP-Masken zurückgreifen können.
Für bestimmte Fächer (Sprachen, Musik, Sport, darstellendes Spiel), für bestimmte Schulformen (Grundschulen, Förderschulen) und für bestimmte Lehr-Lern-Bedürfnisse (Inklusionsklassen, Schüler:innen mit Migrationshintergrund) sollte – wie es in manchen Bundesländern auch schon stattfindet – eruiert werden, welche Möglichkeiten des Infektionsschutzes im Sinne des TOP-Prinzips angewendet werden können, die es erlauben, die Maskenpflicht situationsabhängig aufzuheben und in eine Empfehlung zum Tragen einer Maske umzuwandeln.
Konkrete Schulungsmaßnahmen zum Unterrichten mit Masken sind notwendig und sinnvoll. Darüber hinaus sollten Alternativen bzgl. des Classroom-Managements etabliert werden, z. B. ein Wechsel der Methoden hin zu mehr Kleingruppen- und Einzelarbeit, Strategien zur Aufmerksamkeitssteuerung im Unterricht ohne Stimme oder die Einrichtung und Nutzung von Mikrofonanlagen, um die Stimme zu entlasten.
Sprecherziehung, d. h. ein professionelles Training der Stimme und der Funktionskreise des Sprechens (Körperhaltung, Atmung, Phonation und Artikulation) ist (nicht zuletzt unter diesen besonderen Bedingungen) enorm wichtig für die Stimmprophylaxe und dauerhafte Stimmgesundheit von Lehrkräften und damit ein unerlässlicher Bestandteil sowohl des Studiums als auch berufsbegleitender Fort- und Weiterbildungen!
Literatur
Dollase, R. (2012). Classroom Management. Theorie und Praxis des Umgangs mit Heterogenität. Oldenbourg.
Föcking, W. & Parrino, M. (2015). Praxis der funktionalen Stimmtherapie. Springer.
Gutenberg, N. & Pietsch, Th. (2003). Pilotstudie zur Karriere von Lehrerstimmen mit stimmpathologischem Befund bzw. Prognose eines stimmpathologischen Risikos unter Unterrichtsbelastung: Zwischenergebnisse. In L.-Chr. Anders, & U. Hirschfeld (Hrsg.), Sprechsprachliche Kommunikation. Probleme, Konflikte, Störungen (S. 111-120). Peter Lang.
Haag, L. & Streber, D. (2012). Klassenführung. Erfolgreich unterrichten mit Classroom Management. Beltz.
Habermann, G. (2003). Stimme und Sprache. Eine Einführung in ihre Physiologie und Hygiene. Für Ärzte, Sänger, Pädagogen und alle Sprechberufe. Thieme.
Hammann, C. (2004). Die Lehrerstimme im Ausbildungsnotstand: Problemevaluation und Lösungsdiskussion. In S. Zimmermann, C. Iven, & V. Maihack (Hrsg.), Hauptsache Stimme! – Neues aus Praxis und Forschung zur Diagnostik und Therapie von Stimmstörungen (S. 161-202). ProLog.
Heider, C. A., Álavarez, M. L., Fuentes-López, E., González, C. A., Leó, N. I., Verástegui, D. C., Badía, P. I. & Napolitano, P. A. (2020). Prevalence of Voice Disorders in Healthcare Workers in the Universal Masking COVID-19 Era. The Laryngoscope, 131(4), E1227–E1233. https://doi.org/10.1002/lary.29172
Hunter, E. J. & Banks, R. E. (2017). Gender Differences in the Reporting of Vocal Fatigue in Teachers as Quantified by the Vocal Fatigue Index. Annals of Otology, Rhinology & Laryngology, 126(12), 813–818. https://doi.org/10.1177/0003489417738788
Knuth, M. (2018). Was macht die Stimme laut und belastbar? Ansätze zur Schulung der Sprechstimme und der Behandlung von funktionellen Dysphonien. Forum Logopädie, 32(6), 18-22.
Krause, A., Dorsemagen, C. & Baeriswyl, S. (2013). Zur Arbeitssituation von Lehrerinnen und Lehrern. Ein Einstieg in die Lehrerbelastungs- und -gesundheitsforschung. In: M. Rothland (Hrsg.), Belastung und Beanspruchung im Lehrerberuf. Modelle, Befunde, Interventionen (S. 61-80). Verlag für Sozialwissenschaften.
Lemke, S. (2012). Stimmintensiver Beruf Lehrer/in: Voraussetzungen – Ausbildungsbedingungen – Projekte. In M. Gaul, & S. Lang (Hrsg.), Voice Coaching. Zum richtigen Umgang mit der Stimme im Lehrberuf (S. 100–113). Schneider Verlag Hohengehren GmbH.
Lemke, S. (2006). Die Funktionskreise Respiration, Phonation, Artikulation – Auffälligkeiten bei Lehramtsstudierenden. Sprache – Stimme – Gehör, 30(1), 24–28.
Meyer, H. (2020). Was ist guter Unterricht?. Cornelsen.
Nollmeyer, O. (2010). Die souveräne Stimme. Gabal Verlag GmbH.
Nollmeyer, O. (2014). Stimmliche Tragfähigkeit und das interaktive Sonagramm. Forum Logopädie, 4/28, 12–17. http://www.stimme-koerper-klang.de/Tragfahigkeit_VVE. pdf
Nusseck, M., Immerz, A., Trischler, F., Richter, B. & Spahn, C. (2019). Stimmprobleme bei Lehrkräften in Zusammenhang mit beruflichen und außerberuflichen Aspekten. In T., Leuders, E. Christophel, M. Hemmer, F. Korneck & P. Labudde (Hrsg.), Fachdidaktische Forschung zur Lehrerbildung (S. 171–182). Waxmann.
Pörschmann, C., Lübeck, T. & Arend, J. M. (2020). Impact of face masks on voice radiation. The Journal of the Acoustical Society in America, 148(3663). https://doi.org/10.1121/10.0002853
Roy, N., Merill, R. M., Thibeault, S., Parsa, R. A., Gray, S. D. & Smith, E. M. (2004). Prevalence of voice disorders in teachers and the general population. Journal of speech, language, and hearing research, 47(2), 281-293. https://pubs.asha.org/doi/10.1044/1092-4388%282004/023%29
Schiller, I. S. (2017). Stimmstörungen bei Lehrkräften im Vorbereitungsdienst. In K. Hannken-Illjes, K. Franz, E.-M. Gauss, F. Könitz & Marx, S. (Hrsg.), Stimme – Medien –Sprechkunst. (S. 269-277). Schneider Verlag Hohengehren GmbH.
Schönwälder, H.-G., Berndt, J., Ströver, F. & Tiesler, G. (2004). Lärm in Bildungsstätten – Ursachen und Minderung. Verlag für neue Wissenschaft GmbH. https://www.arbeitsschutz-schulen-nds.de/fileadmin/Dateien/Uebergreifende_Themen/Laerm/Dokumente/Fb1030_lang.pdf
Smith, E., Gray, S. D., Dove, H., Kirchner, L., & Heras, H. (1997). Frequency and effects of teachers’ voice problems. Journal of voice, 11(1), 81–87. https://www.jvoice.org/article/S0892-1997(97)80027-6/pdf
Tropper, H. & Schlömicher-Thier, J. (2011). Die Berufsstimme am Stimmarbeitsplatz Schule. Das Stimmbetreuungsprojekt der Pädagogischen Hochschule Salzburg. Pädagogische Hochschule Salzburg, Beiträge aus Wissenschaft und Lehre, 04, 43–49. https://www.wevosys.de/wissen/_data_wissen/81.pdf
Van Houtte, E., Claeys, S., Wuyts, F. & Van Lierde, K. (2011). The impact of voice disorders among teachers: vocal complaints, treatment-seeking behavior, knowledge of vocal care, and voice-related absenteeism. Journal of voice, 25(5), 570-575. https://www.jvoice.org/article/S0892-1997(10)00077-9/fulltext
Wendler, J. & Seidner, W. (1997). Die Sängerstimme. Henschel.
Wendler, J., Seidner, W. & Eysholdt, U. (2005). Lehrbuch der Phoniatrie und Pädaudiologie. Thieme.
Internetquellen
(Zugriff: 27.08.2021):
[1] https://www.bgw-online.de/bgw-online-de/faq/wie-lange-sollen-medizinische-gesichtsmasken-und-44240
[2] https://www.bmas.de/SharedDocs/Downloads/DE/Gesetze/neufassung-sars-cov-2-arbeitsschutzverordnung.pdf?__blob=publicationFile&v=1
[3] https://www.dguv.de/corona-bildung/schulen/faq/index.jsp
[4] https://www.dguv.de/medien/inhalt/praevention/themen_a_z/biologisch/kobas/tragezeitbegrenzung_kobas_27_05_2020n1.pdf
[5] https://www.bfarm.de/SharedDocs/Risikoinformationen/Medizinprodukte/DE/schutzmasken.html
[6] https://publikationen.dguv.de/widgets/pdf/download/article/1011
[7] https://www.baua.de/DE/Aufgaben/Geschaeftsfuehrung-von-Ausschuessen/AfAMed/pdf/Stellungnahme-Tragezeit-FFP2-Masken.pdf?__blob=publicationFile&v=3
[8] https://www.br.de/nachrichten/wissen/maskenpflicht-an-schulen-das-gilt-jetzt-inbayern,SUXxeVy
[9] https://www.sueddeutsche.de/bayern/bayern-schulen-maskenpflicht-lockerung-1.5321310
[10] https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&-ved=2ahUKEwiDrJymmMnyAhVH3aQKHX9fCn0QFnoECAIQAQ&url=https%3A%2F%2Fwww.mk.niedersachsen.de%2Fdownload%2F167064%2FSchutzmasken_gegen_Corona_in_der_Schule.pdf&usg=AOvVaw3xii_0rxtsUBqekcOaP-w3
[11] https://de.statista.com/statistik/daten/studie/1129852/umfrage/frauenanteil-unter-den-lehrkraeften-in-deutschland-nach-schulart/
[12] https://publikationen.dguv.de/widgets/pdf/download/article/3850
[13] https://publikationen.dguv.de/widgets/pdf/download/article/3901
[14] https://www.coronavirus.sachsen.de/eltern-lehrkraefte-erzieher-schueler-4144.html
Autorinnen

© Marit Fiedler
Marit Fiedler
Dr. phil. Marit Fiedler studierte Sprechwissenschaft an der Martin-Luther-Universität Halle-Wittenberg. Als freiberufliche Dozentin unterrichtet sie an der HMT Rostock im Lehramt Theater, der Universität Rostock im Bereich Hochschuldidaktik, Grundschulpädagogik und am Zentrum für Lehrerbildung und Bildungsforschung. Darüber hinaus gibt sie Workshops und Einzeltrainings an Hochschulen, für Kirche und Ehrenamt, in Medien und Wirtschaft. Von 2017 bis 2020 leitete sie die GeschichtenWerkstatt im Kirchenkreis Mecklenburg. Ihre Arbeits- und Forschungsschwerpunkte sind Stimme, Phonetik und Erzählen.
Arbeitsort: Rostock
E-Mail: marit.fiedler@hmt-rostock.de
Postanschrift: Poststraße 50
18246 Baumgarten

© Clara Luise Finke
Clara Luise Finke
Dr. phil. Clara Luise Finke studierte Sprechwissenschaft an der Martin-Luther-Universität Halle-Wittenberg (MLU). Seit 2019 leitet sie den Bereich Sprechwissenschaft am Zentrum für Lehrer:innenbildung und Schulforschung der Universität Leipzig und verantwortet das Modul „Körper – Stimme – Kommunikation“. Zuvor war sie am Zentrum für Lehrer*innenbildung der MLU tätig sowie als freie Trainerin u. a. in den Feldern Medien und Schule. Ihre Arbeits- und Forschungsschwerpunkte sind Kommunikation und Stimme in Pädagogik und Andragogik sowie Gesprächsforschung im sprach- und sprechwissenschaftlichen Kontext.
Arbeitsort: Leipzig
E-Mail: clara.finke@uni-leipzig.de
Postanschrift: Universität Leipzig
Zentrum für Lehrer:innenbildung und Schulforschung (ZLS)
Prager Str. 38-40
04317 Leipzig
Kontakt
„Sprechen & Kommunikation – Zeitschrift für Sprechwissenschaft“ wird herausgegeben von der Deutschen Gesellschaft für Sprechwissenschaft und Sprecherziehung e. V.
Erschienen am: 23.09.2022